
使用PyTorch进行知识蒸馏的代码示例
在本文中,我们将探索知识蒸馏的概念,以及如何在PyTorch中实现它。
AI遮天传 DL-深度学习在自然语言中的应用
AI遮天传 DL-深度学习在自然语言中的应用
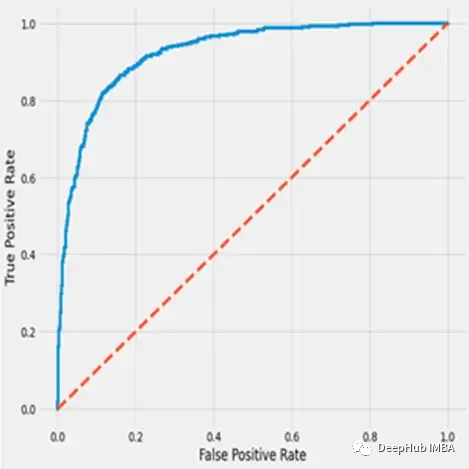
从另外一个角度解释AUC
AUC到底代表什么呢,我们从另外一个角度解释AUC
人工智能前沿——6款AI绘画生成工具
AI不仅影响商业和医疗保健等行业,还在创意产业中发挥着越来越大的作用,开创了AI绘画生成器新时代。在绘画领域当然也是如此,与传统的绘画工具不同,AI人工智能时代的绘画工具是全自动的、智能的。小海带本期将给大家介绍6款AI绘画生成工具,供大家学习交流。
Grad-CAM简介
对于常用的深度学习网络(例如CNN),可解释性并不强(至少现在是这么认为的),它为什么会这么预测,它关注的点在哪里,我们并不知道。很多科研人员想方设法地去探究其内在的联系,也有很多相关的论文。今天本文简单聊一聊Grad-CAM,这并不是一篇新的文章,但很有参考意义。通过Grad-CAM我们能够绘制出
YOLOv7训练自己的数据集(超详细)
YOLOv7训练自己的数据集(超详细)
学习笔记:深度学习(3)——卷积神经网络(CNN)理论篇
深度学习笔记——CNN卷积神经网络理论篇。主要包括CNN的概念、基本原理、类型综述。算是比较完善的一篇文章了。
Swin-Transformer网络结构详解
文章目录0 前言1 网络整体框架2 Patch Merging详解3 W-MSA详解Ω(MSA)\Omega (MSA)Ω(MSA)模块计算量Ω(W−MSA)\Omega (W-MSA)Ω(W−MSA)模块计算量4 SW-MSA详解5 Relative Position Bias详解6 模型详细配

基于Vision Transformers的文档理解简介
文档理解是从pdf、图像和Word文档中提取关键信息的技术。这篇文章的目标是提供一个文档理解模型的概述。
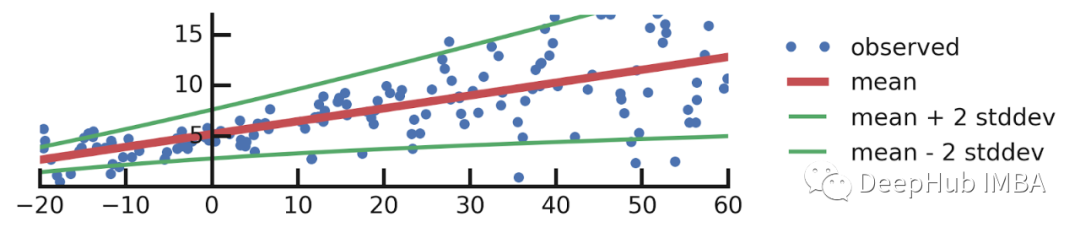
使用TensorFlow Probability实现最大似然估计
TensorFlow Probability是一个构建在TensorFlow之上的Python库。它将我们的概率模型与现代硬件(例如GPU)上的深度学习结合起来。
AI遮天传 DL-反馈神经网络RNN
AI遮天传 DL-反馈神经网络

NeurIPS 2022-10大主题、50篇论文总结
2672篇主要论文,63场研讨会,7场受邀演讲,包括语言模型、脑启发研究、扩散模型、图神经网络……NeurIPS包含了世界级的AI研究见解,本文将对NeurIPS 2022做一个全面的总结。
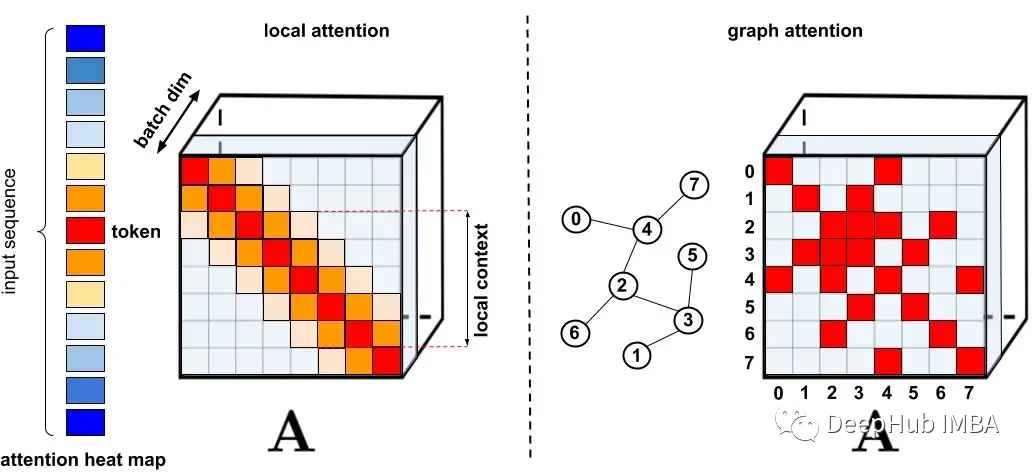
论文推荐:Rethinking Attention with Performers
重新思考的注意力机制,Performers是由谷歌,剑桥大学,DeepMind,和艾伦图灵研究所发布在2021 ICLR的论文已经超过500次引用
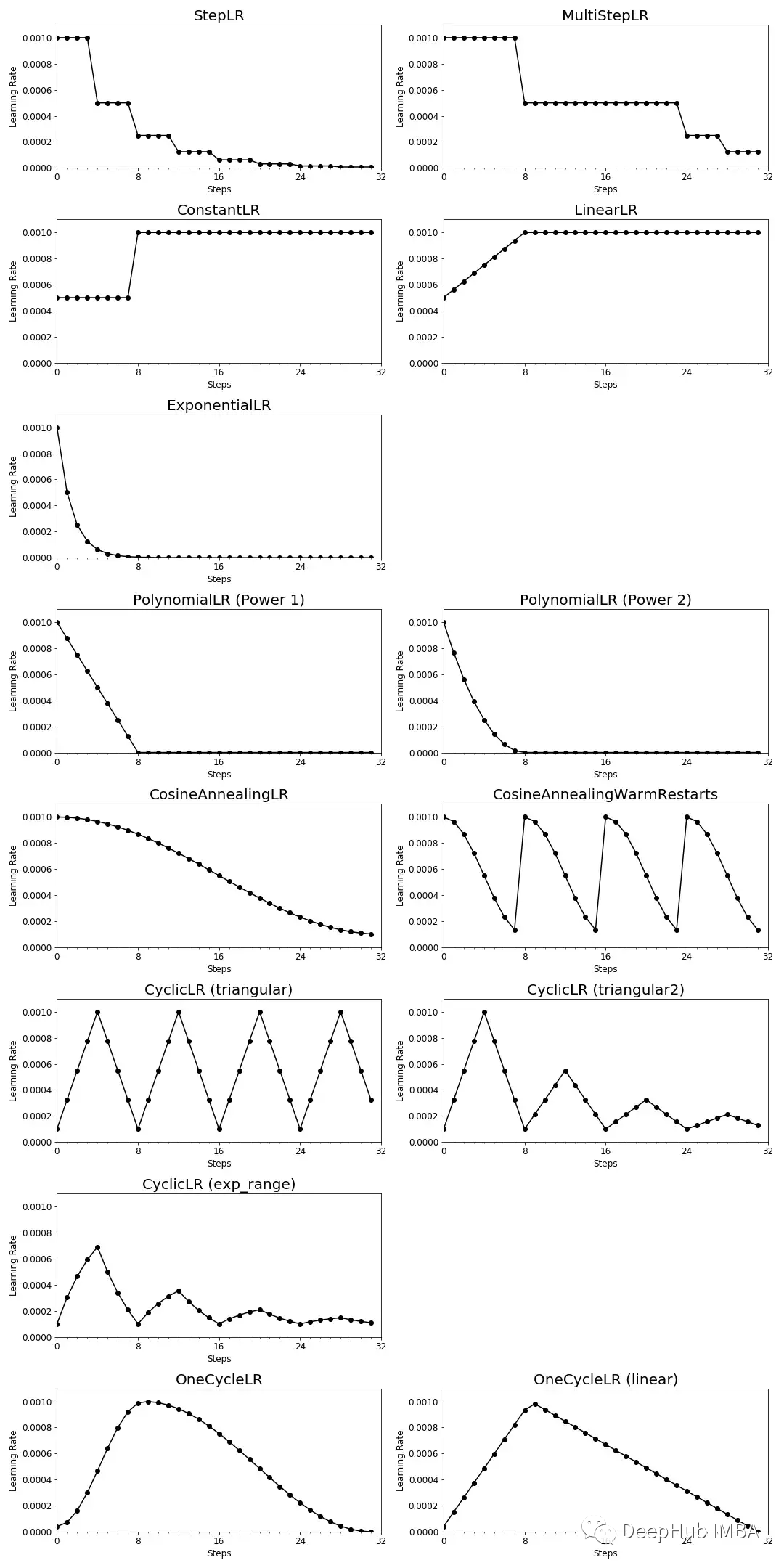
PyTorch中学习率调度器可视化介绍
学习率调度器有很多个,并且我们还可以自定义调度器。本文将介绍PyTorch中不同的预定义学习率调度器如何在训练期间调整学习率
DEFORMABLE DETR详解
transformer组件在处理图像特征图中的不足。在初始化时,注意模块对特征图中的所有像素施加了几乎一致的注意权重。长时间的训练周期是为了学习注意权重,以关注稀疏的有意义的位置。另一方面,transformer编码器中的注意权值计算是二次计算w.r.t.像素数。因此,处理高分辨率的特征映射具有非常
深度学习 Transformer架构解析
2018年10月,Google发出一篇论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》, BERT模型横空出世, 并横扫NLP领域11项任务的最佳成绩!而在BERT中发挥重要作用的
pytorch模型(.pt)转onnx模型(.onnx)的方法详解(1)
pytorch模型(.pt)转onnx模型(.onnx)的方法详解(1)
基于SARIMA、XGBoost和CNN-LSTM的时间序列预测对比
本文将讨论通过使用假设测试、特征工程、时间序列建模方法等从数据集中获得有形价值的技术。我还将解决不同时间序列模型的数据泄漏和数据准备等问题,并且对常见的三种时间序列预测进行对比测试。
人工智能与机器学习
主要介绍了人工智能与机器学习的概念,机器学习的流程,机器学习分类等。
图像数据的特征工程
总结了常用的图像特征工程,裁剪,灰度化,RGB通道选择,强度阈值,边缘检测和颜色过滤器



