最新CCF会议|2022-2023顶会会议时间+投稿时间+官网链接(视觉+多媒体+数据挖掘+数据库+通用人工智能)
最新CCF会议|2022-2023顶会会议时间+投稿时间+官网链接(视觉+多媒体+数据挖掘+数据库+通用人工智能)
图像数据的特征工程
总结了常用的图像特征工程,裁剪,灰度化,RGB通道选择,强度阈值,边缘检测和颜色过滤器
AI绘画生成器推荐AI绘画自动生成器有哪些?
它也是创建 NFT 艺术的用户友好的工具之一。StarryAI最棒的地方之一是,它为您提供了所创建图像的完全所有权,可用于个人或商业用途。大家也可以把它视为一个免费的NFT生成器,这是它的主要卖点。Dream可以把现有的照片变成漫画或者油画,还可以用复杂的算法把单词和短语变成独特的艺术作品。它可以通
OpenCV——Canny边缘检测(cv2.Canny())
Canny边缘检测Canny 边缘检测是一种使用多级边缘检测算法检测边缘的方法。1986 年,John F. Canny 发表了著名的论文 A Computational Approach to Edge Detection,在该论文中详述了如何进行边缘检测。Canny()边缘检测步骤Canny 边
yolov5——detect.py代码【注释、详解、使用教程】
yolov5——detect.py代码【注释、详解、使用教程】根据目前的最新版本的yolov5代码做出注释和详解以及使用教程,对了目前已经是v6,不知道你看博客的时候是什么版本呢,总的来说越来越先进越来越完善,越来越适合无脑啊哈哈哈,没你说哈IIIIdetect.py代码注释详解1. 函数parse
基于YOLOV5 的多分类 + 关键点检测
基于yoloV5 多分类+关键点检测
深入浅出 Yolo 系列之 Yolov7 基础网络结构详解
从 2015 年的 ** YOLOV1,2016 年 YOLOV2,2018 年的 YOLOV73,到 **2020 年的 YOLOV4、 YOLOV5, 以及最近出现的 ** YOLOV76** 和 ** YOLOV7** 可以说 YOLO 系列见证了深度学习时代目标检测的演化。对于
SegNeXt: 重新思考基于卷积注意力的语义分割
重新设计基于CNN的语义分割,超越Transformer。
基于matlab的车牌识别系统的实现
本项目以车辆牌照为依据,基于matlab软件设计了车牌识别系统(Vehicle License Plate Recognition, VLPR),能够检测到受监控路面的车辆并自动提取车辆牌照信息(汉字字符、英文字母、阿拉伯数字)。主要实现的功能为从图像中提取车牌信息,并输出到操作界面中。该系统输入为
数字图像处理课程设计-疲劳检测系统
文章目录数字图像处理课程设计-疲劳检测系统前言一、课程设计任务二、设计框图三、准备工作四、任务流程4.1视频预处理4.2图片分割五、结果六、项目总结数字图像处理课程设计-疲劳检测系统前言此系统基于MATLAB设计,核心思想是PERCLOS算法.参考文章MATLAB疲劳检测系统 - 知乎 需要源码的,
要点初见:开源AI绘画工具Stable Diffusion代码分析(文本转图像)、论文介绍(上)
本文深入分析Stable Diffusion所对应的论文High-Resolution Image Synthesis with Latent Diffusion Models,即《具有潜在扩散模型的高分辨率图像合成》,并深入Stable Diffusion项目代码,分析文本转图像部分的代码。

在本地PC运行 Stable Diffusion 2.0
这里我们将介绍如何在本地PC上尝试新版本
【目标检测】英雄联盟能用YOLOv5实时目标检测了 支持onnx推理
dcmyolo(dreams create miracles),中文:大聪明目标检测工具包。该项目基于pytorch搭建,构建的目的是提供一个拥有更好性能的 YOLO版本,同时拥有丰富的中文教程和源码细节解读,提供算法工具箱,给出不同体量模型的实验数据,为算法落地带来便利。项目本着方便开发者的目的,
opencv阈值图像Threshold方法
阈值Threshold
[毕业设计]机器学习的运动目标跟踪-opencv
[毕业设计]机器学习的运动目标跟踪-opencv:目标跟踪指的是对视频中的移动目标进行定位的过程。在如今AI行业有着很多应用场景,比如监控,辅助驾驶等。对于如何实现视频的目标跟踪,也有着许多方法。比如跟踪所有移动目标时,视频每帧之间的变化就显得很有用。
python+人脸识别+opencv实现真实人脸驱动的阿凡达(上)
我们在此前的名叫python+opencv实现人脸微整形博文里已经简单地实现了人脸图像的微形变,为人脸驱动一个虚拟人脸提供了一些基础,但是运行性能上面需要优化,因为要想用人脸特征点实时驱动,需要非常快速的响应时间。
国庆假期看了一系列图像分割Unet、DeepLabv3+改进期刊论文,总结了一些改进创新的技巧
图像分割系列改进论文如何寻找自己的创新点呢?重点是如何发?下面将提供几种总结思路。
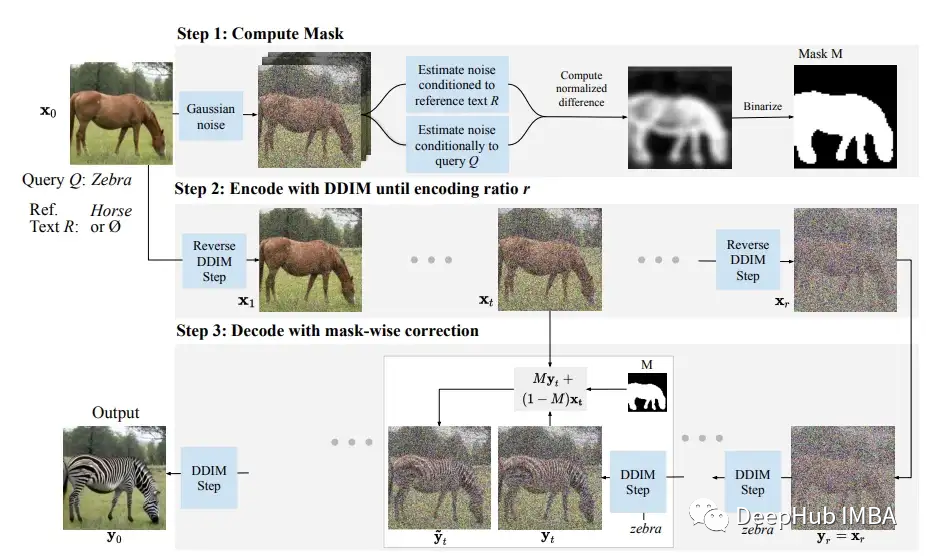
使用HuggingFace实现 DiffEdit论文的掩码引导语义图像编辑
在本文中,我们将实现Meta AI和Sorbonne Universite的研究人员最近发表的一篇名为DIFFEDIT的论文。对于那些熟悉稳定扩散过程或者想了解DiffEdit是如何工作的人来说,这篇文章将对你有所帮助。
KITTI数据集解析和可视化
文章链接概述KITTI数据集是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。该数据集用于评测立体图像(stereo),光流(optical flow),视觉测距(visual odometry),3D物体检测(object detection)和3D跟踪(tracking)等计算机视觉技
计算机视觉项目实战-基于特征点匹配的图像拼接
之前我们介绍过基于OpenCv的特征匹配操作,我们通过特征匹配可以精确的找到目标。本节我们继续探索基于特征匹配还可以做哪些事情。我们都在拍一个集体的过程中使用过苹果手机的全图效果进行拍照留念。那么苹果手机这个效果它是基于什么技术来做的呢?没错其实就是特征匹配。他是实时拍取多个照片,然后使用特征匹配操



