【AI底层逻辑】——篇章6:人工神经网络(深度学习算法)
任何一项技术的发展都不会一帆风顺,深度学习的发展也经历了“三起两落”!①第一代神经网络——单层感知器(MP)模型,感知器模型实际就是将神经元模型中的激活函数作为符号函数,写成向量形式,即它简洁且功能强大,可以实现自我迭代,只要有足够数量的样本,感知器模型就能找到一组合适的权重。但存在一个致命缺陷——
OSTrack 代码阅读记录
实验记录
Ubuntu20.04下CUDA11.8、cuDNN8.6.0、TensorRT8.5.3.1的配置过程
Ubuntu20.04下CUDA11.8、cuDNN8.6.0、TensorRT8.5.3.1的详细配置过程。
一分钟理解VAE(变分自编码器)
一分钟理解VAE(变分自编码器)
AttributeError: module ‘torch‘ has no attribute ‘concat‘
在跑算法代码的时候,发现报错,但是这个错误在网上没有找到,我推测是pytorch改版问题,于是查看torch版本改动,发现torch.concat改版后该写为torch.cat。不过或许我写的也不够准确,除此之外还看到了有人问torch.concat和torch.cat的区别。不过出现了这类问题改成
【未完待续】综述:用于视频分割(Video Segmentation)的深度学习
本文回顾视频分割的两条基本研究路线:视频目标分割(object segmentation)和视频语义分割(semantic segmentation)。本文介绍它们各自的task setting、背景概念、感知需求、发展历史以及主要挑战。本文详细概述相关的方法和数据集的代表性文献。本文在一些知名的数
GPT2中文模型本地搭建(二)
GPT2_ML项目是开源了一个中文版的GPT2,而且还是最大的15亿参数级别的模型。OpenAI在GPT2的时期并没有帮忙训练中文,上篇文章的验证也可说明此问题,对应的模型直接上GitHub上下载即可。本文主旨快速搭建本地模型,更全的攻略,大家也可以到GitHub中慢慢摸索。本文是基于bert4ke
验证集精度来回震荡是什么原因,怎么解决
验证集精度来回震荡是什么原因,怎么解决
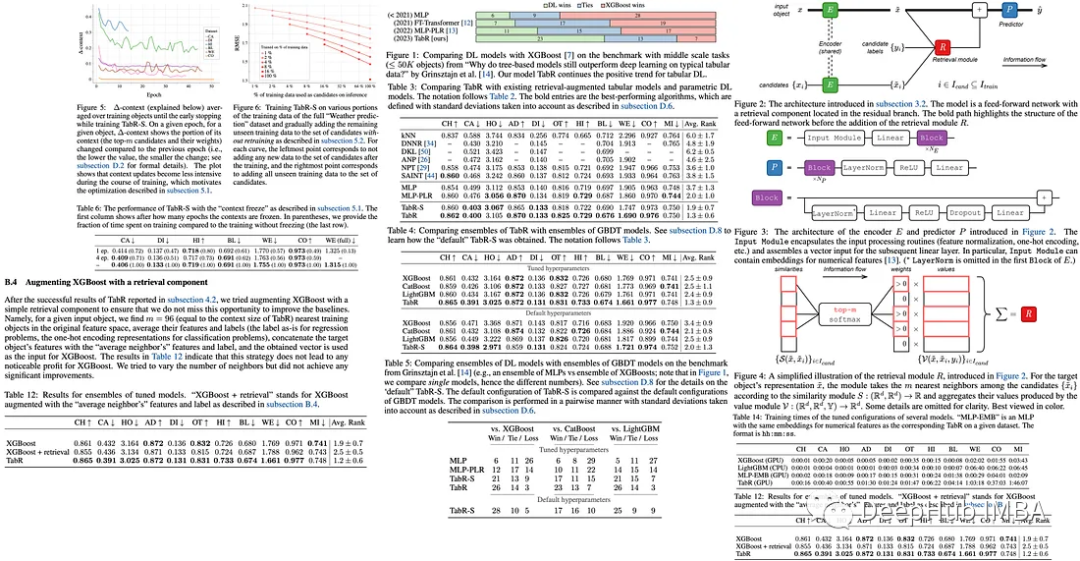
TabR:检索增强能否让深度学习在表格数据上超过梯度增强模型?
这是一篇7月新发布的论文,他提出了使用自然语言处理的检索增强*Retrieval Augmented*技术,目的是让深度学习在表格数据上超过梯度增强模型。
扁鹊:指令与多轮问询对话联合微调的医疗对话大模型
扁鹊-1.0(BianQue-1.0) 是一个经过指令与多轮问询对话联合微调的医疗对话大模型。我们经过调研发现,在医疗领域,往往医生需要通过多轮问询才能进行决策,这并不是单纯的“指令-回复”模式。用户在咨询医生时,往往不会在最初就把完整的情况告知医生,因此医生需要不断进行询问,最后才能进行诊断并给出
一张图了解GPU、CUDA、CUDA toolkit和pytorch的关系
现在的理解就是我可以装多个版本的cuda toolkit,,然后不同的框架会自动调用。
什么是人工智能领域的 Foundation Model?
GPT 模型采用了预训练加微调的方式,通过大规模的语料库训练出来的模型,可以在多种 NLP 任务中表现出色,如文本分类、机器翻译、摘要生成等。人工智能领域的 Foundation Model,通常指的是一类被广泛使用的基础模型(或称基础架构模型),是在海量数据和计算资源的基础上训练出来的通用、通用性
docker中使用gpu
本机想要启用gpu加速计算,需要由一张多余的nVidia显卡。需要提前禁用nouveau:lsmod | grep nouveau没有输出即禁用了需要安装1、显卡驱动、2、cuda库(安装cuda会自动安装显卡驱动)3、cudnn(深度神经网络的GPU加速库,需要神经网络则安否则可以不安)安装完成后
神经辐射场(NERF)模型:一个令人惊叹的三维场景重建方法
简单来说,NERF 模型是一种基于神经网络的三维场景重建方法。与传统方法不同,NERF 模型 只需要从单个或少数几个 2D 视角中预测每个像素点的颜色和深度值,而不需要使用多个 2D 图像或视角。它通过学习一个表示场景中每个点的神经辐射场函数来实现这一点。
10分钟训练属于你的AI变声器
模型的话,可以使用其他人分享的,也可以自己训练模型。下面介绍怎么训练模型。
对卡尔曼滤波的理解:平滑插值、滤波和预测!想用的来看啦!
对卡尔曼滤波的理解:平滑插值、滤波和预测!想用的来看啦!
Stable Diffusion模型运算量分析
StableDiffusion运算量分析
YOLOV5的FPS计算问题
pre-process:图像预处理时间,包括图像保持长宽比缩放和padding填充,通道变换(HWC->CHW)和升维处理等;inference:推理速度,指预处理之后的图像输入模型到模型输出结果的时间;NMS :你可以理解为后处理时间,对模型输出结果经行转换等;data换为自己的数据集对应的yam
基于onnx模型和onnx runtime推理stable diffusion
基于onnx模型和onnx runtime推理stable diffusion
torch 1.13.0 对应的torchvision版本
奈何官网也没有说对应的torchvision版本是啥,如果想要。由于torch版本肯定是会快速迭代更新的,比起记住特定版本,倒不如记住这个思路。torch最新的stable版本是。



