【OpenCV】图像拼接 原理介绍 C++ OpenCV 案例实现
本文以实现图像拼接为目标,把分割开的图像进行拼接还原,核心的内容包括:OpenCV图像拼接相关原理以及OpenCV图像拼接案例的实现

使用Python和OCR进行文档解析的完整代码演示
在本文中将使用Python演示如何解析文档(如pdf)并提取文本,图形,表格等信息。
Opencv学习(1)——图像的基本操作
Opencv学习(1)
对抗生成网络GAN系列——GAN原理及手写数字生成小案例
其实关于GAN的讲解我早就做过一期,点击☞☞☞了解详情🌱🌱🌱由于最近会用到GAN的一些知识,自己又对GAN进行了一些整理,有了一些新的认识,便写了这篇文章。那么这篇文章和早期的文章有什么区别呢?首先,早期的文章只是对GAN做了一个大概的认识,而这篇文章会贴合论文较为详细的讲解GAN网络;其次,
OpenCV C++案例实战二十七《角度测量》
本案例通过使用OpenCV中的鼠标点击事件进行物体角度测量。以鼠标点击三点确定一个角度。第一个点即为需要测量角度所在位置点(中心点),第二、三点确定角度。本文使用OpenCVC++进行物体角度测量,主要操作有以下几点。1、利用鼠标响应事件取点,三点确定一个角度2、利用两直线角度公式计算直线角度,注意
Ubuntu20.04部署yolov5目标检测算法,开发板/无人机应用
FireFlyRK3588开发板上烧录的Ubuntu20.04系统,在此基础上线部署下简单的Python版本yolov5代码,目前博主已全部转为C++版本了,并且转化了pt模型为rknn模型,调用npu进行推理,效果和速度都比原先Python代码好很多。本篇主要介绍如何部署和运行yolov5目标检测
史上最详细人脸检测libfacedetection讲解---第一节
以下是关于我个人对libfacedetection(人脸检测-pytorch)的所有见解,如有错误欢迎大家在评论区指出,我将会第一时间纠正。据说,人脸检测速度可以达到1000FPS,到底结果如何,我们来一探究竟。
计算机视觉 (Computer Vision) 领域顶级会议归纳
本文具体介绍几种计算机视觉顶级会议,包括计算机视觉领域三大顶尖国际会议 : CVPR、ICCV、ECCV ;还有其他一些 著名 会议: WACV、NIPS、ICLR、AAAI、ICML、IJCAI ;汇总信息在最后面,可以直接点击查看 ;............
基于3D Frangi滤波的血管强化方法(附代码python)
3D Frangi滤波 用于血管强化
【OpenCV】车辆识别 目标检测 级联分类器 C++ 案例实现
本文继续以车辆识别为目标,继续改进方法以此提高车辆识别进准度,核心的内容包括:OpenCV级联分类器概念、创建自己的级联分类器以及使用级联分类器对车流进行识别
Faster RCNN学习笔记
对Faster RCNN的学习进行一些记录,方便后面的复习,有错误欢迎指出
YOLOv7来临:论文解读附代码解析
官方版的YOLOv7相同体量下比YOLOv5精度更高,速度快120%(FPS),比 YOLOX 快180%(FPS),比 Dual-Swin-T 快1200%(FPS),比 ConvNext 快550%(FPS),比 SWIN-L快500%(FPS)。在5FPS到160FPS的范围内,无论是速度或是
【OpenCV】车辆识别 C++ OpenCV 原理介绍 + 案例实现
本文主要以车辆识别为目标,利用 C++语言 结合 Qt + OpenCV 进行图像处理相关步骤的讲解
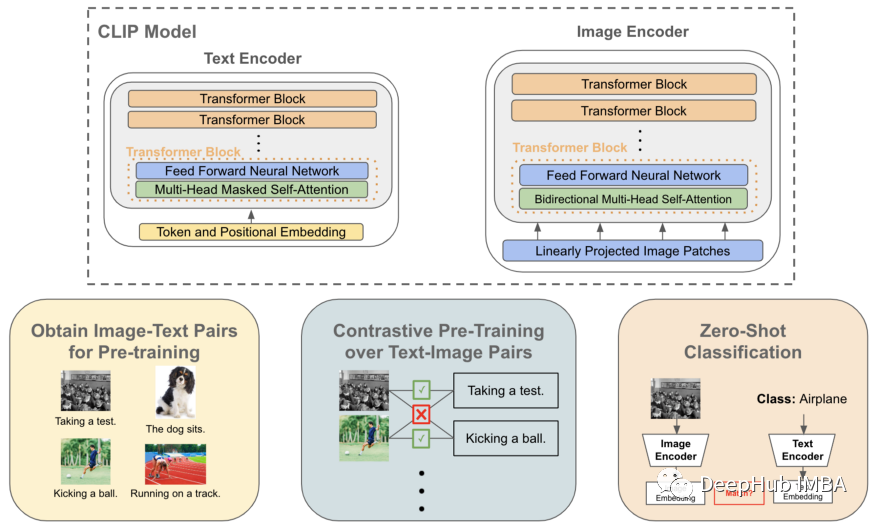
使用 CLIP 对没有标记的图像进行零样本无监督分类
OpenAI 提出的CLIP模型,不需要标签并且在 ImageNet 上实现 76.2% 的测试准确率,在这篇文章中将概述 CLIP 的信息,如何使用它来最大程度地减少对传统的监督数据的依赖,以及它对深度学习从业者的影响。
【OpenCV】Qt + OpenCV 开发配置 + 入门知识(代码示例)
本文主要学习 Windows下Qt + OpenCV的开发环境的相关配置,以及OpenCV入门相关案例包括 OpenCV图像原理、基础图像操作、案例实现
OpenCV:04图像的基本变换
关键API:其中:结果:结果:可以看到xy轴都缩小了一半仿射变换是图像旋转、缩放、平移的总称。具体的做法是通过一个矩阵和原图片进行坐标运算,得到新的坐标,完成变换,所以仿射变换的关键就是这个矩阵仿射变换不会改变每个像素点上的RGB色彩,只会改变像素对应的位置 ——> 我们只要找出其中对应的数学关系,
基于百度飞浆平台(EasyDL)设计的人脸识别考勤系统
软件主要是应用在高校给学生进行考勤、签到处理,所有在功能上需要健全,支持人脸签到,支持输入学号签到,支持添加学生,支持删除学生;在界面上也支持请假管理,需要请假的学生在界面上录入请假事由,方便上课老师了解该学生的详细情况。...
ubuntu20.04安装VITIS_HLS2021.2配置OPENCV4.4和VITIS_LIBRARIES(详细版)
大家好,今天给研友们配置一下这个VITIS_HLS,因这其中经历太多的坎坷,为让大家原理配置环境的烦扰,本人出个详细版,望大家喜欢我之前的博客已经出过vitis的安装,在此不在赘述,直接给出我博客的链接,请大家不要使用里面的opencv的安装,我在第三节会讲解opencv的安装(这个巨大的坑)VIT
OCR文字识别方法综述
摘 要:文字识别可以把海量非结构化数据转换为结构化数据,从而支撑各种创新的人工智能应用,是计算机视觉研究领域的分支之一,其任务是识别出图像中的文字内容,一般输入来自于文本检测得到的文本框截取出的图像文字区域。近几年来,基于深度学习的文字识别算法模型已取得不错成果,其过程无需进行特征处理且可以实现复
人脸识别AdaFace学习笔记
简单或困难样本的相对重要性应基于样本的图像质量。 AdaFace 提出了一种新的损失函数,它根据图像质量强调不同难度的样本。 该方法通过特征范数来表示图像质量,以自适应裕值函数的形式实现这一点。...



