
端到端流式语音识别研究综述(2022.09)
摘要:
- 语音识别是实现人机交互的一种重要途径,是自然语言处理的基础环节,随着人工智能技术的发展,人机交互等大量应用场景存在着流式语音识别的需求。流式语音识别的定义是一边输入语音一边输出结果,它能够大大减少人机交互过程中语音识别的处理时间。目前在学术研究领域,端到端语音识别已经取得了丰硕的研究成果,而 流式语音识别在学术研究以及工业应用中还存在着一些挑战与困难,因此,最近两年,端到端流式语音识别逐渐成为语音领域的一个研究热点与重点。从端到端流式识别模型与性能优化等方面对近些年所展开的研究进行全面的调查与分析,具体包括以下内容:(1)详细分析和归纳了端到端流式语音识别的各种方法与模型,包括直接实现流式识别的CTC与RNN-T模型,以及对注意力机制进行改进以实现流式识别的单调注意力机制等方法;(2)介绍了端 端流式语音识别模型提高识别准确率与减少延迟的方法,在提高准确率方面,主要有最小词错率训练、知识蒸馏等方法,在降低延迟方面,主要有对齐、正则化等方法;(3)介绍了流式语音识别一些常用的中英文开源数据集以及流式识别模型的性能评价标准;(4)讨论了端到端流式语音识别模型的未来发展与展望。
引言:
- 语音识别模型从最初的基于GMM-HMM[1]的模型,发展到基于DNN-HMM[2-4]深度神经网络模型,再到现在的端到端[5-8]语音识别模型,已经历经三个阶段。通过这三个阶段的发展,模型结构越加简单,语音识别的准确率几乎趋于饱和状态,然而,大部分模型都是针对非流式语音识别而言的,在测试模型性能的时候很少会去考虑模型识别延迟的问题。近几年来,语音识别模型进入端到端的时代,不再依赖传统语音识别系统中已经使用了几十年的建模组件,使用单个网络便可将输入的语音序列直接转换成输出的标签序列,使得模型的尺寸更小,因此,大量研究人员开始从深度神经网络模型转向研究端到端语音识别模型,另外,大量的研究证明,端到端模型已经在学术研究领域[7]以及工业生产领域[9-10]超越了基于 DNN-HMM的深度神经网络模型。未来几年,端到端模型将是语音识别领域研究的重点。常见的端到端模型有CTC[11]、RNN-T[12]、attention-based encoderdecoder[13-14]、LAS[8]等模型,前两种能够直接实现流式识别,而后两种模型由于注意力机制需要获取完整的声学序列而不能够直接进行流式识别。流式语音识别又称为实时语音识别,它指的是用户在说话的时候模型便已经开始进行识别,与之相对的非流式识别则是用户说完了一句话或一段话之后模型开始识别。
- 随着科技的不断发展,各种穿戴式、便携式的智能设备,以及大量的应用软件已经完全融入大众生活,常用的输入法、在线会议、直播、实时翻译等一系列的应用存在着流式语音识别的需求。端到端流式识别模型不需要额外的语言模型,更容易部署在设备端,另外,智能客服等多种需要流式识别的人机交互场景也在不断产生,所以端到端流式语音识别模型将会是未来几年的研究热点,而且也具有广阔的应用前景。因此,本文主要从模型结构、性能优化、常用的中英文开源数据集以及模型性能评价标准等方面分析总结了目前端到端流式语音识别模型的研究状况,进而提出了未来的发展与展望。
- 2021年国外有两篇相关的语音识别领域的综述,文 献[15]主要总结了近十年语音识别模型结构与性能的发展,并从研究与应用两个方面预测了语音识别未来十 年的发展趋势。文献[16]详细概述了端到端语音识别模型的发展及其在实际工业生产中的应用情况,同时从 行业角度出发,重点介绍了端到端语音识别模型如何去解决未来的应用部署中的一些挑战与困难。以上两篇 文章都是从大的领域、更高视野出发,总结概述端到端语音识别的发展,而这篇文章,则是聚焦到端到端流式 语音识别这个领域,去分析总结其发展现状。 端到端流式语音识别模型
1 端到端流式语音识别模型
1.1 可直接实现流式识别的端到端模型
- 在端到端流式语音识别模型中,能够直接进行流式 识别的模型主要有 connectionist temporal classification(CTC)[11] 、recurrent neural network transducer(RNN-T)[12] 、 recurrent neural aligner(RNA)[17] 等模型。文献[11]提出 connectionist temporal classification(CTC)损失函数,用 来对模型中的循环神经网络产生的转录进行评分,使得模型能够完成音频帧与标签的自动对齐。从端到端语 音识别模型的发展来看,CTC最先被应用到端到端语音 识别模型[5-6,18-23],它能够直接将输入的语音序列转换成 输出的标签序列,其结构如图1[16] 所示,输入的语音序列 xt 通过编码器进行编码输出特征表示henc t ,再经过一个 线性分类器得到每个时刻输出类别的概率 P(yt|xt) 。
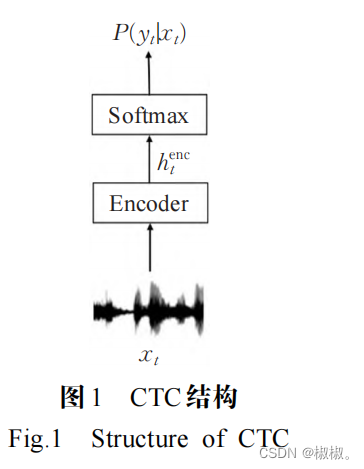
- 通过在编码器中使用单向的循环神经网络(unidirectional RNN),CTC 模型能够实现流式语音识别。文献[12]提出了recurrent neural network transducer(RNN-T)模型,该模型为流式语音识别提供了一种自然的方式, 因为它的输出取决于之前的输出标签序列和当前步及 之前的输入语音序列,即 P(yu|x1:t ,y1:u - 1) ,通过这种方 式,消除了 CTC的条件独立假设,由于其具备自然的流式性质,在该领域应用中受到了广泛的使用[9,24-31] 。
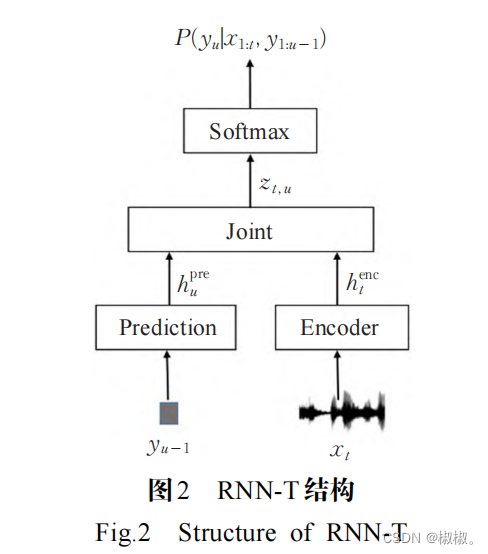
- RNN-T 模型的结构如图 2[16] 所示,它包含一个编码 器网络、一个预测网络和一个联合网络,编码器将输入 的语音序列 xt转换成高级特征表示 henc t ,预测网络基 于 RNN-T 之前的输出标签 y1:u - 1 ,生成高级表示 h pre u ,联合网络是一个前馈网络,将 ht 与 hu 作为输入,输出 zt,u 。
- 针对CTC所存在条件独立性假设的问题,文献[17]提出了一种新的模型:recurrent neural aligner(RNA), 类似于 CTC 模型,该模型定义了目标标签序列上的概率分布,包括对应于输入中每个时间步长的空白标签,通过边缘化所有可能的空白标签位置来计算标签序列的概率。但该模型并不做标签预测的条件独立性假设,此外,它在输入的每个时间步预测一个输出标签,而不是通过 RNN-T 预测多个标签,从而简化了波束搜索解码,使得训练更加有效,在执行流式语音识别任务时,它成功地应用于多种口语识别任务[32]。
1.2 改进后可实现流式识别的端到端模型
- 在端到端语音识别模型中,基于注意力[33-36] 的模型 由于其自身特点不能够直接实现流式识别,而这些模型已经被证明在机器翻译[37-38] 、语音识别[34,39] 等领域的许多问题中非常有效,在该结构中,首先,编码器对整个输入序列进行编码,产生相对应的隐藏状态序列,其次,解码器根据编码器所产生的状态序列来进行预测,最终产生输出序列。目前,基于注意力的端到端模型已在相关的 语音识别[34,40]任务中取得了重大进展,在识别准确率方 面,实现了非流式语音识别模型的最好性能[39] 。然而,基于注意力模型并不能够直接应用于流式语音识别问题,一方面,这些模型通常需要获取完整的声学序列作为输入,使得编码与解码不能够同步进行;另一方面,对于语音来说,它们没有固定的长度,模型的计算复杂度随着输入序列的增加而二次增加。为了能够将注意力机制应用于流式语音识别任务中,大量的研究人员针对以上问题开展研究,通过对全局注意(local attention)机制做出改进,针对在时刻 t 将哪一部分的输入序列信息进行编码,同时对于已编码的信息,将哪一部分进行 解码的问题,提出了基于单调注意力机制(monotonic attention mechanism)[41- 45]、基于块(chunk-wise)[46- 51] 、基 于信息累积(accumulation of information)[52-55]以及触发 注意(triggered attention)[56-58] 等方法。
1.2.1 基于单调注意力机制的方法
- 文献[42]提出了一种局部单调注意(local monotonic attention)机制,它具有局部性和单调性,局部性帮助模型的注意模块专注于解码器想要转录的输入序列的某 一个部分,单调性严格地从输入序列的开始到结束左右生成对齐。该机制迫使模型在每个解码步骤预测中心位置,并仅在中心位置周围计算软注意权重。然而,仅仅基于有限的信息,很难准确预测下一个中心位置。与 软注意相比较,硬单调性约束限制了模型的表达能力,文献[43]提出了单调组块注意(monotonic chunk-wise attention,MoChA)机制来缩小软、硬注意之间性能的差距,它基于预测的选择概率自适应地将编码的状态序列 分割成小的组块,如图 3[43] 所示,块边界由虚线表示,允许模型在硬单调注意机制选择参与的小组块上执行软 注意,但是它的训练过程非常复杂困难,以至于最终难以实现。

- 文献[44]提出了单调多头注意(monotonic multihead attention,MMA),该机制结合了多层多头注意和单调注意的优点,同时提出了两种变体,即 Hard MMA (MMA-H)和 Infinite LookbackMMA(MMA-IL),前者 在设计时考虑到了注意力持续时间必须有限的流式系 统,而后者强调识别系统的质量。文献[45]对于一些应用局部单调注意机制的模型的变体进行了修改,同时也 对这些模型进行了全面的比较,最后通过采用固定大小的窗口实现了一种简单有效的启发式执行局部注意的 方法。
1.2.2 基于块的方法
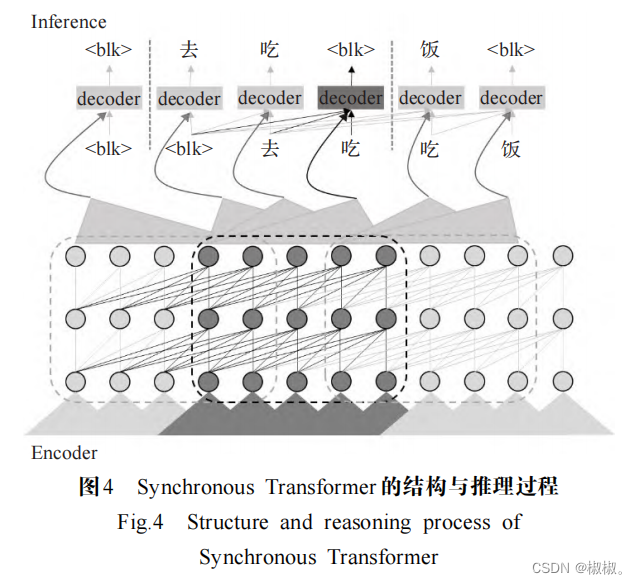
- 文献[46]提出了 Neural Transducer,它根据部分观 察到的输入序列和部分生成的序列来计算下一步的分布,使用编码器来处理输入,将处理后的结果作为 Transducer的输入,在每个时间步长,根据编码器处理好的输入块,Transducer决定可以产生零到多个输出标签, 由此实现流式解码,然而,由于该模型受到循环神经网络时间相关特性的束缚,它仅仅优化对应于组块序列的 近似最佳对齐路径。文献[47]使用自注意模块替代了RNN-T结构中的RNN模块,提出了一种自注意transducer (self-attention transducer,SAT),它能够利用自注意块来模拟序列内部的长期依赖性,同时引入了块(blockflow)机制,通过应用滑动窗口来限制自注意的范围,并且堆叠多个自注意块来模拟长期依赖性,但从整体而 言,虽然块流机制能够帮助 SAT 实现流式解码,但仍然引起了识别准确率的下降。因此,文献[49]提出了 一种同 步transformer(synchronous transformer,SyncTransformer)模型,能够同步进行编码与解码,其结构与 推理过程如图4[49]所示。Sync-Transformer将transformer 与 SAT 深入组合,为了消除 self-attention 机制对于未来帧的依赖,则强制编码器中的每个节点仅仅关注左侧上 下文并完全忽略右侧上下文。一旦编码器产生了固定长度的状态序列块,解码器则立即开始预测标签。
1.2.3 基于信息堆叠的方法
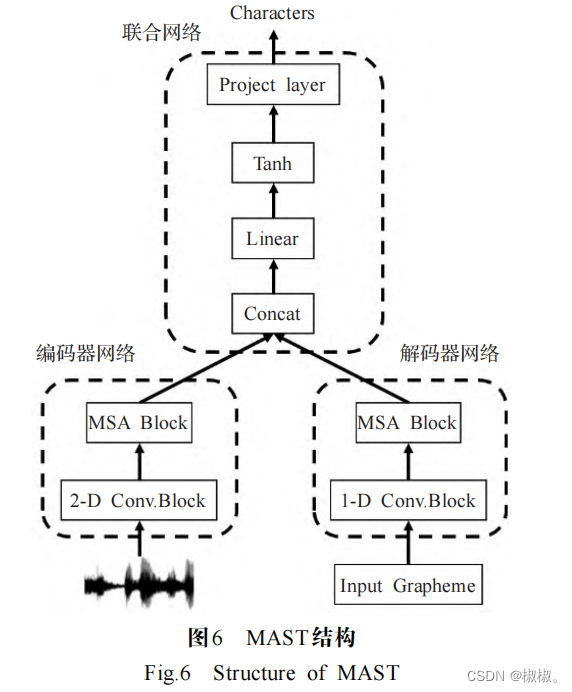
- 文献[53]提出了自适应时间(adaptive computation time,ACT)算法,该算法支持RNN以学习在接受输入和产生输出之间需要采取多少计算步骤,为后续自适应计 算步的研究打下了基础。文献[54]提出了一种新颖的 自适应计算步算法(adaptive computation steps,ACS), 该算法使端到端语音识别模型能够动态地决定应该处理多少帧来预测语言输出,一方面,对准器在思考间隔 内计算每个编码器时间步长停止的概率,并且像基于软 注意模型一样来总结上下文向量,另一方面,该模型不 断检查停止概率的累积,如果总和达到阈值之后立即做出输出的决定。文献[55]提出了解码器端自适应计算 步算法(decoder-end adaptive computation steps,DACS) 来解决标准 transformer 不能够直接用于流式识别的问 题,该算法通过在从编码器状态获得的置信度达到某个 阈值之后触发输出来传送 transformer ASR 的解码,通 过引入最大前(look-ahead)性步骤来限制DACS层可以查看每个输出步骤的时间步数,以防止过快地达到语 音结束,但 DACS对 transformer解码器采用异步多头注意机制,破坏了在线解码的稳定性。受到spiking neural networks 中的 integrate-and-fire模型的启发,文献[66]提 出了用于序列转换的新型软单调对比机制 continuous integrate-and-fire(CIF),能够支持各种在线识别任务以 及声学边界定位。在每个编码器步中,接受当前编码器步的向量表示和缩放向量中包含的信息量的相应权重,向前累积权重并积分向量信息,直到累积的权重达到阈值,此时声学边界被定位,且当前的编码器步的声学信息由两个相邻标签共享,CIF 将信息分为两个部分:一部分用于完成当前标签的集成;另一部分用于下一个标签的集成,模拟处理在编码器步期间的某个时间点触发时,将集成的声学信息触发到解码器以预测当前标签,如图5[56]所示,每条虚线代表一次触发,直到整个声学序列完成编码。文献[57]提出了存储器自注意传感器(memory- self-attention transducer,MSAT),其结 构如图 6[57]所示,MSA模块将历史信息添加到受限制的自我注意单元中,通过参与存储器状态有效地模拟长时间的上下文,并使用 RNN 损失来对 MSA 模块进行训练,实 现了该结构在流式任务中的应用。

1.2.4 其他方法
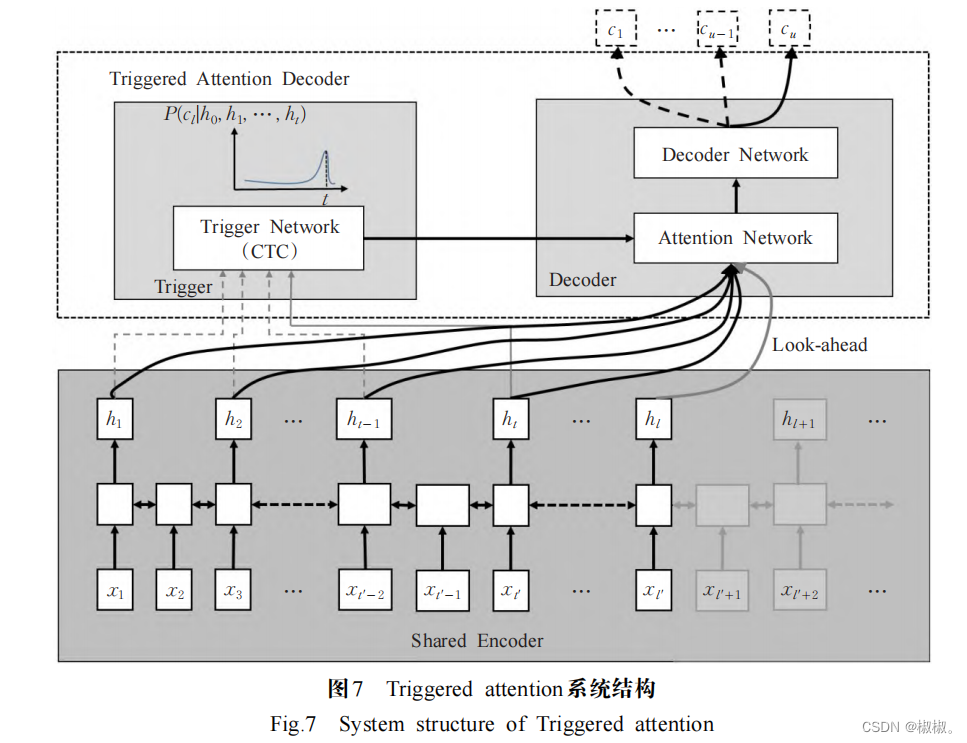
- 以上提出来的方法能够实现流式语音识别,但也存 在问题。基于单调注意力机制的方法由于使用软硬注意机制导致训练过程非常困难;基于块的方法往往由于 忽略组块之间的关系而导致性能下降;而基于信息堆叠 的方法打破了Transformer在训练中的并行性,通常需要 更长的训练时间[58]。文献[59]提出了触发注意(triggeredattention,TA)[59-61] ,其结构如图 7[59] 所示,TA 解码器由一个触发模型和一个基于注意的解码器神经网络组成,编 码器神经网络由触发网络和注意机制共享。注意权重只能看到触发事件之前的编码器帧及一些向前的帧。 在训练期间,CTC输出序列的强制对齐用于导出触发的 时间,在解码期间,考虑 CTC训练的触发模型的不确定 性以分别生成替代的触发序列和输出序列,推理以帧同 步解码方式进行。此外,一些研究人员用 Transformer 替 换 了 RNN- T 结 构 中 的 RNN,构 建 了 Transformer Transducer(TT)[62-69] 结构,大量的研究[62-69] 证明了该结构 也具有较好的流式识别能力。
2 端到端流式语音识别模型的优化方法与策略
- 端到端流式语音识别模型是当前语音识别领域的 研究热点与重点,对于非流式模型而言,需要占用尽可能小的内存去实现更高的识别准确率,然而,对于流式 识别模型,既需要考虑模型的识别准确率又需要考虑识别的延迟大小。这两个方面共同决定了流式语音识别 模型的性能。以下将从延迟与准确率两个方面来探索 流式语音识别模型的优化问题。
2.1 如何降低流式语音识别模型的延迟
- 当识别一句话时,一般有两种语音延迟[70] :第一种 是第一标签产生延迟(first token emission delay),通过分析用户实际说话开始时间与语音识别系统实际产生 出第一个标签的时间可以获取到该种延迟的时间;第二 种是用户感知延迟(user perceived latency),当用户停止说话时开始计时,直到模型发出最后一个非空标签,一般将这段时间称为用户感知延迟。
- 近期研究[70]表明影响流式语音识别模型用户感知延迟的主要因素有模型结构、训练标准、解码超参数以及端点指示器,而模型的大小与模型计算速度并不总是严重影响用户感知延迟。目前,研究人员主要从训练策略、对齐与正则化[71]训练等角度出发来探索如何降低模型的延迟,文献[72]提出一种自适应的前瞻(adaptivelook-ahead)方法来权衡延迟和词错率,其中的上下文窗口大小并不固定,可以动态地修改,引入 scout network(SN)和 recognition network(RN)两个神经组件,其中,scout network 负责检测语音中一个单词的开始和结束边界,recognition network 通过向前看预测边界进行帧同步单通道解码,虽然这个方法在权衡延迟与准确率方面取得了很好的效果,但 SN 没有解决随着左上下文长度的平方增长的繁重的自我注意计算。
- 文献[73]基于MoChA 提出了最小延迟训练策略(minimum latency training strategies),利用从混合模型中提取的外部硬对齐作为监督,迫使模型学习准确的对齐方式,在解码器端提出了延迟约束训练(DeCoT)和最小延迟训练(MinLT)两种方法,有效地减少了模型的延迟。文献[74]则从模型结构与端点指示器出发,提出了一个双通道的RNN-T+LAS模型,其中LAS对RNN-T的假设进行重评分,同时通过预测查询结束(end-of-query)符号,将EOQ端点指示器集成到端到端模型中,用来帮助关闭麦克风,这种方法实现了端到端模型在质量与延迟的权衡方面对传统混合模型的首次超越。文献[75]提出了一种新的延迟约束法:自对准,该方法不需要外部对准模型,而是通过利用自训练模型的维特比强制对齐来寻找较低延迟对齐方向。文献[76]从延迟正则化训练的角度出发,基于 Transducer的流式模型提出了一种新的序列级产生正则化方法FastEmit,在训练transducer模型时能够直接对每序列概率应用延迟正则化,而不需要任何语音-单词对齐信息,同时,相较于其他正则化方法,Fast-Emit方法需要调整的超参数最少。通过在大量端到端模型上展开实验,表明该方法能够实现很好的词错率与延迟的权衡。通过以上研究可知目前已有限制对齐、正则化等多种方法可以相对解决流式语音识别模型的延迟问题,大多数的方法虽然降低了模型的延迟,但同时也导致了识别质量的下降,这将是未来仍需不断探索的一个研究方向。
2.2 如何提高流式语音识别模型的准确率
- 提高语音识别模型的准确率一直是个热门话题,从 1988年第一个基于隐马尔科夫模型(HMM)的语音识别 系统 Sphinx[77]诞生开始,到现在语音识别模型步入端到 端的时代,研究人员不断做出探索希望语音识别模型的 准确率能够得到进一步提升,从传统混合模型[78]到深度 神经网络模型[2] 再到现在的端到端模型[40] ,模型结构改 变的同时,语音识别模型准确率也得到大幅度提升。与非流式模型一样,提升流式模型准确率的方式有改变模 型基本结构、预训练、扩大数据域、最小词错率训练 (MWER)[79-83] 、知识蒸馏[84-89] 等方式,其中,改变模型结构 已在第 1 章进行阐述。文献[73]以 MoChA 作为流式语 音识别模型,在编码器端,采用了多任务学习并使用帧 交叉熵目标进行预训练,提升了模型的识别准确率。文 献[83]提出了一种新颖且有效的基于 RNN-T 模型的 MWER 训练算法,对 N 个最佳列表中每个假设的所有 可能对比的得分求和,并使用它们来计算参考和假设之 间的预期编辑距离,当为 endpointer(EP)添加 end- ofsentence(EOS),所提出的 MWER训练还可以显著减少 高删除错误。文献[84]研究了基于知识蒸馏的模型压 缩方法来训练 CTC 声学模型,评估了 CTC 模型的帧级知识蒸馏方法和序列级知识蒸馏方法,通过在WSJ数据 集上展开实验,提高了模型的识别准确率。文献[90]实现了从非流式双向RNN-T模型到流式单向RNN-T模型的知识蒸馏,实验结果表明,通过所提出的知识蒸馏训练的单向RNN-T比用标准方法训练的单向模型具有更好的准确性。文献[85]研究了非流式到流式TransformerTransducer模型的知识蒸馏,在实验中比较了两种不同的方法:隐藏向量的 L2距离最小化和头部 L2距离的最小化,实验结果表明,基于隐藏向量相似性的知识蒸馏优于基于多头相似性的知识蒸馏。
3 数据集与评估标准
3.1 数据集
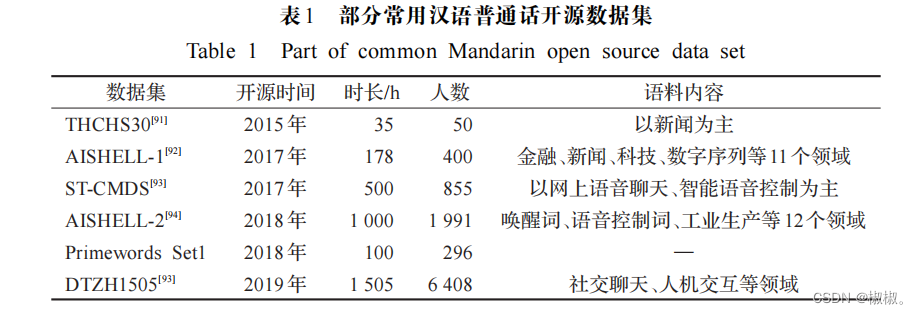
- 一些中文普通话以及英语等常见的一些数据集。中文语音识别开源数据集如表 1 所示,2015 年,清华大学信息技术研究院语音语言技术中心发布了第一个开源中文语音数据库 THCHS30[91] ,以帮助研究人员搭建起第一个语音识别系统。但是该数据集的语音总 时长仅仅只有35h,对于模型的训练还不够充分,2017年, 北京希尔贝壳科技有限公司发布了AISHELL-1[92] 语料库,成为了当时最大的开源汉语语音识别语料库,冲浪 科技也发布了ST-CMDS语音数据集[93],2018年,北京希尔贝壳科技有限公司发布了AISHELL-2[94] 语料库,上海 原语公开了 Primewords Set1数据集,2019 年,数据堂(北京)科技有限公司开源了中文普通话语音数据集 DTZH1505[93] ,记录了 6 408位来自中国八大方言地域、33个省份的说话人的自然语言语音,时长达 1 505 h,语 料内容涵盖社交聊天、人机交互、智能客服以及车载命令等[93],这是目前最大最全面的中文开源语音数据集。
3.2 评价指标
- 对于端到端流式识别模型来说,主要通过模型的准 确率与识别的延迟两个方面来评价其性能的优劣,在准 确率方面,通过计算出语句的词错率(word error rate, WER)或者字错率(character error rate,CER)来评价模 型,常用词错率来计算,把 T作为一句话中的总单词 数,S 作为识别结果中替换单词数,D 作为识别结果中 删除的正确话语中的单词数[102] ,I 作为没有在正确话语中而出现在识别结果中的插入单词数,那么词错率 (WER)则定义为:

- WER的值越低,则说明模型的识别准确率越高,性能越 好。在延迟方面,实时因子(real time factor,RTF)则是流式语音识别过程中的评价标准,它的值小于 1 的时候,称模型是实时识别的,此外也可以计算出语句级或词语级的延迟数值(latency)。把 M 作为一段音频的时 长,把 N 作为识别出这段音频的时长,则实时因子 (RTF)则定义为:

- RTF的值越小,则说明延迟越小,模型的性能越好。
本文转载自: https://blog.csdn.net/qq_38978225/article/details/129488877
版权归原作者 椒椒。 所有, 如有侵权,请联系我们删除。
版权归原作者 椒椒。 所有, 如有侵权,请联系我们删除。