
简单的少镜头目标检测
论文:https://arxiv.org/abs/2003.06957
代码:https://github.com/ucbdrive/few-shot-object-detection
Abstract
Detecting rare objects from a few examples is an emerging problem. Prior works show meta learning is a promising approach. But, fine-tuning techniques have drawn scant attention. We find that fine-tuning only the last layer of existing detectors on rare classes is crucial to the few-shot object detection task. Such a simple approach outperforms the meta-learning methods by roughly 2~20 points on current benchmarks and sometimes even doubles the accuracy of the prior methods.
从几个例子中检测稀有物体是一个新出现的问题。先前的研究表明,元学习是一种很有前途的方法。但是,微调技术几乎没有引起人们的注意。我们发现,仅对稀有类现有检测器的最后一层进行微调对于少镜头目标检测任务是至关重要的。在当前的基准测试中,这种简单的方法比元学习方法高出大约2~20个百分点,有时甚至会使以前的方法的准确率翻一番。
However, the high variance in the few samples often leads to the unreliability of existing benchmarks. We revise the evaluation protocols by sampling multiple groups of training examples to obtain stable comparisons and build new benchmarks based on three datasets: PASCAL VOC, COCO and LVIS.Again, our fine-tuning approach establishes a new state of the art on the revised benchmarks.
然而,少数样本的高方差往往导致现有基准的不可靠。我们通过对多组训练样本进行采样来修改评估协议,以获得稳定的比较,并基于Pascal VOC、COCO和LVIS这三个数据集建立新的基准。同样,我们的微调方法在修订后的基准上建立了新的艺术状态。
1. Introduction
Machine perception systems have witnessed significant progress in the past years. Yet, our ability to train models that generalize to novel concepts without abundant labeled data is still far from satisfactory when compared to human visual systems. Even a toddler can easily recognize a new concept with very little instruction.
在过去的几年里,机器感知系统取得了重大进展。然而,与人类视觉系统相比,我们在没有大量标签数据的情况下训练概括为新概念的模型的能力仍然远远不能令人满意。即使是一个蹒跚学步的孩子,也能很容易地识别一个新概念,只需很少的指导。
The ability to generalize from only a few examples (so called few-shot learning) has become a key area of interest in the machine learning community. Many have explored techniques to transfer knowledge from the data-abundant base classes to the data-scarce novel classes through meta-learning. They use simulated few-shot tasks by sampling from base classes during training to learn to learn from the few examples in the novel classes.
仅从几个例子中进行概括的能力(所谓的少机会学习)已经成为机器学习社区感兴趣的一个关键领域。许多人探索了通过元学习将知识从数据丰富的基础类转移到数据稀缺的新类的技术。他们使用模拟的少射击任务,通过在训练期间从基础班级抽样来学习从新奇班级中的少数几个例子中学习。
However, much of this work has focused on basic image classification tasks. In contrast, few-shot object detection has received far less attention. Unlike image classification, object detection requires the model to not only recognize the object types but also localize the targets among millions of potential regions. This additional subtask substantially raises the overall complexity. Several have attempted to tackle the under-explored few-shot object detection task, where only a few labeled bounding boxes are available for novel classes. These methods attach meta learners to existing object detection networks, following the meta-learning methods for classification. But, current evaluation protocols suffer from statistical unreliability, and the accuracy of baseline methods, especially simple fine-tuning, on few-object detection are not consistent in the literature.
然而,这项工作的大部分集中在基本的图像分类任务上。相比之下,镜头较少的物体检测受到的关注要少得多。与图像分类不同,目标检测不仅需要模型识别目标类型,还需要在数百万个潜在区域中定位目标。这个附加子任务极大地增加了总体复杂性。有几个人试图解决探索不足的少镜头目标检测任务,其中只有几个标记的边界框可用于新的类别。这些方法将元学习器附加到现有的对象检测网络中,遵循元学习方法进行分类。但是,目前的评估协议存在统计不可靠的问题,并且基线方法,特别是简单的微调方法对少目标检测的精度在文献中并不一致。
In this work, we propose improved methods to evaluate few-shot object detection. We carefully examine finetuning based approaches, which are considered to be underperforming in the previous works. We focus on the training schedule and the instance-level feature normalization of the object detectors in model design and training based on fine-tuning.
在这项工作中,我们提出了改进的方法来评估少镜头目标检测。我们仔细检查了基于精调的方法,这些方法在以前的工作中被认为表现不佳。在模型设计和基于微调的训练中,重点研究了目标检测器的训练调度和实例级特征归一化问题。
We adopt a two-stage training scheme for fine-tuning as shown in Figure 1. We first train the entire object detector, such as Faster R-CNN, on the dataabundant base classes, and then only fine-tune the last layers of the detector on a small balanced training set consisting of both base and novel classes while freezing the other parameters of the model. During the fine-tuning stage, we introduce instance-level feature normalization to the box classifier inspired.
我们采用了图1所示的两阶段训练方案进行微调。我们首先在数据丰富的基类上训练整个目标检测器,例如较快的R-CNN,然后在由基类和新类组成的小的平衡训练集上只微调检测器的最后一层,而冻结模型的其他参数。在微调阶段,我们将实例级特征归一化引入到盒分类器中。
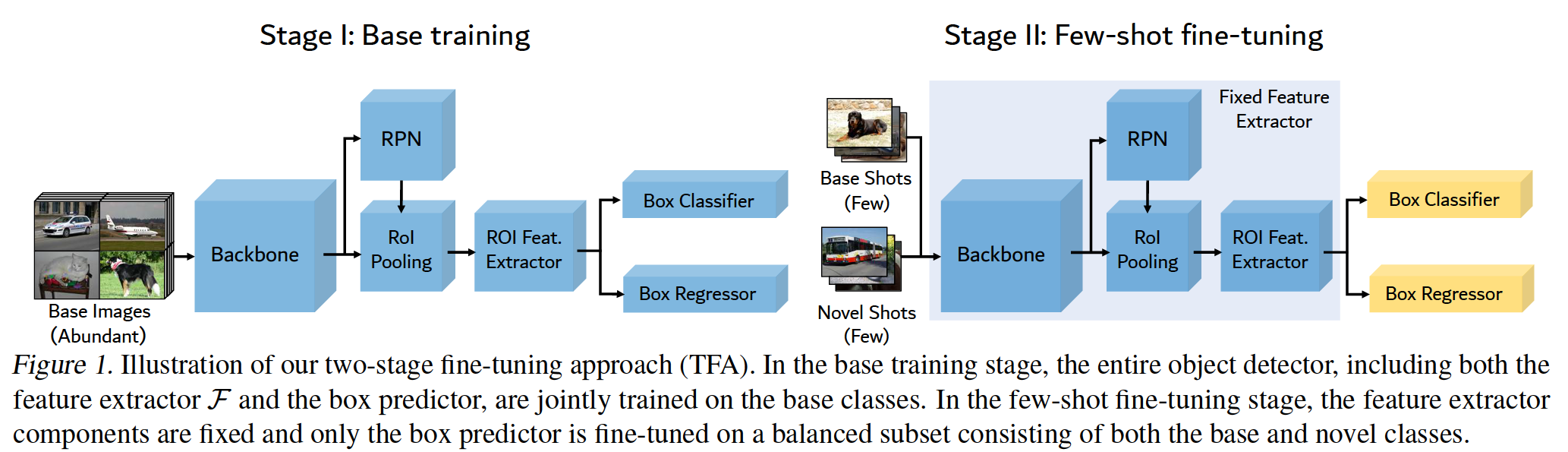
Figure 1. Illustration of our two-stage fine-tuning approach (TFA). In the base training stage, the entire object detector, including both the feature extractor F and the box predictor, are jointly trained on the base classes. In the few-shot fine-tuning stage, the feature extractor components are fixed and only the box predictor is fine-tuned on a balanced subset consisting of both the base and novel classes.
图1.我们的两阶段微调方法(TFA)的图解。在基本训练阶段,在基本类上联合训练整个对象检测器,包括特征提取器F和box预测器。在少镜头微调阶段,特征提取组件是固定的,并且只有box预测器在由基类和新类组成的平衡子集上被微调。
We find that this two-stage fine-tuning approach (TFA) outperforms all previous state-of-the-art meta-learning based methods by 2~20 points on the existing PASCAL VOC and COCO bench-marks. When training on a single novel example (one-shot learning), our method can achieve twice the accuracy of prior sophisticated state-of-the-art approaches.
我们发现,这种两阶段微调方法(TFA)在现有的PASCAL、VOC和COCO标准上比所有基于元学习的方法都要好2~20个点。当在单个新颖的例子(单次学习)上进行训练时,我们的方法可以达到先前复杂的最先进方法的两倍的准确率。
Several issues with the existing evaluation protocols prevent consistent model comparisons. The accuracy measurements have high variance, making published comparisons unreliable. Also, the previous evaluations only report the detection accuracy on the novel classes, and fail to evaluate knowledge retention on the base classes.
现有评估协议的几个问题阻碍了一致的模型比较。精确度测量的方差很大,使得已发表的比较结果不可靠。此外,以往的评估只报告了新类的检测准确率,而没有评估基类上的知识保持。
To resolve these issues, we build new benchmarks on three datasets: PASCAL VOC, COCO and LVIS. We sample different groups of few-shot training examples for multiple runs of the experiments to obtain a stable accuracy estimation and quantitatively analyze the variances of different evaluation metrics. The new evaluation reports the average precision (AP) on both the base classes and novel classes as well as the mean AP on all classes, referred to as the generalized few-shot learning setting in the few-shot classification literature.
为了解决这些问题,我们在三个数据集上建立了新的基准:Pascal VOC、COCO和LVIS。为了获得稳定的精度估计,我们对不同组的少镜头训练样本进行了多次实验采样,并对不同评价指标的方差进行了定量分析。新的评估报告了基类和新类的平均精度(AP)以及所有类的平均AP,在少镜头分类文献中被称为广义的少镜头学习设置。
Our fine-tuning approach establishes new states of the art on the benchmarks. On the challenging LVIS dataset, our two-stage training scheme improves the average detection precision of rare classes (<10 images) by ~4 points and common classes (10-100 images) by ~2 points with negligible precision loss for the frequent classes (>100 images).
我们的微调方法在基准方面建立了新的艺术状态。在具有挑战性的LVIS数据集上,我们的两阶段训练方案将稀有类(<10 images) 的平均检测精度提高了4个点,将普通类 (10-100 images) 的平均检测精度提高了2个点,而对常见类(>100 images)的检测精度损失可以忽略不计。
2. Related Work
Our work is related to the rich literature on few-shot image classification, which uses various meta-learning based or metric-learning based methods. We also draw connections between our work and the existing meta-learning based fewshot object detection methods. To the best of our knowledge, we are the first to conduct a systematic analysis of finetuning based approaches on few-shot object detection.
我们的工作涉及到大量关于少镜头图像分类的文献,这些文献使用了各种基于元学习或基于度量学习的方法。我们还将我们的工作与现有的基于元学习的少数镜头目标检测方法联系起来。据我们所知,这是第一个对基于微调的few-shot目标检测方法进行系统分析的方案。
Meta-learning. The goal of meta-learning is to acquire task-level meta knowledge that can help the model quickly adapt to new tasks and environments with very few labeled examples. Some learn to fine-tune and aim to obtain a good parameter initialization that can adapt to new tasks with a few scholastic gradient updates. Another popular line of research on meta-learning is to use parameter generation during adaptation to novel tasks. Gidaris & Komodakis (2018) propose an attention-based weight generator to generate the classifier weights for the novel classes. Wang et al. (2019a) construct task-aware feature embeddings by generating parameters for the feature layers. These approaches have only been used for few-shot image classification and not on more challenging tasks like object detection.
**Meta-learning.**元学习的目标是获得任务级的元知识,这些知识可以帮助模型快速适应新的任务和环境,而不需要很少的标记样本。一些人学习微调,目标是通过一些学术上的渐变更新来获得能够适应新任务的良好参数初始化。元学习的另一个热门研究方向是在适应新任务的过程中使用参数生成。Gidaris&Komodakis(2018)提出了一种基于注意力的权重生成器来生成新类别的分类器权重。Wang等人(2019a)通过为特征层生成参数来构建任务感知特征嵌入。这些方法只被用于少镜头图像分类,而不用于更具挑战性的任务,如目标检测。
However, some raise concerns about the reliability of the results given that a consistent comparison of different approaches is missing. Some simple fine-tuning based approaches, which draw little attention in the community, turn out to be more favorable than many prior works that use meta-learning on few-shot image clas-sification . As for the emerging few-shot object detection task, there is neither consensus on the evaluation benchmarks nor a consistent comparison of different approaches due to the increased network complexity, obscure implementation details, and variances in evaluation protocols.
然而,一些人对结果的可靠性表示担忧,因为缺乏对不同方法的一致比较。一些简单的基于微调的方法在社区中很少引起关注,但事实证明,与许多使用元学习进行少镜头图像分类的工作相比,这种方法更有利。对于新出现的少镜头目标检测任务,由于网络复杂性增加、实现细节模糊以及评估协议的差异,对评估基准没有达成共识,也没有对不同方法进行一致的比较。
Metric-learning. Another line of work focuses on learning to compare or metric-learning. Intuitively, if the model can construct distance metrics to estimate the similarity between two input images, it may generalize to novel categories with few labeled instances. More recently, several adopt a cosine similarity based classifier to reduce the intraclass variance on the few-shot classification task, which leads to favorable performance compared to many metalearning based approaches. Our method also adopts a cosine similarity classifier to classify the categories of the region proposals. However, we focus on the instance-level distance measurement rather than on the image level.
Metric-learning. 另一种工作专注于学习比较或度量学习。直观地说,如果模型可以构造距离度量来估计两个输入图像之间的相似度,它就可以推广到具有很少标记实例的新类别。最近,一些方法采用了基于余弦相似度的分类器,以减少少次射击分类任务中的类内方差,这导致了与许多基于金属获取的方法相比更好的性能。该方法还采用余弦相似度分类器对区域建议的类别进行分类。然而,我们关注的是实例级距离度量,而不是图像级。
Few-shot object detection. There are several early attempts at few-shot object detection using meta-learning.Kang (2019) and Yan apply featurere-weighting schemes to a single-stage object detector (YOLOv2) and a two-stage object detector (Faster R-CNN), with the help of a meta learner that takes the support images as well as the bounding box annotations as inputs.Wang propose a weight prediction meta-model to predict parameters of category-specific components from the few examples while learning the category-agnostic components from base class examples.
Few-shot object detection. 基于元学习的少镜头目标检测已经有了一些早期的尝试,Kang(2019)和Yanen将特征加权方案应用于单级目标检测器(YOLOv2)和两级目标检测器(FASTER R-CNN),并在元学习器的帮助下将支持图像和包围盒注释作为输入。Wang等人提出了一种权重预测元模型,用于从少数几个示例中预测类别特定组件的参数,同时从基类示例中学习类别无关组件。
In all these works, fine-tuning based approaches are considered as baselines with worse performance than metalearning based approaches. They consider jointly finetuning, where base classes and novel classes are trained together, and fine-tuning the entire model, where the detector is first trained on the base classes only and then fine-tuned on a balanced set with both base and novel classes. In contrast, we find that fine-tuning only the last layer of the object detector on the balanced subset and keeping the rest of model fixed can substantially improve the detection accuracy, outperforming all the prior meta-learning based approaches.This indicates that feature representations learned from the base classes might be able to transfer to the novel classes and simple adjustments to the box predictor can provide strong performance gain.
在所有这些工作中,基于微调的方法被认为是性能比基于元学习的方法差的基线。他们考虑联合微调,其中基类和新类一起训练,并微调整个模型,其中检测器首先仅在基类上训练,然后在基类和新类的平衡集上微调。相比之下,我们发现,仅微调平衡子集上的对象检测器的最后一层,并保持模型的其余部分固定,可以大大提高检测精度,优于所有先前的基于元学习的方法。这表明从基类学习到的特征表示可能能够转移到新类,并且对盒预测器的简单调整可以提供强大的性能增益。
3. Algorithms for Few-Shot Object Detection
In this section, we start with the preliminaries on the fewshot object detection setting. Then, we talk about our two stage fine-tuning approach in Section 3.1. Section 3.2 summarizes the previous meta-learning approaches.
在这一节中,我们先介绍一下少数镜头对象检测设置。然后,我们在3.1节中讨论我们的两阶段微调方法。3.2节总结了以前的元学习方法。
We follow the few-shot object detection settings introduced in Kang et al. There are a set of base classes Cb that have many instances and a set of novel classes Cn that have only K (usually less than 10) instances per category. For an object detection dataset D = f(x; y); x 2 X ; y 2 Yg, where x is the input image and y = f(ci; li); i = 1; :::; Ng denotes the categories c 2 Cb [ Cn and bounding box coordinates l of the N object instances in the image x. For synthetic few-shot datasets using PASCAL VOC and COCO, the novel set for training is balanced and each class has the same number of annotated objects (i.e., K-shot). The recent LVIS dataset has a natural long-tail distribution, which does not have the manual K-shot split. The classes in LVIS are divided into frequent classes (appearing in more than 100 images), common classes (10-100 images), and rare classes (less than 10 images). We consider both synthetic and natural datasets in our work and follow the naming convention of k-shot for simplicity.
我们遵循Kang等人介绍的少数镜头对象检测设置。有一组具有许多实例的基础类Cb和一组每个类别只有K个(通常少于10个)实例的新类Cn。对于对象检测数据集D = {(x,y),x∈X,y∈Y},其中x是输入图像,y = {(ci,li), i =1,2,…,N}表示图像x中N个对象实例的类别c∈Cb∪Cn和边界框坐标l。对于使用PASCAL VOC和COCO的合成少镜头数据集,用于训练的新集合是平衡的,并且每个类别具有相同数量的注释对象(即,K-shot)。最近的LVIS数据集具有自然的长尾分布,其不具有手动的K-shot分割。LVIS的类分为频繁类(出现在超过100幅图像中)、普通类(10-100图像)和罕见类(少于10幅图像)。我们在工作中考虑了合成和自然数据集,为了简单起见,我们遵循k-shot的命名约定。
The few-shot object detector is evaluated on a test set of both the base classes and the novel classes. The goal is to optimize the detection accuracy measured by average precision (AP) of the novel classes as well as the base classes. This setting is different from the N-way-K-shot setting commonly used in few-shot classification.
在基本类和新类的测试集上评估few-shot对象检测器。这个目标是优化由新类别和基本类别的平均精度(AP)测量的检测精度。此设置与few-shot分类中常用的N路K镜头设置不同。
3.1. Two-stage fine-tuning approach
We describe our two-stage fine-tuning approach (TFA) for few-shot object detection in this section. We adopt the widely used Faster R-CNN, a two-stage object detector, as our base detection model. As shown in Figure 1, the feature learning components, referred to as F, of a Faster R-CNN model include the backbone (e.g, ResNet, VGG16), the region proposal network (RPN), as well as a two layer fully-connected (FC) sub-network as a proposal-level feature extractor. There is also a box predictor composed of a box classifier C to classify the object categories and a box regressor R to predict the bounding box coordinates.Intuitively, the backbone features as well as the RPN features are class-agnostic. Therefore, features learned from the base classes are likely to transfer to the novel classes without further parameter updates. The key component of our method is to separate the feature representation learning and the box predictor learning into two stages.
在这一节中,我们描述了用于few-shot对象检测的两阶段微调方法(TFA)。我们采用广泛使用的 Faster R-CNN,一种两阶段目标检测器,作为我们的基本检测模型。如图1所示,快速R-CNN模型的特征学习组件(称为F)包括主干(例如ResNet、VGG16)、区域提议网络(RPN)以及作为提议级特征提取器的双层全连接(FC)子网络。还有一个由 box分类器C和 box回归器R组成的盒子预测器,盒子分类器C用于分类对象类别,盒子回归器R用于预测边界盒子坐标。直观地说,主干特性和RPN特性是与类别无关的。因此,从基类学到的特征很可能转移到新类,而无需进一步的参数更新。我们的方法的关键部分是特征表示学习和box预测器学习。
Base model training. In the first stage, we train the feature extractor and the box predictor only on the base classes Cb, with the same loss function used in Ren et al. (2015). The joint loss is,
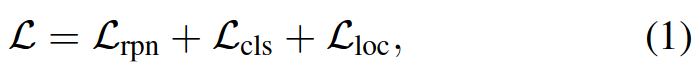
where Lrpn is applied to the output of the RPN to distinguish foreground from backgrounds and refine the anchors, Lcls is a cross-entropy loss for the box classifier C, and Lloc is a smoothed L1 loss for the box regressor R.
**Base model training.**在第一阶段,我们仅在基类Cb上训练特征提取器和盒预测器,使用与Ren et al. (2015)中使用的相同的损失函数。联合损失是,
其中,Lrpn应用于rpn的输出,以区分前景和背景并细化anchors框,Lcls是盒分类器C的交叉熵损失,Lloc是box回归器R的平滑L1损失。
Few-shot fine-tuning. In the second stage, we create a small balanced training set with K shots per class, containing both base and novel classes. We assign randomly initialized weights to the box prediction networks for the novel classes and fine-tune only the box classification and regression networks, namely the last layers of the detection model, while keeping the entire feature extractor F fixed.
We use the same loss function in Equation 1 and a smaller learning rate. The learning rate is reduced by 20 from the first stage in all our experiments.
Few-shot fine-tuning. 在第二阶段,我们创建一个小的平衡训练集,每个类有K个shots,包含基本类和新类。我们为新类别的 box预测网络分配随机初始化的权重,并且仅微调盒分类和回归网络,即检测模型的最后层,同时保持整个特征提取器F固定。我们在等式1中使用相同的损失函数和较小的学习率。在我们所有的实验中,学习率比第一阶段降低了20。
Cosine similarity for box classifier. We consider using a classifier based on cosine similarity in the second fine-tuning stage, inspired by Gidaris & Komodakis (2018); Qi et al.(2018); Chen et al. (2019). The weight matrix W∈Rd×c of the box classifier C can be written as [w1,w2, …, wc], where wc∈Rd is the per-class weight vector. The output of C is scaled similarity scores S of the input feature F(x) and the weight vectors of different classes. The entries in S are
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fa29rTuY-1666404829598)(目标检测笔记_img/image-20221010213716124.png)]](https://img-blog.csdnimg.cn/01457e9096fd41f1868bbf8a25deb4dd.png)
where si,j is the similarity score between the i-th object proposal of the input x and the weight vector of class j. α is the scaling factor. We use a fixed α of 20 in our experiments.We find empirically that the instance-level feature normalization used in the cosine similarity based classifier helps reduce the intra-class variance and improves the detection accuracy of novel classes with less decrease in detection accuracy of base classes when compared to a FC-based classifier, especially when the number of training examples is small.
Cosine similarity for box classifier. 我们考虑在第二个微调阶段使用基于余弦相似度的分类器,灵感来自Gidaris & Komodakis(2018);齐等(2018);陈等(2019)。箱式分类器C的权重矩阵W∈Rd×c可以写成[w1,w2,…,wc],其中wc∈Rd是每类权重向量。C的输出是输入特征F(x)的缩放相似性得分S 与 不同类别的权重向量。S公式如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j1gIMnGz-1666404829598)(目标检测笔记_img/image-20221010213905781.png)]](https://img-blog.csdnimg.cn/2a9953ae060c48a6bc61d4eb340e09fb.png)
其中si,j是输入x的第I个对象提议和类j的权重向量之间的相似性得分,α是缩放因子。我们在实验中使用20的固定α。我们根据经验发现,在基于余弦相似性的分类器中使用的实例级特征归一化有助于降低类内方差,并提高novel 类的检测精度,与基于FC的分类器相比,基本类的检测精度降低较少,特别是当训练实例的数量较少时。
3.2. Meta-learning based approaches
We describe the existing meta-learning based few-shot object detection networks, including FSRW , Meta R-CNN and MetaDet , in this section to draw comparisons with our approach. Figure 2 illustrates the structures of these networks.In meta-learning approaches, in addition to the base object detection model that is either single-stage or two-stage, a meta-learner is introduced to acquire class-level meta knowledge and help the model generalize to novel classes through feature re-weighting, such as FSRW and Meta R-CNN, or class-specific weight generation, such as MetaDet. The input to the meta learner is a small set of support images with the bounding box annotations of the target objects.
在本节中,我们描述了现有的基于元学习的少镜头对象检测网络,包括FSRW、Meta R-CNN和MetaDet,以便与我们的方法进行比较。图2说明了这些网络的结构。在元学习方法中,除了单阶段或两阶段的基本对象检测模型之外,还引入了元学习器来获取类级别的元知识,并通过特征重新加权(如FSRW和Meta R-CNN)或特定于类的权重生成(如MetaDet)来帮助模型概括到新的类。元学习器的输入是一小组带有目标对象的边界框注释的支持图像。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Jx61nGoX-1666404829599)(目标检测笔记_img/image-20221010214328445.png)]](https://img-blog.csdnimg.cn/4aefc6fcd54e43419ef32f99d2822121.png)
Figure 2. Abstraction of the meta-learning based few-shot object detectors. A meta-learner is introduced to acquire task-level meta information and help the model generalize to novel classes through feature re-weighting (e.g., FSRW and Meta R-CNN) or weight generation (e.g., MetaDet). A two-stage training approach (meta-training and meta fine-tuning) with episodic learning is commonly adopted.
图二。基于元学习的few-shot目标检测器的抽象。引入元学习器来获取任务级元信息,并通过特征重新加权(例如,FSRW和Meta R-CNN)或权重生成(例如,MetaDet)来帮助模型概括成新的类。通常采用带有情景学习的两阶段培训方法(元培训和元微调)。
The base object detector and the meta-learner are often jointly trained using episodic training .Each episode is composed of a supporting set of N objects and a set of query images. In FSRW and Meta R-CNN, the support images and the binary masks of the annotated objects are used as input to the meta-learner, which generates class reweighting vectors that modulate the feature representation of the query images. As shown in Figure 2,the training procedure is also split into a meta-training stage, where the model is only trained on the data of the base classes, and a meta fine-tuning stage, where the support set includes the few examples of the novel classes and a subset of examples from the base classes.
基本对象检测器和元学习器通常使用情节训练来联合训练。每集由N个对象的支持集和一组查询图像组成。在FSRW和Meta R-CNN中,支持图像和注释对象的二进制掩码被用作元学习器的输入,元学习器生成调整查询图像的特征表示的类重新加权向量。如图2所示,训练过程也被分成元训练阶段和元微调阶段,在元训练阶段,模型仅在基类的数据上被训练,在元微调阶段,支持集包括新类的几个例子和来自基类的例子的子集。
Both the meta-learning approaches and our approach have a two-stage training scheme. However, we find that the episodic learning used in meta-learning approaches can be very memory inefficient as the number of classes in the supporting set increases. Our fine-tuning method only finetunes the last layers of the network with a normal batch training scheme, which is much more memory efficient.
元学习方法和我们的方法都有一个两阶段的培训方案。然而,我们发现,随着支持集中类别数量的增加,元学习方法中使用的情景学习可能会导致内存效率非常低。我们的微调方法只对网络的最后几层进行微调,使用正常的批量训练方案,这比传统的批处理训练方案更有效。
4. Experiments
In this section, we conduct extensive comparisons with previous methods on the existing few-shot object detection benchmarks using PASCAL VOC and COCO, where our approach can obtain about 2~20 points improvement in all settings (Section 4.1). We then introduce a new benchmark on three datasets (PASCAL VOC, COCO and LVIS) with revised evaluation protocols to address the unreliability of previous benchmarks (Section 4.2). We also provide various ablation studies and visualizations in Section 4.3.
在这一部分中,我们使用Pascal VOC和COCO对现有的few-shot目标检测基准进行了广泛的比较,在所有设置下,我们的方法可以获得大约2~20个点的改进(4.1节)。然后,我们在三个数据集(Pascal VOC、COCO和LVIS)上引入了一个新的基准,并修订了评估协议,以解决以前基准的不可靠性(第4.2节)。我们还在第4.3节中提供了各种消融研究和可视化。
Implementation details. We use Faster R-CNN as our base detector and Resnet-101 with a Feature Pyramid Network as the backbone. All models are trained using SGD with a minibatch size of 16, momentum of 0.9, and weight decay of 0.0001. A learning rate of 0.02 is used during base training and 0.001 during few-shot fine-tuning.
实现细节。我们使用Faster R-CNN作为基础探测器,以具有金字塔网络功能的RESNET-101为主干。所有模型都使用SGD进行训练,小批量为16,动量为0.9%,重量衰减率为0.0001。在基础训练中使用0.02%的学习率,在少发微调时使用0.001的学习率。
4.1. Existing few-shot object detection benchmark
Existing benchmarks. Following the previous work, we first evaluate our approach on PASCAL VOC 2007+2012 and COCO, using the same data splits and training examples provided by Kang et al. (2019). For the few-shot PASCAL VOC dataset, the 20 classes are randomly divided into 15 base classes and 5 novel classes, where the novel classes have K = 1,2,3,5,10 objects per class sampled from the combination of the trainval sets of the 2007 and 2012 versions for training. Three random split groups are considered in this work. PASCAL VOC 2007 test set is used for evaluation. For COCO, the 60 categories disjoint with PASCAL VOC are used as base classes while the remaining 20 classes are used as novel classes with K = 10,30. For evaluation metrics, AP50 (matching threshold is 0.5) of the novel classes is used on PASCAL VOC and the COCO-style AP of the novel classes is used on COCO.
Existing benchmarks. 在前面的工作之后,我们首先使用Kang等人提供的相同数据拆分和训练示例,在Pascal VOC 2007+2012和COCO上评估我们的方法。(2019年)。对于few-shot 的Pascal VOC数据集,20个类被随机分为15个基类和5个novel类,其中novel类具有从用于训练的2007和2012版本的Trainal集的组合中采样的每个类的K=1、2、3、5、10个对象。本工作考虑了三个随机分裂群。使用Pascal VOC 2007测试集进行评估。对于COCO,与Pascal VOC不相交的60个类别被用作基类,而剩余的20个类别被用作K=10,30的新类别。对于评价指标,novel类的AP50(匹配阈值为0.5)用于Pascal VOC,新类的COCO风格的AP用于COCO。
Baselines. We compare our approach with the metalearning approaches FSRW, Meta-RCNN and MetaDet together with the fine-tuning based approaches: jointly training, denoted by FRCN/YOLO+joint, where the base and novel class examples are jointly trained in
one stage, and fine-tuning the entire model, denoted by FRCN/YOLO+ft-full, where both the feature extractor F and the box predictor (C and R) are jointly fine-tuned until convergence in the second fine-tuning stage. FRCN is Faster R-CNN for short. Fine-tuning with less iterations, denoted by FRCN/YOLO+ft, are reported in Kang et al. (2019) and Yan et al. (2019).
Baselines. 我们将我们的方法与元学习方法FSRW、Meta-RCNN和MetaDet以及基于微调的方法进行了比较:联合训练,表示为FRCN/YOLO+Joint,其中基本和新的类样本在一个阶段联合训练,以及微调整个模型,表示为FRCN/YOLO+ft-Full,其中特征提取器F和盒预测器(C和R)都被联合微调,直到在第二微调阶段收敛。FRCN是Faster R-CNN简称。Kang等人报告了用更少迭代进行的微调,由FRCN/YOLO+ft表示。(2019)和严等人。(2019年)。
Results on PASCAL VOC. We provide the average AP50 of the novel classes on PASCAL VOC with three random splits in Table 1. Our approach uses ResNet-101 as the backbone, similar to Meta R-CNN. We implement FRCN+ft-full in our framework, which roughly matches the results reported. MetaDet uses VGG16 as the backbone, but the performance is similar and sometimes worse compared to Meta R-CNN.
Results on PASCAL VOC. 我们在表1中提供了Pascal VOC上三个随机分裂的新类的平均AP50。我们的方法使用ResNet-101作为骨干,类似于Meta R-CNN。我们在我们的框架中实现了FRCN+FT-Full,这与报告的结果大致相符。MetaDet使用VGG16作为主干,但性能与Meta R-CNN相似,有时甚至更差。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4zx8vM1g-1666404829599)(目标检测笔记_img/image-20221011102635255.png)]](https://img-blog.csdnimg.cn/8154fe59bf8c4d9b9ccae052cef84467.png)
Table 1. Few-shot detection performance (mAP50) on the PASCAL VOC dataset. We evaluate the performance on three different sets of novel classes. Our approach consistently outperforms baseline methods by a large margin (about 2~20 points), especially when the number of shots is low. FRCN stands for Faster R-CNN. TFA w/cos is our approach with a cosine similarity based box classifier.
表1.在PASCAL VOC数据集上的Few-shot检测性能(MAP50)。我们在三组不同的Few-shot类上进行了性能评估。我们的方法始终比基线方法有很大的优势(大约2~20分),特别是在拍摄次数较少的情况下。FRCN代表更快的R-CNN。TFA和CoS是我们使用基于余弦相似度的盒分类器的方法。
In all different data splits and different numbers of training shots, our approach (the last row) is able to outperform the previous methods by a large margin. It even doubles the performance of the previous approaches in the one-shot cases. The improvements, up to 20 points, is much larger than the gap among the previous meta-learning based approaches, indicating the effectiveness of our approach. We also compare the cosine similarity based box classifier (TFA +w/cos) with a normal FC-based classifier (TFA +w/fc) and find that TFA +w/cos is better than TFA +w/fc on extremely low shots (e.g., 1-shot), but the two are roughly similar when there are more training shots, e.g., 10-shot.
在所有不同的数据分割和不同数量的训练shots中,我们的方法(最后一行)能够在很大程度上超过以前的方法。它甚至将以前的方法在一次性情况下的性能提高了一倍。高达20分的改进比以往基于元学习的方法的差距要大得多,表明了我们方法的有效性。我们还比较了基于余弦相似度的盒分类器(TFA+w/cos)和基于普通FC的分类器(TFA+w/fc),发现在极低的镜头(例如,1枪)上,TFA+w/cos比TFA+w/fc更好,但当有更多的训练镜头,例如10枪时,两者大致相似。
For more detailed comparisons, we cite the numbers from Yan et al. (2019) of their model performance on the base classes in Table 2. We find that our model has a much higher average AP on the base classes than Meta R-CNN with a gap of about 10 to 15 points. To eliminate the differences in implementation details, we also report our re-implementation of FRCN+ft-full and training base only, where the base classes should have the highest accuracy as the model is only trained on the base classes examples. We find that our model has a small decrease in performance, less than 2 points, on the base classes.
为了进行更详细的比较,我们引用了Yan等人(2019)在表2中对基类的模型性能的数据。我们发现我们的模型在基础类上的平均AP比Meta R-CNN高得多,差距约为10到15点。为了消除实现细节上的差异,我们还报告了我们的FRCN+ft-full和训练基地的重新实现,其中基类应该具有最高的准确性,因为模型只在基类示例上进行训练。我们发现我们的模型在基类上有一个很小的性能下降,小于2点。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-d7tI7uO3-1666404829600)(目标检测笔记_img/image-20221011102850873.png)]](https://img-blog.csdnimg.cn/f7c3dade32594335a668e5975dcddcdb.png)
Table 2. Few-shot detection performance for the base and novel classes on Novel Set 1 of the PASCAL VOC dataset. Our approach outperforms baselines on both base and novel classes and does not degrade the performance on the base classes greatly.
表2.在PASCAL VOC数据集的新集合1上,基本类和Novel类的Few-shot 检测性能。我们的方法在基类和新类上的性能都优于基线,并且在基类上的性能没有太大的下降。
Results on COCO. Similarly, we report the average AP and AP75 of the 20 novel classes on COCO in Table 3. AP75 means matching threshold is 0.75, a more strict metric than AP50. Again, we consistently outperform previous methods across all shots on both novel AP and novel AP75. We achieve around 1 point improvement in AP over the best performing baseline and around 2.5 points improvement in AP75.
**Results on COCO.**类似地,我们在表3中报告了COCO上20个新类的平均AP和AP75。AP75意味着匹配阈值为0.75,这是一个比AP50更严格的度量。再一次,我们在新奇AP和新奇AP75上的所有shots 上的表现都始终如一地优于以前的方法。我们的AP比最佳基准提高了约1个百分点,AP75提高了约2.5个百分点。
4.2. Generalized few-shot object detection benchmark
Revised evaluation protocols. We find several issues with existing benchmarks. First, previous evaluation protocols focus only on the performance on novel classes. This ignores the potential performance drop in base classes and thus the overall performance of the network. Second, the sample variance is large due to the few samples that are used for training. This makes it difficult to draw conclusions from comparisons against other methods, as differences in performance could be insignificant.
Revised evaluation protocols. 我们发现现有基准存在几个问题。首先,以往的评估协议只关注新类的性能。这忽略了基类中潜在的性能下降,从而忽略了网络的整体性能。其次,由于用于训练的样本较少,样本方差较大。这使得很难从与其他方法的比较中得出结论,因为性能上的差异可能微不足道。
To address these issues, we first revise the evaluation protocol to include evaluation on base classes. On our benchmark,we report AP on base classes (bAP) and the overall AP in addition to AP on the novel classes (nAP). This allows us to observe trends in performance on both base and novel classes, and the overall performance of the network.
为了解决这些问题,我们首先修改了评估协议,以包括对基类的评估。在我们的基准测试中,我们报告了AP的基类(BAP)和总体AP,以及AP的新类(NAP)。这使我们能够观察基本类和新类的性能趋势,以及网络的整体性能。
Additionally, we train our models for multiple runs on different random samples of training shots to obtain averages and confidence intervals. In Figure 3, we show the cumulative mean and 95% confidence interval across 40 repeated runs with K = 1; 3; 5; 10 on the first split of PASCAL VOC.Although the performance is high on the first random sample, the average decreases significantly as more samples are used. Additionally, the confidence intervals across the first few runs are large, especially in the low-shot scenario.
When we use more repeated runs, the averages stabilizes and the confidence intervals become small, which allows for better comparisons.
此外,我们还在不同的随机训练镜头样本上训练我们的模型进行多次运行,以获得平均值和可信区间。在图3中,我们显示了在Pascal VOC的第一个拆分上,K=1;3;5;10的40次重复运行的累积平均值和95%的可信区间。尽管在第一个随机样本上的性能很高,但随着使用更多的样本,平均值会显著下降。此外,前几次比赛的可信区间很大,特别是在低射情况下。当我们使用更多的重复运行时,平均值稳定下来,可信区间变得很小,这允许进行更好的比较。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q7okkScP-1666404829600)(目标检测笔记_img/image-20221011103220242.png)]](https://img-blog.csdnimg.cn/6c85fa43344a440ab4bc2225469cf587.png)
Figure 3. Cumulative means with 95% confidence intervals across 40 repeated runs, computed on the novel classes of the first split of PASCAL VOC. The means and variances become stable after around 30 runs.
Figure 3. 累积平均值在40次重复运行中具有95%置信区间,基于PASCAL VOC第一次分割的新类计算。均值和方差在大约30次运行后趋于稳定。
Results on LVIS. We evaluate our approach on the recently introduced LVIS dataset. The number of images in each category in LVIS has a natural long-tail distribution. We treat the frequent and common classes as base classes, and the rare classes as novel classes. The base training is the same as before. During few-shot fine-tuning, we artificially create a balanced subset of the entire dataset by sampling up to 10 instances for each class and fine-tune on this subset.
Results on LVIS. 我们在最近引入的LVIS数据集上对我们的方法进行了评估。LVIS中每个类别的图像数量具有自然的长尾分布。我们把频繁的和常见的类当作基类,把稀有的类当作新的类。基地训练和以前一样。在少镜头微调期间,我们通过为每个类采样多达10个实例来人为地创建整个数据集的平衡子集,并在这个子集上进行微调。
We show evaluation results on LVIS in Table 4. Compared to the methods in Gupta et al.our approach is able to achieve better performance of 1-1.5 points in overall AP and 2-4 points in AP for rare and common classes. We also demonstrate results without using repeated sampling, which is a weighted sampling scheme that is used in Gupta et to address the data imbalance issue. In this setting, the baseline methods can only achieve 2-3 points in AP for rare classes. On the other hand, our approach is able to greatly outperform the baseline and increase the AP on rare classes by around 13 points and on common classes by around 1 point. Our two-stage fine-tuning scheme is able to address the severe data imbalance issue without needing repeated sampling.
我们在表4中显示了LVIS的评估结果。与Gupta等人的方法相比,我们的方法能够在总体AP中获得1-1.5分的更好性能,在稀有和普通类中能够获得2-4分的更好的性能。我们还演示了不使用重复采样的结果,这是Gupta et中用于解决数据不平衡问题的加权采样方案。在这种情况下,对于稀有类,基线方法只能在AP中获得2-3分。另一方面,我们的方法能够大大超越基线,将稀有类的AP提高约13点,将普通类的AP增加约1点。我们的两阶段微调方案能够解决严重的数据不平衡问题,而无需重复采样。
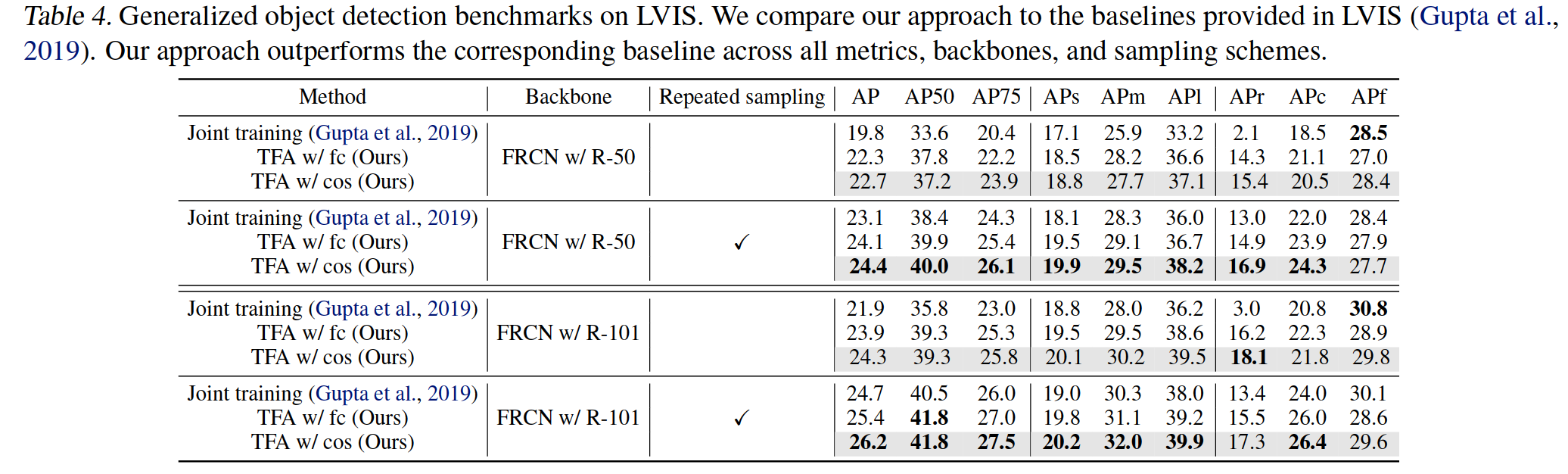
Table 4. Generalized object detection benchmarks on LVIS. We compare our approach to the baselines provided in LVIS (Gupta et al., 2019). Our approach outperforms the corresponding baseline across all metrics, backbones, and sampling schemes.
Table 4. LVIS上的通用对象检测基准。我们将我们的方法与LVIS中提供的基线进行了比较(Gupta等人,2019年)。我们的方法在所有指标、主干和采样方案中都优于相应的基线。
Results on PASCAL VOC and COCO. We show evalua-tion results on generalized PASCAL VOC in Figure 4 and COCO in Figure 5. On both datasets, we evaluate on the base classes and the novel classes and report AP scores for each. On PASCAL VOC, we evaluate our models over 30 repeated runs and report the average and the 95% confidence interval. On COCO, we provide results on 1, 2, 3, and 5 shots in addition to the 10 and 30 shots used by the existing benchmark for a better picture of performance trends in the low-shot regime. For the full quantitative results of other metrics (e.g., AP50 and AP75), more details are available in the appendix.
我们在图4和图5中分别展示了对广义PASCAL VOC和COCO的评估结果。在两个数据集上,我们对基本类和新类进行评估,并报告每个类的AP分数。在PASCAL VOC上,我们通过30次重复运行来评估我们的模型,并报告平均值和95%的置信区间。在COCO上,除了现有基准使用的10次和30次拍摄之外,我们还提供了1次、2次、3次和5次拍摄的结果,以便更好地了解低镜头范围内的性能趋势。有关其他指标(如AP50和AP75)的完整定量结果,更多详细信息请参见附录。
Results on PASCAL VOC and COCO.
4.3. Ablation study and visualization
Weight initialization. We explore two different ways of initializing the weights of the novel classifier before few-shot fine-tuning: (1) random initialization and (2) fine-tuning a predictor on the novel set and using the classifier’s weights as initialization. We compare both methods on K = 1,3,10 on split 3 of PASCAL VOC and COCO and show the results in Table 5. On PASCAL VOC, simple random initialization can outperform initialization using fine-tuned novel weights.On COCO, using the novel weights can improve the performance over random initialization. This is probably due to the increased complexity and number of classes of COCO compared to PASCAL VOC. We use random initialization for all PASCAL VOC experiments and novel initialization for all COCO and LVIS experiments.
Weight initialization. 我们探索了在少量微调之前初始化新分类器的权重的两种不同方式:(1)随机初始化和(2)在新集合上微调预测器并使用分类器的权重作为初始化。我们在PASCAL VOC和COCO的split 3上比较了K = 1,3,10的两种方法,结果如表5所示。在PASCAL VOC上,简单的随机初始化可以胜过使用微调的新权重的初始化。在COCO上,使用新的权重可以提高随机初始化的性能。这可能是由于与PASCAL VOC相比,COCO的复杂性和类的数量增加了。我们对所有PASCAL VOC实验使用随机初始化,对所有COCO和LVIS实验使用新颖初始化。
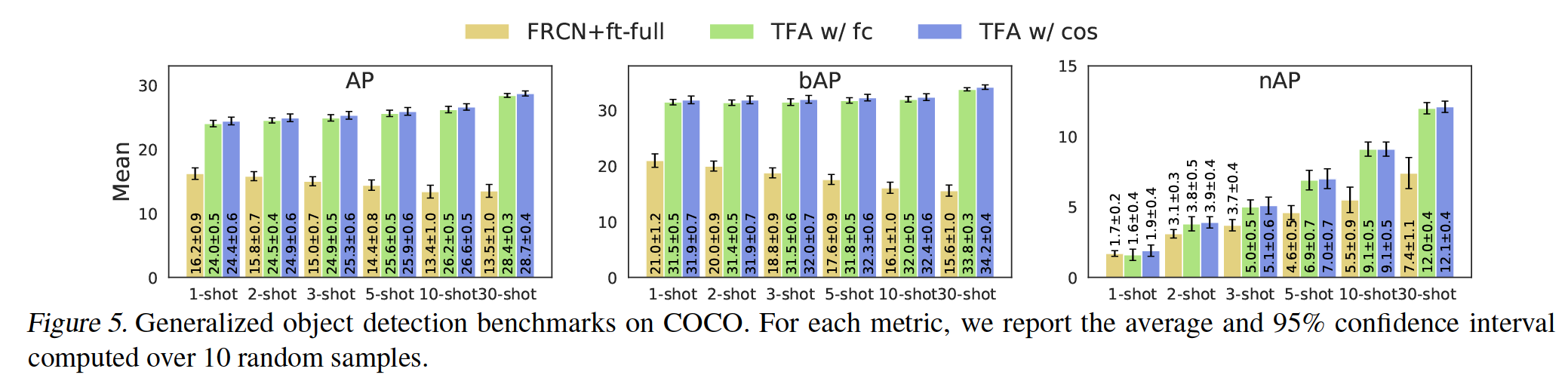
Figure 5. Generalized object detection benchmarks on COCO. For each metric, we report the average and 95% confidence interval computed over 10 random samples.
Figure 5. COCO上的广义对象检测基准。对于每个指标,我们报告平均值和在10个随机样本上计算的95%置信区间。
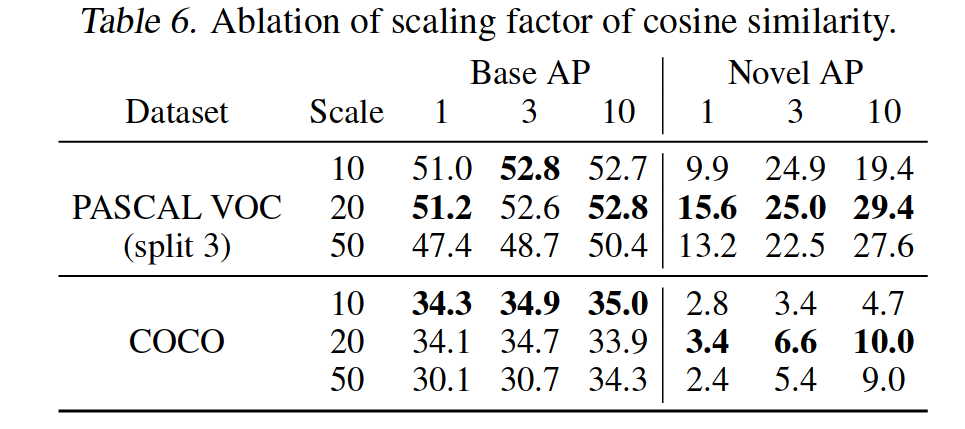
Scaling factor of cosine similarity. We explore the effect of different scaling factors for computing cosine similarity.We compare three different factors, α= 10; 20; 50. We use the same evaluation setting as the previous ablation study and report the results in Table 6. On PASCAL VOC, α= 20 outperforms the other scale factors in both base AP and novel AP. On COCO, α= 20 achieves better novel AP at the cost of worse base AP. Since it has the best performance on novel classes across both datasets, we use α= 20 in all of our experiments with cosine similarity.
Scaling factor of cosine similarity. 探讨了不同尺度因子对余弦相似度计算的影响,比较了α=10;20;50这三种不同的尺度因子。我们使用与上一次消融研究相同的评估设置,并在表6中报告了结果。在Pascal VOC上,α=20在基础AP和新型AP中都优于其他标度因数。在CoCO上,α=20以较差的基础AP为代价获得较好的新颖AP。由于它在两个数据集中的新类上具有最好的性能,因此我们在所有实验中使用余弦相似度α=20。
Detection results. We provide qualitative visualizations of the detected novel objects on PASCAL VOC and COCO in Figure 6. We show both success (green boxes) and failure cases (red boxes) when detecting novel objects for each dataset to help analyze the possible error types. On the first split of PASCAL VOC, we visualize the results of our 10-shot TFA w/ cos model. On COCO, we visualize the results of the 30-shot TFA w/cos model. The failure cases include misclassifying novel objects as similar base objects, e.g., row 2 columns 1, 2, 3, and 4, mislocalizing the objects, e.g., row 2 column 5, and missing detections, e.g., row 4 columns 1 and 5.
Detection results. 我们在图6中提供了在Pascal VOC和Coco上检测到的新对象的定性可视化。我们显示了在为每个数据集检测新对象时的成功案例(绿框)和失败案例(红框),以帮助分析可能的错误类型。在Pascal VOC的第一次拆分中,我们可视化了我们的10次TFA w/CoS模型的结果。在CoCO上,我们可视化了30次TFA w/CoS模型的结果。失败情况包括将新对象错误分类为类似的基本对象,例如行2列1、2、3和4,错位对象,例如行2列5,以及遗漏检测,例如行4列1和5。
5. Conclusion
We proposed a simple two-stage fine-tuning approach for few-shot object detection. Our method outperformed the previous meta-learning methods by a large margin on the current benchmarks. In addition, we built more reliable benchmarks with revised evaluation protocols. On the new benchmarks, our models achieved new states of the arts, and on the LVIS dataset our models improved the AP of rare classes by 4 points with negligible reduction of the AP of frequent classes.
我们提出了一种简单的两阶段微调方法来检测few-shot目标。在目前的基准测试中,我们的方法比以前的元学习方法有很大的优势。此外,我们通过修订的评估方案建立了更可靠的基准。在新的基准上,我们的模型达到了新的艺术水平,在LVIS数据集上,我们的模型将稀有类的AP提高了4个点,而对频繁类的AP的降低可以忽略不计。
ACKNOWLEDGMENTS
This work was supported by Berkeley AI Research, RISE Lab, Berkeley DeepDrive and DARPA.
这项工作得到了伯克利人工智能研究公司、Rise Lab、伯克利DeepDrive和DARPA的支持。
VOC数据集复现方法:
版权归原作者 LiBiGo 所有, 如有侵权,请联系我们删除。