
文章目录
对比
指标wav2vecwav2vec 2.0HuBertmask方式没有mask encoder送给transformer的输入mask encoder送给transformer的输入mask长度encoder上的若干连续step, step=10step=10step=10改进点base引入量化改善量化的位置&kmeans迭代聚类损失函数二值对比损失对比损失+多样性损失对比损失量化无量化encoder的输出量化transformer的输出以及中间层
Wav2Vec: Unsupervised pre-training for speech recognition
- Facebook AI
- code
- 2019 interspeech
abstract
- 使用大量无标签数据做无监督预训练,学到语音的高维表征用于语音识别
- 模型:多层CNN降采样得到z,文本编码器得到L,使用过去帧预测当前帧。
- 结论:用pre-trained wav2vec的特征代替fbank-mel,labeled data越少,wav2vec相比baseline带来的提升就越多。
method

z
=
e
n
c
o
d
e
r
n
e
t
w
o
r
k
(
X
)
z = encoder network (X)
z=encodernetwork(X)
c
=
c
o
n
t
e
x
t
n
e
t
w
o
r
k
(
z
i
,
.
.
.
,
z
i
−
u
)
c = context network(z_i, ..., z_{i-u})
c=contextnetwork(zi,...,zi−u)
- 每个z编码了10ms的信息;context network输入多个z,感知野210ms;
- 训练一个wav2vec large模型,context network的感知野更大,810ms;
- 对样本在feature and temporal维度进行归一化,归一化的机制非常重要(对于输入的缩放和偏移是不变的),因而可以在更大的数据集良好泛化。
- noise contrastive binary classification task。
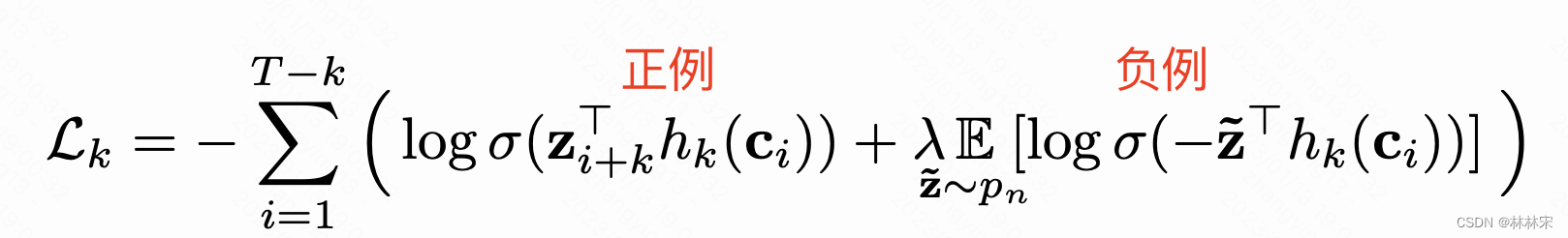

z i + k z_{i+k} zi+k是此后k step的特征,负例是从随机分布中采样的干扰(如果从其他序列或者其他说话人采负样,结果会变差)- 将得到的 c i c_i ci代替原有的mel fbank输入识别网络。
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
- 2020 NIPS
- Facebook AI
- 参考讲解结合代码
abstract
- 无标签数据通过自监督学习预训练ASR模型,然后少量数据finetune,可以超越当前最好的半监督模型。
- LM的训练方法+对比学习:wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned.
- 量化编码
introduction
- 在对比任务中,通过gumbel softmax学习discrete speech units,代表隐层特征,相比于非量化的特征更有效。
- 预训练之后,使用标签数据+CTC Loss进行finetune,应用于下游的ASR任务。
- 之前使用数据量化的方法一般分为两个阶段:数据量化,然后使用slf-attn建模语义信息。本文使用一种end2end的方式,实验证明达到更好的效果。而且在10min数据finetune,WER 4.8/8.2 ON clean/other test set of LibriSpeech
method
MODEL arch
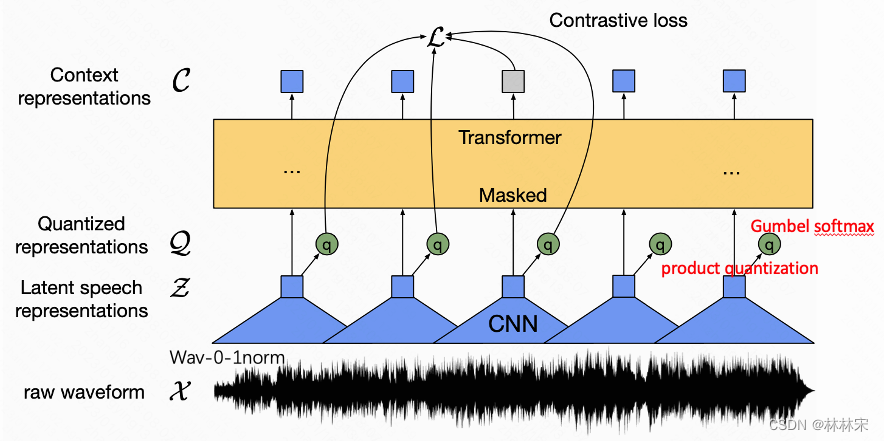
- Feature encoder:多层CNN,对waveform降采样,得到z;
- Contextualized representations with Transformers:输入z,建模语义信息,输出c;
- Quantization module:对z进行量化编码,使用Gumbel softmax优化码本训练;G个码本,每个码本有V条(多个码本分的更细,减少量化误差?)
损失函数
- 损失函数分为两部分,对比损失+diversity loss
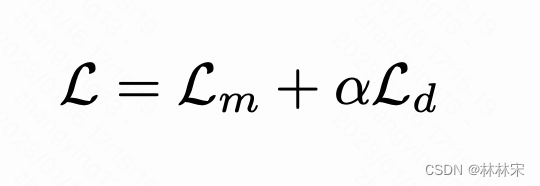

- 对比损失: $z_t$mask掉,预测的$c_t$和量化的结果$q_t$计算距离;负样本$q^~}$来自干扰器(同一句话中其他masked step的正态采样)
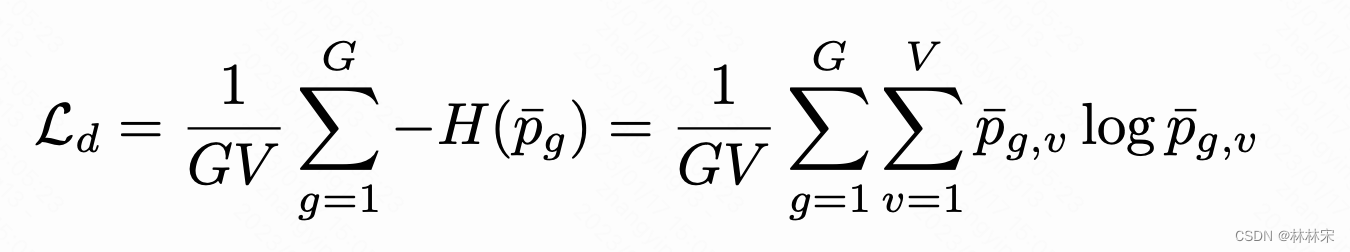
- 多样性损失:训练码本量化过程。损失函数$L_d$,最大化概率分布
finetune
- pre-train完成以后,把linear projection替换成softmax层,将 C C C进行分类,使用CTC Loss约束。参考了SpecAugment的实现,并在训练过程中添加time-step和channel的mask,显著延迟过拟合并提升准确率。
expriment
- 训练数据:Librispeech 960h [24] or the Libri-Light 60k hours
HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Unit
- 2021 TASLP期刊
- Wei-Ning Hsu
- code and example
- hubert知乎
abstract
- 自监督学习训练ASR,可以达到wav2vec 2.0类似甚至更好的效果。
- 自监督学习的缺点在于没有标签,有点也是。因为标签表明文本内容,说话人等,都是相对单一的,会限制模型的表征学习,而自监督学习不受其影响,因此可以获得更好的泛化特性。
intro
- 自监督的语音表示学习有三个难点:(1)语音中存在多个unit;(2)训练的时候和NLP不同,没有离散的单词或字符输入;(3)每个unit都有不同的长度,且没有相应的标注。本文提出hidden-unit Bert,HuBert,通过聚类的方式提供标签。
method
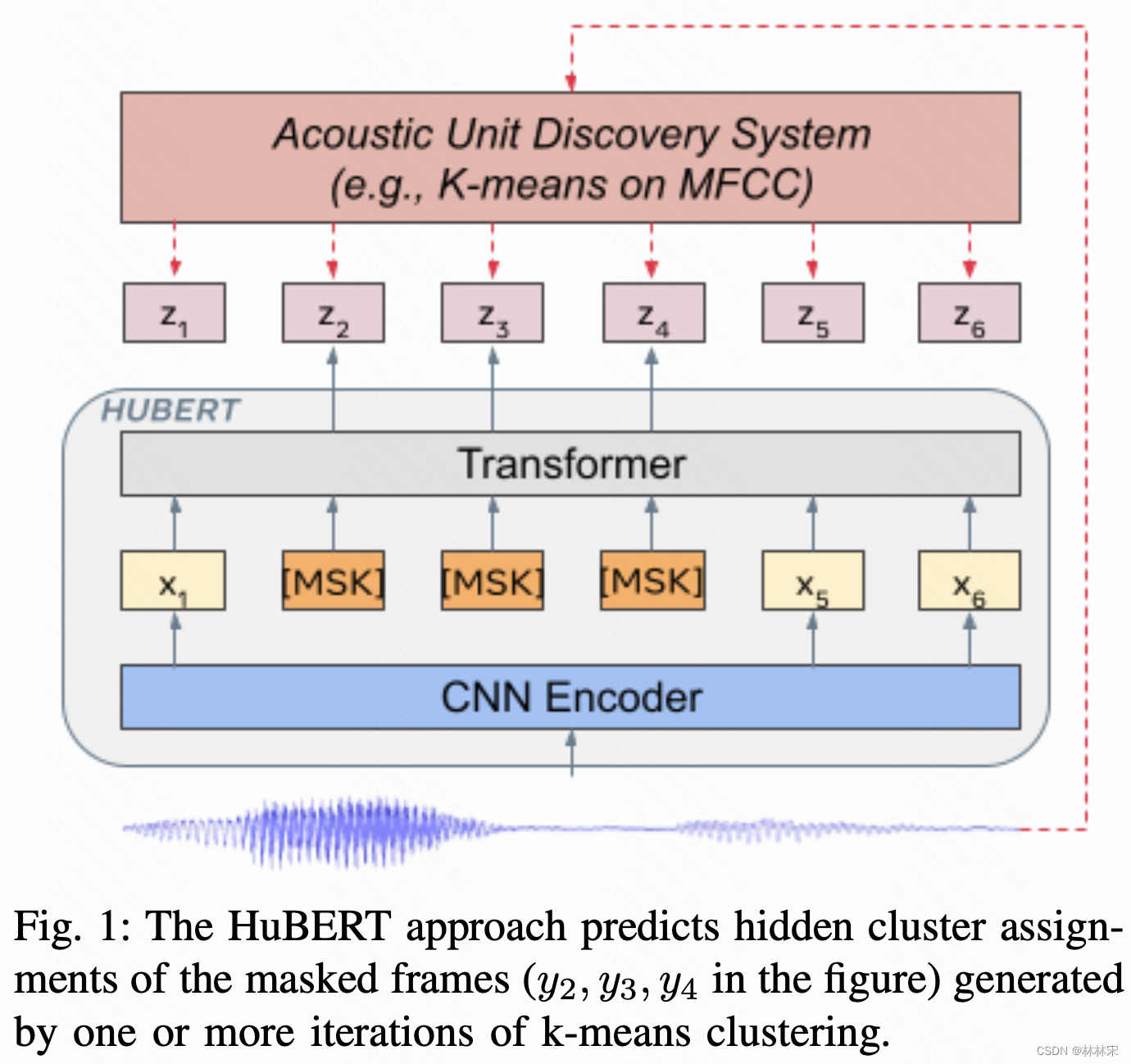
- X= CNN Encoder(wav),降维
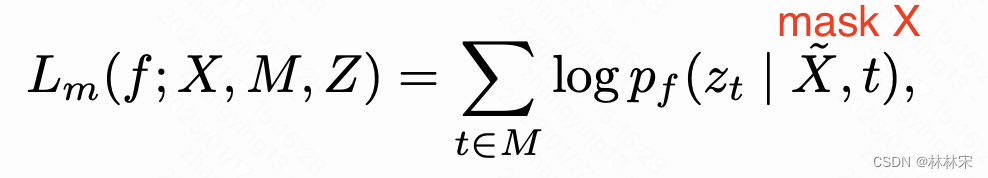
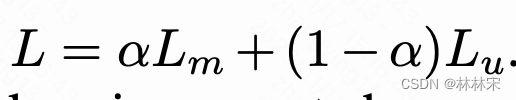
- Z=Transformer(X),时序建模,输入的X有一定比例 α \alpha α的mask, L u L_u Lu表示unmasked部分
- Z和聚类结果求loss
聚类
- 聚类整合的方式:单个Kmeans聚类,会因为初始值或者k值的选择结果差别很大,为了避免这个问题,设置多个kmeans聚类。而且多个kmeans聚类可以学习到不同粒度的表征。也可以通过product quantization进行量化,多个不同的码本。
- 训练过程中定义聚类:对learn latent representation离散化,然后在训练过程中更新聚类结果。
related work
- HuBERT and DiscreteBERT: - 相同点:都预测masked region的discrete targets。- 不同点:(1)HuBERT输入的是原始语音,以传达尽可能多的信息,这一点很重;(2)而且实验证明HuBERT使用简单的kmeans达到比DiscreteBERT vq-vae更好的效果。(3)多个trick改善teacher的质量,但是DiscreteBERT只使用一个fixed teacher。
- HuBERT and wav2vec 2.0 - wav2vec 2.0使用对比损失,需要设计负样本的来源;Gumble-softmax用于多样性损失,需要设计temperature annealing schedule。而且wav2vec 2.0对encoder output进行量化,本文的消融实验证明这种量化方式会因为encoder 能力有限限制量化结果质量。- HuBERT离散化的结果更好。our proposed method adopts a more direct predictive loss by separating the acoustic unit discovery step from the masked prediction representation learning phase。- HuBERT将半监督学习中伪标签生成的方法扩展到自监督学习中,使用iterative refinement target label的方法。
experiment
- 训练集合:LibriSpeech audio 960h,或者Libri-light 60k hours。(audiobooks reading by volunteers)
- 测试集合:Libri-light 10-minute, 1-hour, 10- hour splits and LibriSpeech 100-hour
Unsupervised Unit Discovery
- first iteration:39-d MFCC用kmeans(k=100)聚类;
- subsequent iterations:kmeans=500,作用对象transformer的中间层。对960h小时数据抽样10%用于聚类(整体都聚耗费太大)
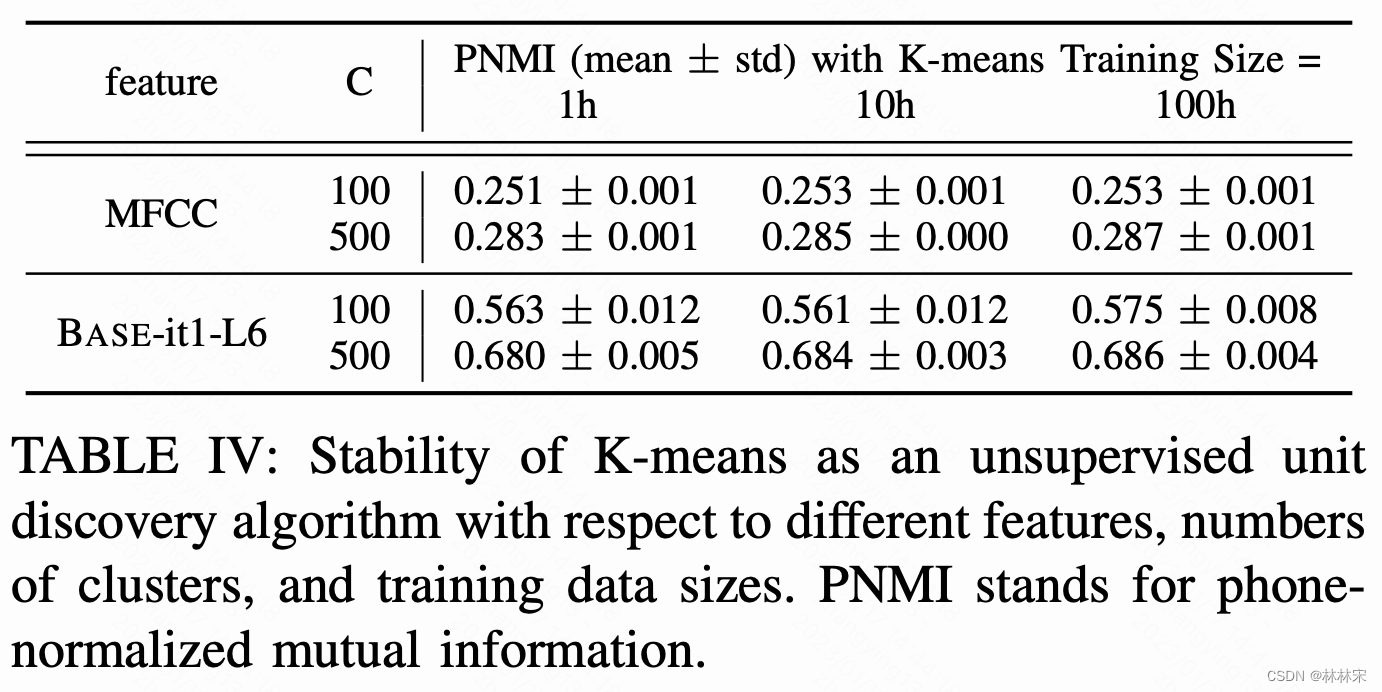
- scikit-learn实现的MiniBatchKMeans包,mini-batch size=10000frames,20个随机的starts for better init。
- 比较不同数据类型&数据量下聚类结果,(方差越小,聚类结果越稳定)
本文转载自: https://blog.csdn.net/qq_40168949/article/details/128677418
版权归原作者 林林宋 所有, 如有侵权,请联系我们删除。
版权归原作者 林林宋 所有, 如有侵权,请联系我们删除。