
本文主要介绍Cityscapes在语义分割方向上的理解和使用。
Cityscapes官网:官方网站

Cityscapes
简介
Cityscapes大致有两个数据集,分别为精细的标注数据集(3475张训练图像,1525张测试图像)和粗糙的标注数据集(3475+19888张额外的粗糙标注),见图1。

标题
一般只需要用到精细的部分,也就是4375+1525张图像,在官网直接下载即可,一共5000张。
数据集的原始图片为图2中所示,左边摄像头拍到的图像。共11GB。

图2 原始数据
数据集标注方法
数据集下载以后,需要通过代码文件来生成标注,需要上github下载:cityscapes数据集生成工具在下载好工具后,需要pip安装相应工具包。
pip install cityscapesscripts
在jupyter notebook中也可以输入以下代码进行安装。
!pip install cityscapesscripts
选其一即可。
将下载的工具包打开,进入到preparation文件夹,找到如下文件:打开createTrainIdLabelImages.py

在其中添加一行代码,保证能读取到你的标注文件路径。
os.environ['CITYSCAPES_DATASET'] = "你的CityScapes gtFine路径"

运行createTrainIdLabelImgs.py,即可生成如下数据集(19类)。

生成的数据集-labelTrainIds结尾的图像

原始的数据集-labelIds结尾图像(33类)
补充说明
在原始的gtFine数据集中就有的以labelIds结尾的数据:是所有类别的数据共有33类。
而在DeepLab论文中,只使用了其中19类,于是我们可以生成19类的数据集:以labelTrainIds结尾。
生成任意类别数的数据集
如果我们想生成任意类别数的数据集,可以修改工具包中的py文件。
进入工具包的helpers文件夹,找到labels.py文件,修改其中类别对应的trainId即可,把想要训练的类别标签设为1,2,3,4....,把不想要参与训练的类别标签设置为255。然后重新运行createTrainIdLabelImgs.py文件,生成新的数据集。
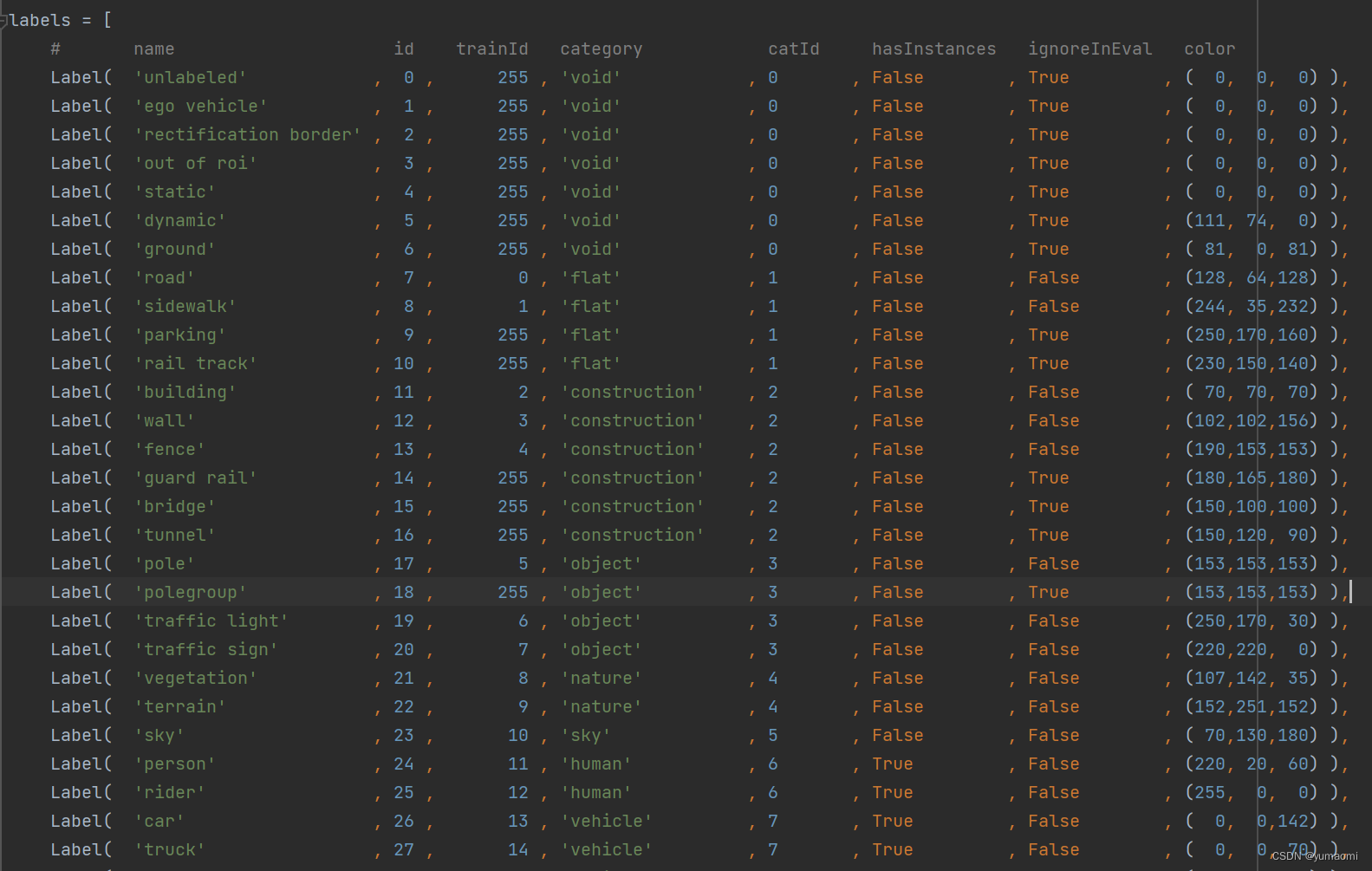
训练中需要注意的点
因为我们把不感兴趣的区域设置成为了255,所以,在定义损失函数的时候,需要设置ignore_index=255这个参数,来忽略我们不感兴趣的区域。
lossf = nn.CrossEntropyLoss(ignore_index=255)
在pytorch中构建Dataset
现在,我们有了两个文件夹,一个是leftImg8bit的原始图像文件夹,一个是gtFine标注文件夹。
现在,我们要将这两个文件夹里面的图像都提取出来,存入train、val、test文件夹中。
运行下面的代码,即可将原始图像提取并处理。
import os
import random
import shutil
# 数据集路径
dataset_path = r"dataset/cityscapes/leftImg8bit_trainvaltest/leftImg8bit"
#原始的train, valid文件夹路径
train_dataset_path = os.path.join(dataset_path,'train')
val_dataset_path = os.path.join(dataset_path,'val')
test_dataset_path = os.path.join(dataset_path,'test')
#创建train,valid的文件夹
train_images_path = os.path.join(dataset_path,'cityscapes_train')
val_images_path = os.path.join(dataset_path,'cityscapes_val')
test_images_path = os.path.join(dataset_path,'cityscapes_test')
if os.path.exists(train_images_path)==False:
os.mkdir(train_images_path )
if os.path.exists(val_images_path)==False:
os.mkdir(val_images_path)
if os.path.exists(test_images_path)==False:
os.mkdir(test_images_path)
#-----------------移动文件夹-------------------------------------------------
for file_name in os.listdir(train_dataset_path):
file_path = os.path.join(train_dataset_path,file_name)
for image in os.listdir(file_path):
shutil.copy(os.path.join(file_path,image), os.path.join(train_images_path,image))
for file_name in os.listdir(val_dataset_path):
file_path = os.path.join(val_dataset_path,file_name)
for image in os.listdir(file_path):
shutil.copy(os.path.join(file_path,image), os.path.join(val_images_path,image))
for file_name in os.listdir(test_dataset_path):
file_path = os.path.join(test_dataset_path,file_name)
for image in os.listdir(file_path):
shutil.copy(os.path.join(file_path,image), os.path.join(test_images_path,image))
运行后生成如下文件夹。

对于label文件也同样如此,比如下面生成19类的标注文件夹。
import os
import random
import shutil
# 数据集路径
dataset_path = r"dataset\cityscapes\gtFine_trainvaltest\gtFine"
#原始的train, valid文件夹路径
train_dataset_path = os.path.join(dataset_path,'train')
val_dataset_path = os.path.join(dataset_path,'val')
test_dataset_path = os.path.join(dataset_path,'test')
#创建train,valid的文件夹
train_images_path = os.path.join(dataset_path,'cityscapes_19classes_train')
val_images_path = os.path.join(dataset_path,'cityscapes_19classes_val')
test_images_path = os.path.join(dataset_path,'cityscapes_19classes_test')
if os.path.exists(train_images_path)==False:
os.mkdir(train_images_path )
if os.path.exists(val_images_path)==False:
os.mkdir(val_images_path)
if os.path.exists(test_images_path)==False:
os.mkdir(test_images_path)
#-----------------移动文件---对于19类语义分割, 主需要原始图像中的labelIds结尾图片-----------------------
for file_name in os.listdir(train_dataset_path):
file_path = os.path.join(train_dataset_path,file_name)
for image in os.listdir(file_path):
#查找对应的后缀名,然后保存到文件中
if image.split('.png')[0][-13:] == "labelTrainIds":
#print(image)
shutil.copy(os.path.join(file_path,image), os.path.join(train_images_path,image))
for file_name in os.listdir(val_dataset_path):
file_path = os.path.join(val_dataset_path,file_name)
for image in os.listdir(file_path):
if image.split('.png')[0][-13:] == "labelTrainIds":
shutil.copy(os.path.join(file_path,image), os.path.join(val_images_path,image))
for file_name in os.listdir(test_dataset_path):
file_path = os.path.join(test_dataset_path,file_name)
for image in os.listdir(file_path):
if image.split('.png')[0][-13:] == "labelTrainIds":
shutil.copy(os.path.join(file_path,image), os.path.join(test_images_path,image))
得到如下结果。

到这里,我们已经提取了所有的图像文件和标注文件。
读取数据集
现在我们可以读取对应的数据集。
# 导入库
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch import optim
from torch.utils.data import Dataset, DataLoader, random_split
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
import os.path as osp
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
torch.manual_seed(17)
# 自定义数据集CamVidDataset
class CityScapesDataset(torch.utils.data.Dataset):
"""CamVid Dataset. Read images, apply augmentation and preprocessing transformations.
Args:
images_dir (str): path to images folder
masks_dir (str): path to segmentation masks folder
class_values (list): values of classes to extract from segmentation mask
augmentation (albumentations.Compose): data transfromation pipeline
(e.g. flip, scale, etc.)
preprocessing (albumentations.Compose): data preprocessing
(e.g. noralization, shape manipulation, etc.)
"""
def __init__(self, images_dir, masks_dir):
self.transform = A.Compose([
A.Resize(224, 448),
A.HorizontalFlip(),
#A.RandomBrightnessContrast(),
A.RandomSnow(),
A.Normalize(),
ToTensorV2(),
])
self.ids = os.listdir(images_dir)
self.ids2 = os.listdir(masks_dir)
self.images_fps = [os.path.join(images_dir, image_id) for image_id in self.ids]
self.masks_fps = [os.path.join(masks_dir, image_id) for image_id in self.ids2]
def __getitem__(self, i):
# read data
image = np.array(Image.open(self.images_fps[i]).convert('RGB'))
mask = np.array( Image.open(self.masks_fps[i]).convert('RGB'))
image = self.transform(image=image,mask=mask)
return image['image'], image['mask'][:,:,0]
def __len__(self):
return len(self.ids)
# 设置数据集路径
x_train_dir = r"dataset\cityscapes\leftImg8bit_trainvaltest\leftImg8bit\cityscapes_train"
y_train_dir = r"dataset\cityscapes\gtFine_trainvaltest\gtFine\cityscapes_19classes_train"
x_valid_dir = r"dataset\cityscapes\leftImg8bit_trainvaltest\leftImg8bit\cityscapes_val"
y_valid_dir = r"dataset\cityscapes\gtFine_trainvaltest\gtFine\cityscapes_19classes_val"
train_dataset = CityScapesDataset(
x_train_dir,
y_train_dir,
)
val_dataset = CityScapesDataset(
x_valid_dir,
y_valid_dir,
)
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=8, shuffle=True)
测试一下结果
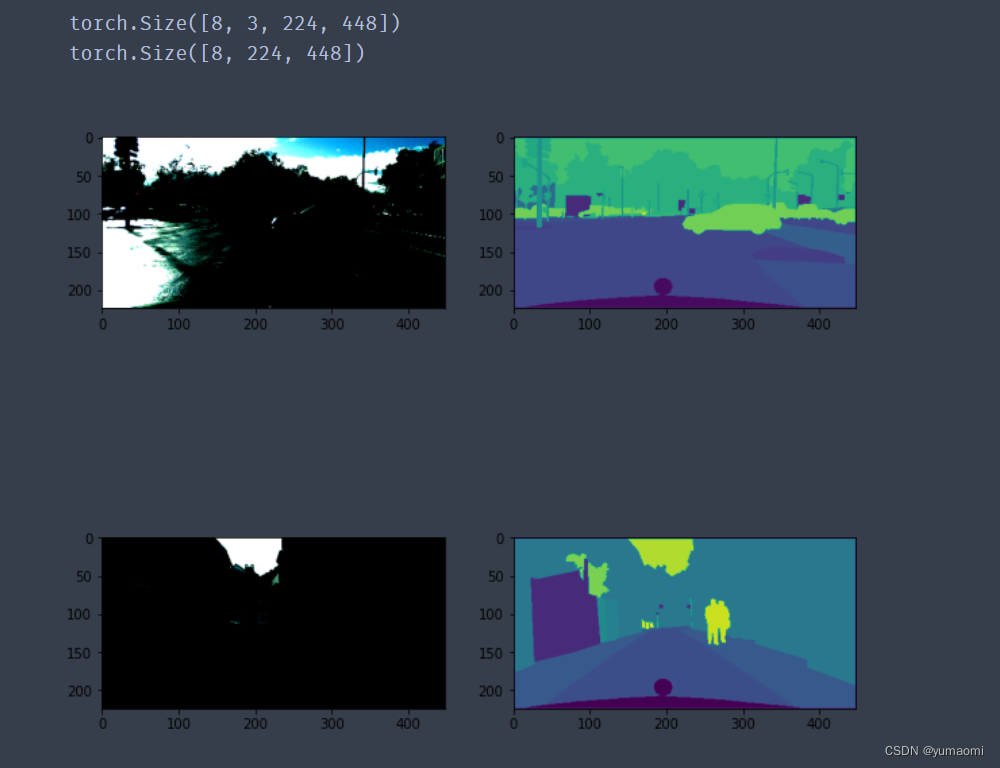
for index, (img, label) in enumerate(train_loader):
print(img.shape)
print(label.shape)
plt.figure(figsize=(10,10))
plt.subplot(221)
plt.imshow((img[0,:,:,:].moveaxis(0,2)))
plt.subplot(222)
plt.imshow(label[0,:,:])
plt.subplot(223)
plt.imshow((img[6,:,:,:].moveaxis(0,2)))
plt.subplot(224)
plt.imshow(label[6,:,:])
plt.show()
if index==0:
break
版权归原作者 yumaomi 所有, 如有侵权,请联系我们删除。