
一.基础环境
windows 10
cuda 10.0
python3.7.4
tensorflow-gpu 1.14.0
keras2.2.4
numpy==1.16.5
二.下载keras-yolo3代码
从github上下载:
https://github.com/qqwweee/keras-yolo3
代码解构如下:
三.下载权重并测试
本项目所用权重文件:
权重文件
官方提供的地址:
yolov3.weights
yolov3-tiny.weights
共有两个权重文件 yolov3.weights 和 yolov3-tiny.weights, 原始代码以 yolov3.weights 为基础,我们先进行一下测试, 我们需要将 darknet 下的 yolov3 配置文件转换成 keras 适用的 h5 文件, 根目录下执行命令:
python convert.py yolov3.cfg yolov3.weights model_data/yolo_weights.h5
输出如下命令则代表执行成功, model_data文件夹下会生成 yolo_weights.h5 文件:

进行图片测试, 项目根目录cmd下执行:
python yolo_video.py --image
输入图片位置:
输出:
则原模型运行成功
四.利用 yolov3-tiny 模型进行训练
口罩识别中, 我们采用 yolov3-tiny.weights 作为基础权重, 以增加些训练和测试时的速度
将 yolov3-tiny.weights 复制到项目的根目录下。
我们需要将 darknet 下的 yolov3 文件转换成 keras 适用的 h5 文件, 跟yolov3.weights转换一样,根目录下执行命令:
python convert.py yolov3-tiny.cfg yolov3-tiny.weights model_data/tiny_yolo_weights.h5
在进行测试前,我们需要修改下代码,将yolo.py对应的文件地址修改一下: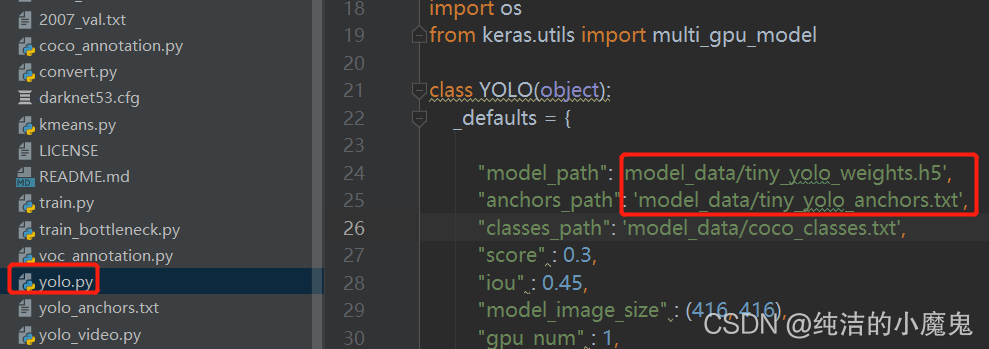
进行图片测试, 项目根目录cmd下执行:
python yolo_video.py --image
输入图片位置:
发现可以进行测试,只是效果远远不如 yolov3.weights,但是速度上是有优势的, 我们就基于yolov3-tiny 进行再训练。
五.准备训练数据
1.数据标注
我们可以从网上找一些数据口罩的数据进行标注,可以使用便标注软件labelImg
github地址:labelImg源码 下载后进行编译即可
编译后的下载地址: labelImg软件
利用软件进行标注:
注:我们采用voc的数据样式就行, 其他一些框架也可以用
2.创立文件夹
在根目录创建 VOCdevkit 文件夹, 再在该文件夹下创建 VOC2007 文件夹, 再在 VOC2007 文件夹下创建 Annotations、ImageSets、JPEGImages文件夹, 再在 ImageSets 文件夹下创建 Main 文件夹,目录格式如下:
其中 Annotations 中放标注文件,JPEGImages 为原始图片

3.分割数据集
在 VOC2007 文件夹下建立文件 voc_yolo.py 运行代码划分训练集:
"""
拆分数据集为 训练集、测试集、验证集
"""import os
import random
# 一. 设置数据集比例# 训练集的比率
train_percent =0.8# 测试集占测试验证集的百分比
test_other_percent =0.5# 二. 获取训练集,验证集和测试集的索引列表# 标注数据地址
voc_annotations_path ='Annotations'# 划分数据集的文件位置
division_data_path ='ImageSets/Main'# 获取所有的 标注数据 名称列表
voc_annotations_list = os.listdir(voc_annotations_path)# 所有标注数据的个数
voc_annotations_cnt =len(voc_annotations_list)# 生成 文件个数大小 的范围, 可以看成索引列表
list_range =range(voc_annotations_cnt)# 获取训练集的个数
train_cnt =int(voc_annotations_cnt * train_percent)# 从文件中随机获取 train_cnt 个训练验证集的索引
train_index = random.sample(list_range, train_cnt)# 从文件中随机获取训练验证集的索引(全部索引与训练集做差集)
train_val_index =list(set(list(list_range)).difference(set(train_index)))# 计算需要获取的测试训练集的个数
test_val_cnt = voc_annotations_cnt - train_cnt
# 计算测试集个数
test_cnt =int(test_val_cnt * test_other_percent)# 计算验证集个数
val_cnt = test_val_cnt - test_cnt
# 测试集索引列表
test_index = random.sample(train_val_index, test_cnt)# 验证集索引列表
val_index =list(set(train_val_index).difference(set(test_index)))# 三. 将各个数据集名称写入到文件中# 训练集
train_object =open('%s/train.txt'% division_data_path,'w')# 测试集
test_object =open('%s/test.txt'% division_data_path,'w')# 验证集
val_object =open('%s/val.txt'% division_data_path,'w')
train_names =[voc_annotations_list[i][:-4]+'\n'for i in train_index]
train_object.writelines(train_names)
train_object.close()
test_names =[voc_annotations_list[i][:-4]+'\n'for i in test_index]
test_object.writelines(test_names)
test_object.close()
val_names =[voc_annotations_list[i][:-4]+'\n'for i in val_index]
val_object.writelines(val_names)
val_object.close()
ImageSets/Main下为分好的训练接、测试集、验证集的文件名。
4. 将voc格式转为yolo格式
4.1 修改 voc_annotation.py 文件class对应的类别,并执行该文件

4.2 生成三个 txt 文件, 分别记录了图片的地址和标注的点位与类别

六.修改配置文件
1. 修改 model_data 文件夹下的 coco_classes.txt 和 voc_classes.txt
修改自己要训练的类别
2. 修改 yolov3-tiny.cfg 配置文件
搜索 [yolo],修改对应位置的 classes 和 filters
classes 改为要训练的类别个数
filters = (classes + 5) * 3
yolov3-tiny.cfg 有两处 [yolo], 均按照此步骤修改
3. 修改并执行 kmeans.py 文件
修改对应位置的文件名称并执行, 按数据重新生成候选框


七.训练并测试
1.根目录下建立 logs/000 文件夹
2.修改 train.py 文件
修改对应文件位置:
**然后可以根据机器性能修改批尺寸 batch_size **
3.执行 train.py 进行训练

接下来就是耐心等待, 根据数据量大小和机器算力, 需要训练几个小时甚至几天的时间。
4.训练完成
训练完后, 在logs/000文件夹下会生成一些文件, 包括模型文件, 日志文件
我们先查看下日志, 利用 tensorboard 查看, 在根目录执行:
tensorboard --logdir=logs/000
打开网址:
http://localhost:6006/
可查看相应日志
5.测试
5.1 测试图片
根目录执行:
python yolo_video.py --image
然后输入需要检测的图片地址即可:
5.2 测试摄像头
将 yolo.py 文件中的 video_path 改为 0 即可 运行:
运行:
python yolo_video.py
八.常见异常
1.执行 yolo_video.py 或者 train.py 时报错
如果报错:
tensorflow.python.framework.errors_impl.UnknownError: 2 root error(s) found.
(0) Unknown: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
[[{{node conv2d_1/convolution}}]]
[[boolean_mask_120/GatherV2/_3383]]
(1) Unknown: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
[[{{node conv2d_1/convolution}}]]
则加上如下代码:
import tensorflow as tf
config = tf.compat.v1.ConfigProto(allow_soft_placement=True)
config.gpu_options.per_process_gpu_memory_fraction =0.7
tf.compat.v1.keras.backend.set_session(tf.compat.v1.Session(config=config))
并可以通过此代码调节GPU的使用率
2.报异常 ‘str’ object has no attribute ‘decode’
load_weights_from_hdf5_group
original_keras_version = f.attrs['keras_version'].decode('utf8')
AttributeError: 'str' object has no attribute 'decode'
重新安装 h5py 模块
pip install h5py==2.10 -i https://pypi.tuna.tsinghua.edu.cn/simple/
需要代码和数据集的童鞋评论区留下邮箱哈!!!
版权归原作者 纯洁的小魔鬼 所有, 如有侵权,请联系我们删除。