
🌕写在前面
- 🍊博客主页:kikoking的江湖背景
- 🎉欢迎关注🔎点赞👍收藏⭐️留言📝
- 🌟本文由 kikokingzz 原创,CSDN首发!
- 📆首发时间:🌹2022年4月12日🌹
- 🆕最新更新时间:🎄2022年4月12日🎄
- ✉️坚持和努力一定能换来诗与远方!
- 🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢感谢感谢!
🎉🎉订阅本专栏,将为你带来【机器学习】优质文章!🎉🎉
PS:微信公主号回复“西瓜计划”就可获得本期电子文档!


🍓1.什么是机器学习?
机器学习致力于研究如何通过计算的手段,利用经验来改善系统自身的性能.在计算机系统中,“经验”通常以“数据”形式存在,因此,机器学习所研究的主要内容,是关于在计算机上从数据中产生“模型”(model)的算法,即“学习算法”(learning algorithm)。
有了学习算法,我们把经验数据提供给它,它就能基于这些数据产生模型;在面对新的情况时(例如看到一个没剖开的西瓜),模型会给我们提供相应的判断(例如好瓜).如果说计算机科学是研究关于“算法”的学问,机器学习是研究关于“学习算法”的学问。
关于机器学习的另一种解释有:计算机会从经验E中学习,解决某一任务T,进行某一性能度量P,通过P测定在T上的表现,进而经验E提高,我们这边以一个买瓜的例子来解释。

🍓2.一些基本术语

数据集(data set):我们将这组记录西瓜数据的集合称为一个“数据集”。
示例(instance)/样本(sample):其中的每条记录是关于一个事件或对象(西瓜)的描述。
属性(attribute)/特征(feature):反映事件或对象在某方面的表现或性质的事项。
属性值(attribute value):属性上的取值,例如上述示例II对于“敲声”这个属性的取值为“沉闷”。
属性空间(attribute space)/样本空间(sample space)/输入空间:属性张成的空间。
例如我们把“色泽”、“根蒂”、“敲声”作为三个坐标轴,则它们张成一个用于描述西瓜的三维空间,每个西瓜都以在这个空间中找到自己的坐标位置。由于空间中的每个点对应一个坐标向量,因此我们也把一个示例称为一个“特征向量”(feature vector)。
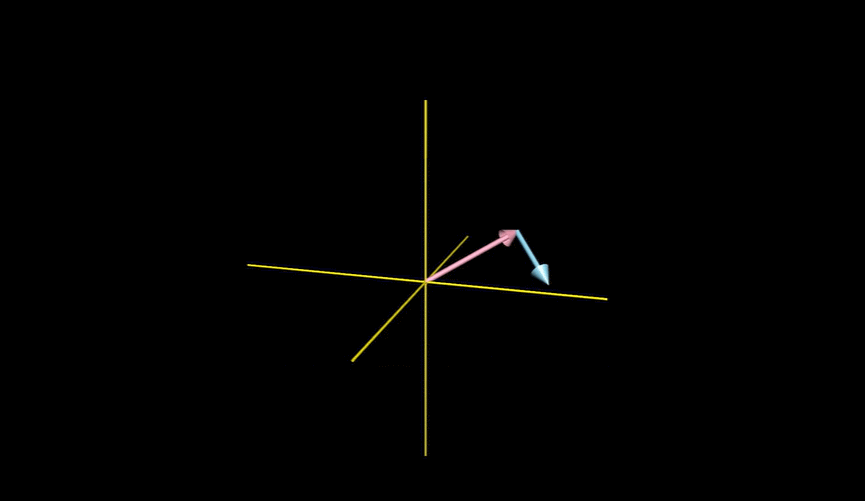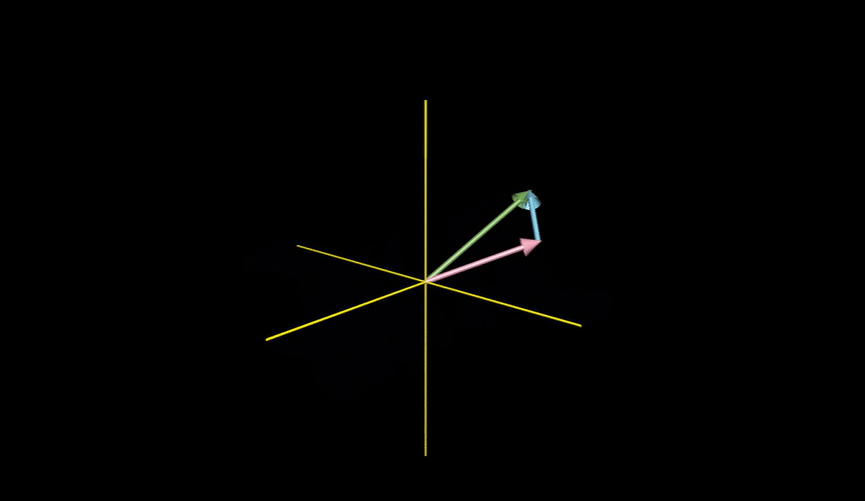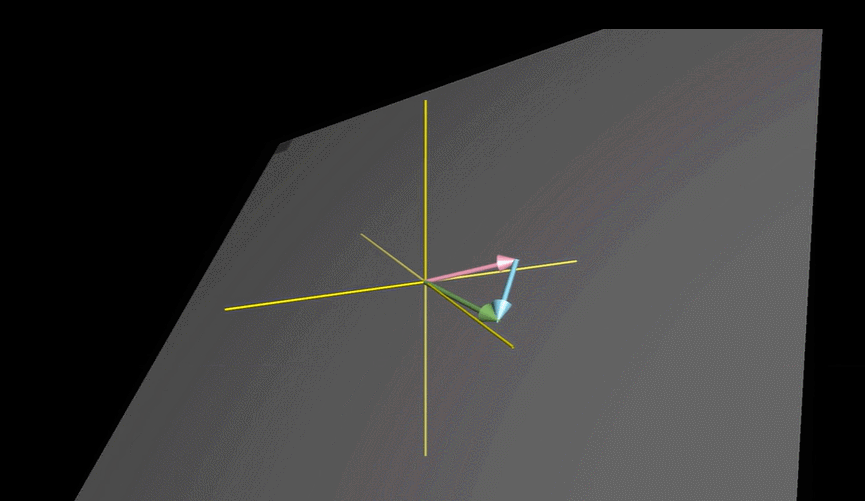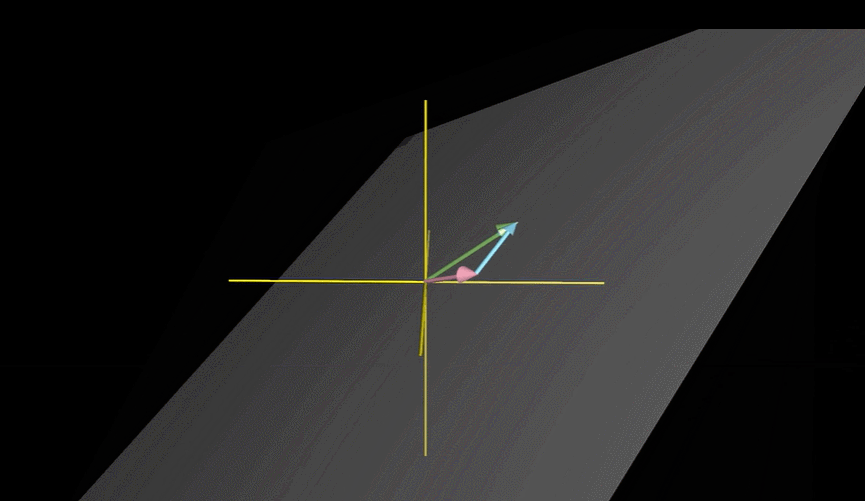
两个三维向量张成的空间
一般来说我们令表示m个示例的数据集,每个示例由d个属性描述,则每个示例
是d维向量样本空间X中的一个向量,其中
是
在第j个属性上的取值,d称为样本
的“维数”。

学习(learning)/训练(training):从数据中学得模型的过程,这个过程通过执行某个学习算法来完成。
训练数据(training data):训练过程中使用的数据。
训练样本(training sample):训练数据中的每个样本称为一个“训练样本”。
训练集(training set):训练样本组成的集合。
假设(hypothesis):学得模型对应了关于数据的某种潜在的规律。
真相/真实(ground-truth):这种潜在规律自身,学习过程就是为了找出或逼出真相。
学习器(learner):书中有时将模型称为“学习器”,可看作学习算法在给定数据和参数空间上的实例化。

希望机器学得一个“判断好瓜”的模型,仅仅有示例数据是不够的,我们要建立能够“预测”的模型,因此我们需要获得训练样本的“结果”,例如:
((色泽=青绿;根蒂=硬挺;敲声=清脆) ,好瓜)
标记(label):这里关于示例结果的信息,例如“好瓜”,称为标记。
样例(example):拥有了“标记”的示例,称为样例。一般地,用表示第i个样例,其中
是
的标记,
,Y是所有标记的集合,也称为“标记空间”or“输出空间”。

分类(classification):当我们预测的是离散值,此类学习任务称为“分类”;例如判断瓜是“好瓜”or“坏瓜”。
回归(regression):当我们预测的是连续值,此类学习任务称为“回归”;例如西瓜的成熟度为0.95、0.37。
二分类(binary classification):对只涉及两个类别的“二分类”任务,通常称其中一个类为“正类”(positive class),另一个为反类(negative class)。
多分类(multi-class classification):对涉及多个类别的任务,称为“多分类”任务。
测试(testing):学得模型后,使用该模型进行预测的过程称为“测试”。
检测样本(testing sample):被检测的样本称为“检测样本”。
例如在学得f后,对测试案例x,可以得到预测标记 。
聚类(clustering):将训练集中的西瓜分成若干组,每一组称为一个“簇”(cluster);这些自动形成的簇可能对应一些潜在的概念划分,例如“浅色瓜”、“深色瓜”。在聚类学习中,“浅色瓜”这样的概念我们事先是不知道的,而且学习过程中使用的训练样本通常不拥有标记信息。
🍓3.监督学习
监督学习:监督学习是从标记的训练数据来推断一个功能的机器学习任务。训练数据包括一套训练示例。在监督学习中,每个实例都是由一个输入对象(通常为矢量)和一个期望的输出值(也称为监督信号)组成。监督学习算法是分析该训练数据,并产生一个推断的功能,其可以用于映射出新的实例。
[中英字幕]吴恩达机器学习系列
🥝回归问题

上例中我们使用了两个属性,横轴为房子的面积属性,纵轴为房子的价格属性。我们给了计算机一个房价数据集,在这个数据集中的每个样本我们都给出正确的价格(上图中的这些×)。算法的目的是通过已有的数据来给出更多的正确答案,例如本例,学习算法需要为这栋房子(1000平)给出一个正确的估价,它可以采用直线拟合或二次函数拟合的方式,来进行估价。采用直线拟合的估价为190w,采用二次函数拟合的估价为290w。
从专业角度来看,这也可以看做是一个回归问题,回归问题多用来预测一个具体的数值,如预测房价、未来的天气情况等等。
🥝分类问题

上例中我们使用了两个属性,横轴为肿瘤大小,纵轴表示肿瘤的状态,值为1表示为恶性肿瘤,值为0表示为良性。我们给了计算机一个肿瘤大小与恶性肿瘤关系的对应数据集(即上图中的×),这时我们假设有个病人,他的肿瘤大小为绿色箭头所指的大小,此时学习算法要做的事情就是,计算出肿瘤是良性还是恶性的概率。
从专业角度来看,这是一个分类问题。分类是指,我们设法预测一个离散值输出,本例为良性or恶性。对于分类问题,可能也会有多个离散值的输出。

在分类问题中,我们可以用另一种方法来绘制这些数据。我们以肿瘤的大小(Tumor Size)作为衡量其恶性或良性的标准,用O代表良性,用×代表恶性,此时,我们只使用了一个属性——肿瘤的大小,来预测肿瘤是良性还是恶性的。
对此我们再举一个例子(如下图),假设我们此时不仅知道肿瘤的大小及状况,还知道病人的年龄。在这种情况下,我们依然用O代表良性,用×代表恶性。这时有一个病人,我们知道他的肿瘤大小与年龄,在给定的数据集上,学习算法能做的就是在数据上画一条线来分隔开恶性肿瘤与良性肿瘤。

假设该病人的位置位于上图绿色点,这时学习算法可能就会认为,该病人的肿瘤位于良性区域,因此良性的可能性会更大一些。
在此例中,我们使用了两种属性,即病人的年龄和肿瘤大小。在其他机器学习算法中,可能会有更多的特征,也就是说学习算法会用很多属性或特征来做预测。
🍓4.无监督学习
无监督学习:现实生活中常常会有这样的问题:缺乏足够的先验知识,因此难以人工标注类别或进行人工类别标注的成本太高。很自然地,我们希望计算机能代我们完成这些工作,或至少提供一些帮助。根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习。
[中英字幕]吴恩达机器学习系列课程
🥝聚类问题
与监督学习不同的是,我们得到一个数据集(如下图),这些数据可能有相同的标签或都没有标签(下边的数据点都是蓝色⭕️),我们不知道要拿它来做什么,也不知道每个数据点究竟是什么,我们只知道这里有一个数据集,让计算机找出其中的结构。

无监督学习算法可能判定该数据集包含两个不同的族(左下角一团+右上角一团),这就是聚类算法。
聚类:
聚类(Clustering)是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。也即聚类后同一类的数据尽可能聚集到一起,不同类数据尽量分离。
聚类算法在很多领域中都有应用:
 (1)组织大型计算机集群:在一些大型数据中心,试图找出哪些机器趋向于协同工作,如果你把这些机器放在一起,你就可以让你的数据中心更高效地工作。
(1)组织大型计算机集群:在一些大型数据中心,试图找出哪些机器趋向于协同工作,如果你把这些机器放在一起,你就可以让你的数据中心更高效地工作。
(2)社交网络分析:如果聚类算法知道你抖音视频里@最多的联系人,或者知道你微信里联系最多的好友,它就可以自动识别同属一个圈子的朋友,判断哪些人相互认识。
(3)市场细分:许多公司都有庞大的客户信息数据库,对于一个客户数据集,你能否自动找出不同的市场分割,并自动将你的客户分到不同的细分市场,从而高效地在不同细分市场中进行销售。
(4)天文数据分析:对于宇宙中的星系进行分类。
🥝鸡尾酒聚会算法
鸡尾酒聚会算法,就是可以将鸡尾酒会中的嘈杂声音,也就是将语音源1和语音源2的混合音频,通过鸡尾酒会算法分离出来,即重新分离为音源1和音源2。

在斯坦福大学的安德鲁·伍(Andrew Ng)在Coursera的机器学习入门讲座的幻灯片中,他给出了鸡尾酒会问题的解决方案:
[W,s,v]=svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x');
更多内容可见:鸡尾酒聚会算法_weixin_33749131的博客-CSDN博客
🍓5.假设空间
(1)科学的推理手段
演绎:是从一般到特殊的“特殊化”(specialization)过程;即从基础原理推演出具体情况。例如,数学公理系统中,基于一组公理和推理规则推导出与之相洽的定理,这一过程就是演绎。
归纳:是从特殊到一般的“泛化”(generalization)过程;即从具体的事实归结出一般性规律。例如从样例中学习,这就是一个归纳的过程,因此也称为“归纳学习”。
(1)广义的归纳学习:广义的归纳学习大体相当于从样例中学习。
(2)狭义的归纳学习:要求从训练数据中学得概念(concept),因此亦称为“概念学习”或“概念形成”。
PS:概念学习技术目前研究、应用都比较少,因为要学得泛化性能好且语义明确的概念是在太困难了,现实常用的技术大多是产生“黑箱”模型。
黑箱模型(Black box)或称经验模型,指一些其内部规律还很少为人们所知的现象。
(2)什么是假设空间?
关于假设空间的内容,我们举下面这个例子来进行理解。
编号色泽根蒂敲声好瓜1青绿蜷缩浊响是2乌黑蜷缩清脆是3青绿硬挺清脆否4乌黑稍蜷沉闷否
假设我们获得了上面这个训练数据集,我们学习的目标是“好瓜”;通过上表我们将“好瓜”的评判标准为“色泽”、“根蒂”、“敲声”这三个属性决定,因此我们用布尔表达式来写出“好瓜”与这三个属性之间的逻辑关系:
好瓜——(色泽= ?)^(根蒂= ?)^(敲声= ?)
这里的“?”表示尚未确定的值,我们的任务就是通过对上表训练集进行学习,把“?”确定下来
我们可以把学习过程看作一个在所有假设(hypothesis)组成的空间中进行搜索的过程,搜索目标是找到与训练集“匹配”的假设,即能够将“训练集”中的瓜判断正确的假设。
本题的假设空间由**(色泽= ?)^(根蒂= ?)^(敲声= ?) **的所有可能取值组成。
例如色泽有“青绿”、“乌黑”、“浅白”这三种可能取值;还需要考虑到“色泽”无论取什么值都合适,这种情况我们用通配符“*”表示。
**(色泽= *)^(根蒂= 蜷缩)^(敲声= 浊响) **== 蜷缩浊响的瓜一定是好瓜,色泽什么都行
关于本题,通过上述训练集我们可以将这三种属性的可能值分别写出:
- 色泽 = [青绿,乌黑,* ](3种)
- 根蒂 = [蜷缩,硬挺,稍蜷,* ](4种)
- 敲声 = [浊响,清脆,沉闷,* ](4种)
- 极端情况:可能好瓜这个概念根本不成立,即
,单独是一种情况
因此通过计算可得,对应的假设空间的规模大小为3 x 4 x 4 + 1 = 49
(3)什么是版本空间?
可能有多个假设与训练集一致,即存在着一个与训练集一致的“假设集合”,我们称之为“版本空间”(version space)。

🍓6.归纳偏好
(1)为什么要有“偏好”?
通过学习得到的模型会对应假设空间中的一个假设,假如在假设中有如下两种假设,其判断结果为好瓜:
*假设1:好瓜——(色泽= )^(根蒂= 蜷缩)^(敲声= 浊响)
**假设2:好瓜——(色泽= )^(根蒂= )^(敲声= 清脆)
此时,对于这个新瓜(色泽:青绿;根蒂:蜷缩;敲声:沉闷),如果采用假设1,那么可以判断为好瓜,但如果采用假设2,则判断为不是好瓜,那么实际中应采用哪一个模型(或假设)呢?关于这类问题,我们就可以引出“偏好”这个概念。
偏好:机器学习算法在学习过程中对某种类型假设的偏好,称为“归纳偏好”或“偏好”。
编号色泽根蒂敲声好瓜1青绿蜷缩浊响是2乌黑蜷缩清脆是3青绿硬挺清脆否4乌黑稍蜷沉闷否
此时仅仅依靠上表中的训练样本,是无法判定哪一种假设更好,但对于学习算法而言,“偏好”就会起到关键作用。
(1)若算法偏好“尽可能特殊”的模型,即适用情况尽可能少的模型:
例如:*好瓜——(色泽= )^(根蒂= 蜷缩)^(敲声= 浊响)
(2)若算法喜欢“尽可能一般”的模型,即适用情形尽可能多的模型:
例如:**好瓜——(色泽= )^(根蒂= 蜷缩)^(敲声= )
如果没有偏好,学习算法产生的模型在每次进行预测时,随机抽选训练集上的等效假设,那么对于新瓜(色泽:青绿;根蒂:蜷缩;敲声:沉闷),学习模型时而告诉我们它是好的,时而告诉我们它是不好的,这样的学习没有意义。
(2)如何选择“偏好”?
归纳偏好的作用在下图中表示更加直观。这里的每个训练样本是图中的一个点(x,y),要学得一个与训练集一致的模型,相当于找到一条穿过所有训练样本点的曲线。
显然,对于有限个样本点组成的训练集,存在着很多条曲线与其一致。我们的学习算法必须有某种偏好,才能产出它认为“正确”的模型。

例如,若认为相似的样本应有相似的输出(例如,在属性上相似的西瓜,成熟程度也比较相近),就可以对应比较平滑的曲线A,而不是崎岖的曲线B。
奥卡姆剃刀:“如无必要,勿增实体” 。
一般来说,我们采用“奥卡姆剃刀”原则来选择“偏好”,即“若有多个假设与观察一致,则选择最简单的那个”。如果采用这个原则,并且我们认为“更平滑”意味着“更简单”,那么我们会自然地偏好“平滑”的曲线A。
(3)什么样的学习算法更好?
假设学习算法a基于“归纳偏好”产生了对应于曲线A的模型,学习算法b基于另一种“归纳偏好”产生了对应于曲线B的模型。基于奥卡姆剃刀原则,我们可能会觉得A模型比B模型更好,但事实真的如此吗?

我们发现对于一个学习算法a,若它在某些问题上比学习算法b好;则必然存在另一些问题,学习算法b比学习算法a好,对于这样的现象已经有定理证明了,那就是NFL定理。
NFL定理:NoFreeLunch Theorem“没有免费的午餐”定理;也就是说,无论学习算法a多聪明,学习算法b多笨拙,它们的期望性能相同。
NFL定理最重要的寓意:是让我们清楚地认识到,脱离具体问题,空泛地谈论“什么学习算法更好”毫无意义。因为若考虑所有潜在的问题,则所有学习算法都一样好。要谈论算法的相对优劣,必须要针对具体的学习问题,在某些问题上表现好的学习算法,在另一些问题上却可能不尽人意。
版权归原作者 kikokingzz 所有, 如有侵权,请联系我们删除。