
CityScapes
Cityperson数据集,在16年CVPR上被提出,是张姗姗一波人在CityScapes数据集上进行标注得到的行人检测数据集。做行人检测的应该都不陌生。在Replusion Loss和NMS Loss这两篇关于行人遮挡问题的论文中都以这个数据集中的子集-CityPerson作为数据集。
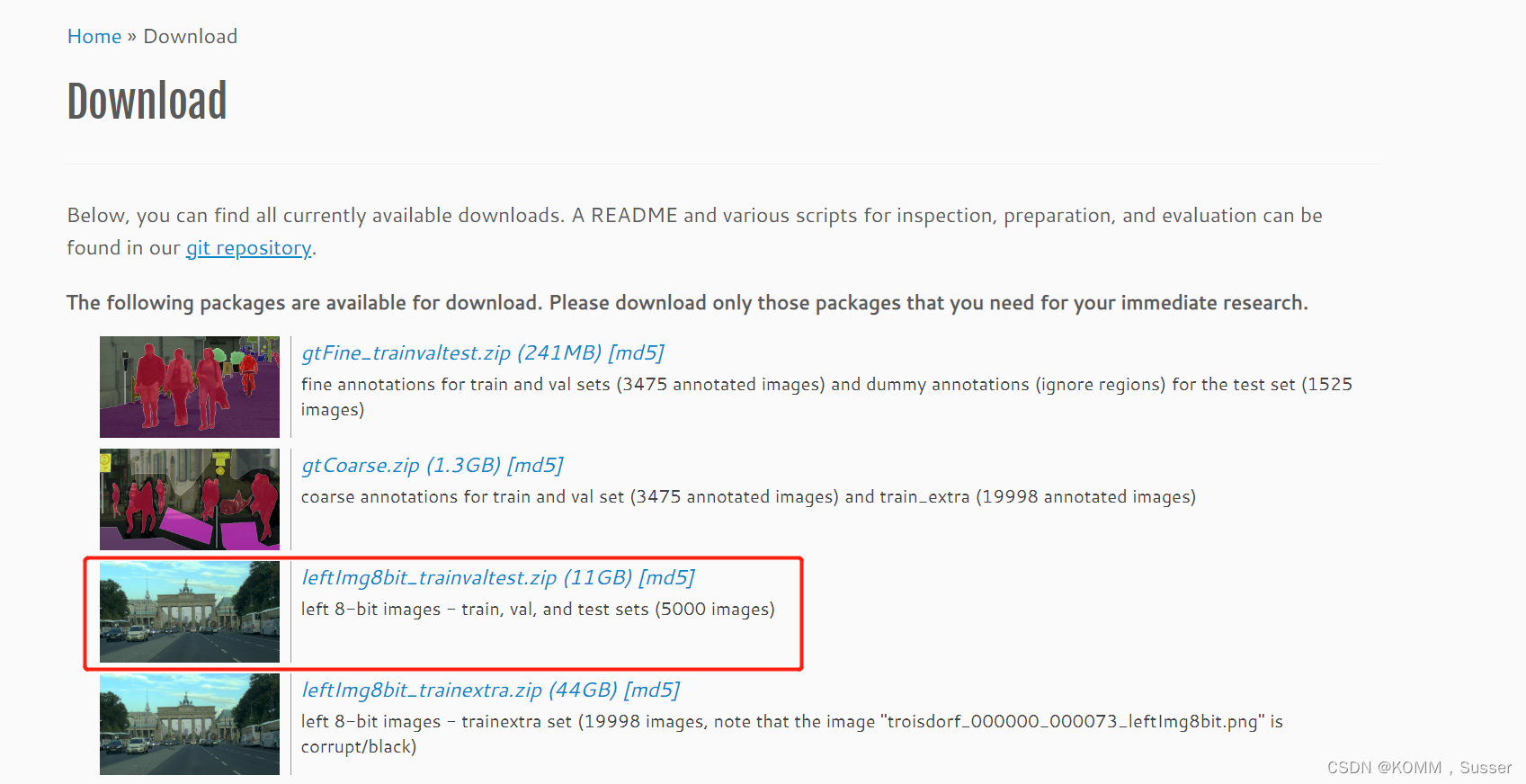
数据集下载路径:Cityscapes Dataset – Semantic Understanding of Urban Street Scenes
特性:多边形的注释;密集语义分割;车辆和人的实例分割
复杂性:30类
多样性:50个城市;几个月(春、夏、秋);白天、良好/中等天气状况;手动选择的帧;
大量的动态对象;多变的场景布局;不同的背景
体积:5 000个带注释的图片(示例)
下面是我们为5 000张图像提供的高质量密集像素注释示例。覆盖的颜色编码语义类(参见类定义)。注意,交通参与者的单个实例是单独注释的。

粗糙的注释
除了精细的注释,我们还与Pallas Ludens合作,为一组20 000图像提供了更粗略的多边形注释。同样,重叠的颜色编码语义类(参见类定义)。请注意,我们的目标不是注释单个实例,而是标记覆盖单个对象的多边形。

标签策略
有标记的前景对象绝对不能有洞,也就是说,如果有一些背景可见的“通过”一些前景对象,它被认为是前景的一部分。这也适用于高度混合了两个或多个类的区域:它们被标记为前景类。例如:房子或天空前面的树叶(一切都是树),透明的车窗(一切都是汽车)。
类定义
GroupClassesflatroad · sidewalk · parking+ · rail track+humanperson* · ridervehiclecar · truck* · bus* · on rails* · motorcycle* · bicycle* · caravan*+ · trailer*+constructionbuilding · wall · fence · guard rail+ · bridge+ · tunnel+objectpole · pole group+ · traffic sign · traffic lightnaturevegetation · terrainskyskyvoidground+ · dynamic+ · static+
*单个实例注释可用。然而,如果这些实例之间的边界不能清楚地看到,整个人群/组被标记在一起并注释为组,例如汽车组。
+此标签不包括在任何评估中,并被视为无效(或在车牌为车辆安装的情况下)。
CityPersons
Cityscape侧重于城市街道场景的语义理解。由于我个人的方向是行人检测,这里主要介绍下里面的行人数据集。CityPersons数据集是cityscape的一个子集,它只包含个人注释。有2975张图片用于培训,500张和1575张图片用于验证和测试。一幅图像中行人的平均数量为7人,提供了可视区域和全身标注。如下表,CityPersons标注文件只标注了其中HUMAN的类别。
humanperson* · rider*
数据集下载:博主Rock_Huang~提供百度云链接地址:链接: 百度网盘 提取码:xyzj
CityPersons训练图像:
CityPersons的图像标注:
提取cityscapes中标注好的类别为VOC的标准格式(JPEGImages和Annotations)
#! /usr/bin/python
# -*- coding:UTF-8 -*-
import os, sys
import glob
from PIL import Image
import shutil
from scipy.io import loadmat
#img_Lists = glob.glob(src_img_dir + '\*.png')
# citypersons图像的标注位置
src_anno_dir = loadmat(r'c:\Users\rockhuang\Desktop\anno_train.mat')
# cityscapes图像的存储位置
src_img_dir = r"g:\dataset\cityscapes\leftImg8bit\train\\"
#保存为VOC 数据集的原图和xml标注路径
new_img= r"g:\dataset\cityscapes\JPEGImages"
new_xml=r"g:\dataset\cityscapes\Annotations"
if not os.path.isdir(new_img):
os.makedirs(new_img)
if not os.path.isdir(new_xml):
os.makedirs(new_xml)
a=src_anno_dir['anno_train_aligned'][0]
#处理标注文件
for i in range(len(a)):
img_name=a[i][0][0][1][0] #frankfurt_000000_000294_leftImg8bit.png
dir_name=img_name.split('_')[0]
img=src_img_dir+dir_name+"\\"+img_name
shutil.copy(img, new_img+"\\"+img_name)
img=Image.open(img)
width, height = img.size
position=a[i][0][0][2]
print(position)
#sys.exit()
xml_name=img_name.split('.')[0]
xml_file = open((new_xml + '\\' + xml_name + '.xml'), 'w')
xml_file.write('<annotation>\n')
xml_file.write(' <folder>citysperson</folder>\n')
xml_file.write(' <filename>' + str(img_name)+ '</filename>\n')
xml_file.write(' <size>\n')
xml_file.write(' <width>' + str(width) + '</width>\n')
xml_file.write(' <height>' + str(height) + '</height>\n')
xml_file.write(' <depth>3</depth>\n')
xml_file.write(' </size>\n')
for j in range(len(position)):
category_location=position[j] #[ 1 947 406 17 40 24000 950 407 14 39]
category=category_location[0] # class_label =0: ignore regions 1: pedestrians 2: riders 3: sitting persons 4: other persons 5: group of people
if category == 0:
continue
# if
#if category == 1 or category ==2 or category ==3 category ==4 or category ==5:
else:
x=category_location[1] #class_label==1 or 2: x1,y1,w,h是与全身对齐的边界框;
y=category_location[2]
w=category_location[3]
h=category_location[4]
xml_file.write(' <object>\n')
xml_file.write(' <name>' + 'person' + '</name>\n')
xml_file.write(' <pose>Unspecified</pose>\n')
xml_file.write(' <truncated>0</truncated>\n')
xml_file.write(' <difficult>0</difficult>\n')
xml_file.write(' <bndbox>\n')
xml_file.write(' <xmin>' + str(x) + '</xmin>\n')
xml_file.write(' <ymin>' + str(y) + '</ymin>\n')
xml_file.write(' <xmax>' + str(x+w) + '</xmax>\n')
xml_file.write(' <ymax>' + str(y+h) + '</ymax>\n')
xml_file.write(' </bndbox>\n')
xml_file.write(' </object>\n')
xml_file.write('</annotation>\n')
转化为YOLOv5训练的txt标注。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[ ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["car", "person","rider"]
#parser = ET.XMLParser("utf-8")
#tree = ET.fromstring(xmlstring, parser=parser)
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
#parser = ET.XMLParser(encoding="utf-8")
# tree = ET.fromstring(in_file, parser=True)
print in_file
tree=ET.parse(in_file)
# print in_file
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
#os.system("cat 2007_train.txt 2007_val.txt > train.txt")
#os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_train.txt 2012_val.txt > train.all.txt")
版权归原作者 KOMM,Susser 所有, 如有侵权,请联系我们删除。