
在上一篇博客中,我们简单介绍了如何基于 OpenCV.js 或 Rust/WebAssembly 设计并实现技术方案,在前端业务中实现计算机视觉类(下文简称 CV)的功能。感兴趣的同学可以点击下方链接回顾上一期博客:
墨奇科技博客 | 计算机视觉在前端应用中的实践Ⅰhttps://blog.csdn.net/Moqi_AI/article/details/123898816?spm=1001.2014.3001.5502
在本文中,我们将从算法、系统、业务三个方面,分享在进一步的性能优化上的一些经验。
一、优化对象
在我们的业务系统中,大量的 CV 计算函数均以实现“风格转换”为目标,亦即通过变换、增强原始的生物特征图像,方便系统使用者观察、标注、比对。
根据我们的内部数据统计,“图像风格转换”的使用频次较高,且短时间内使用密度大,用户期待快速的视觉反馈。因而以此类函数作为主要的优化目标能带来较高的收益。
锐化、颜色混合是 2 个高频使用的风格转换函数。锐化往往能增强图像纹理细节,加大特征与背景的区分度,对于在较差环境下拍摄、提取的模糊图像,较为实用。颜色混合函数则将单一底色,以线性混合的方式与原图混合,可用于突出生物特征的纹线。常用的为某一特定色度、明度、饱和度下的蓝色。
下文将主要以这 2 个函数为例,介绍性能优化的主要思路与方法。
二、优化思路
对于如 CV 函数般的计算密集型任务,有常见的 3 个性能优化方向。
1.算法
优化算法从而降低时间复杂度、减少高耗时的操作数往往是第一步。例如,对于最常见的卷积操作,我们可以使用 Winograd 算法计算小核(e. g. 3x3, stride 1)以减少乘法计算次数;使用离散傅里叶变换计算大核降低时间复杂度(e. g. kernel size > 11)。
以空间换时间也是常常遇到的思路。例如,对于双线性插值的 resize 操作,OpenCV 会将每一点插值所需的系数预先存储,避免重复的计算。
2.系统
系统层面的优化比较宽泛,并行化是重点之一。在指令级层面,SIMD (Single Instruction, Multiple DATA) 的合理使用可以带来成倍的性能提升。前端场景下,WebAssembly 同样支持 SIMD 指令,但对我们的业务而言,兼容性不够理想。对于多核处理器,多线程/多进程是更宏观层面上提高并行计算能力的方式之一。对于前端项目,web worker 为我们提供了实现类似方式的可能性。
3.业务
除了算法、系统方向的优化,在特定的业务场景下,我们还可以尝试简化算法流水线从而降低计算密度,因而,理解业务需求也非常重要。
例如,若我们将计算函数 f 应用于数组 A 中的 N 个元素,计算次数取决于我们对计算结果的使用。倘若我们需要排序并返回结果,那么就不得不计算每个值,并额外增加排序过程;若仅用作过滤,那么排序就可以省略;倘若只想获得 topK,那么我们甚至有可能提前截断遍历,以此减少计算的次数。当 N 很大,或单次计算很耗时的情况下,其中的差异是不可忽视的。
此类优化与纯算法优化的区别是,其往往有高度的场景依赖性,最终的输出函数可能因此丧失一定的通用性,需要谨慎考虑。
下文中,我们将主要以颜色混合、锐化函数为例,简述在这三个方向上,我们所做的一些尝试。
三、优化案例
1.颜色混合
我们业务系统中的,颜色混合函数的算法基础非常简单。假设原始图像在某点 (x, y) 的 RGB 像素值为 (r, g, b),用于混合的颜色的 RGB 像素值为 (R, G, B),那么最终该点的像素值为 ((1 - t)r + tR,(1 - t)g + tG, (1 - t)b + tB),其中 t 为一固定的 [0, 1] 间的系数。
颜色混合有一个比较重要的特点:单个像素的计算与周围像素是独立的。从计算密度看,单个通道包含 1 次乘法,2 次加/减操作,略高于反相(i. e. 1 - pixel_value)等最朴素的图像操作。
(1)算法
我们使用了查表法来避免重复的计算。对于 24 位 RGB 图像,尽管每个像素点、每个通道的像素值都不一定相同,但是值范围却始终落在 [0, 255],那么对于单变量输入的 (1 - t)k0 + tk1 (k0 为原图像素点 RGB 值,k1 为混合颜色的 RGB 值) 计算,输出值也仅有 256 种可能。
我们可以预先计算出 256 个值并以数组的形式缓存在内存中。之后,对于每一张图像的每一个像素值,仅需以该值为索引,返回数组中对应值即可。我们的 JavaScript / Rust 方案均实现了这一算法。在 Chrome 79 上,对于 2034x2034 大小的图像,处理耗时减少了约 5-6%。
(2)系统
我们最初的 Rust 实现,基于类库 Photon。在实际性能测试中,我们发现图像动态对象的构建,取、存像素时的边界检查对编译后的 WebAssembly 指令造成了远高于预期的性能影响。
在 Chrome 79 上,针对 2034x2034 大小的图像,WebAssembly 相较 JavaScript 带来的性能提升约 78.4%,尚可接受。但对于亮度、对比度、反相等复杂度较低的操作,耗时不降反升。比较极端的是在 Chrome 79 上:对比度、亮度的初始实现耗时为 JavaScript 2.6 — 2.7 倍,但这一差距并不能在 Firefox 上复现。
经过一些测试,我们最终使用了更朴素的 Vector(A contiguous growable array type in Rust)维护图像数据,同时牺牲了一定的安全性,规避了像素点索引的边界检查(直接按索引寻址而非带有 bound check 的 get_pixel),由此带来的性能提升是显著的。在 Chrome 79 / Firefox 72 上,对于 2304x2304 的图像,颜色混合函数的耗时较于最初的 Rust 实现,性能分别提升了 83.8% 和 83.2%。
(3)业务
浏览器中 Canvas 所需的,总是 RGBA 格式的图像,但在我们的业务系统中,图像总是无透明灰度的。因而在单个像素点计算中,RGB 三通道可复用同一计算结果,Alpha 通道置 255 即可。
这一优化主要试图覆盖查表法不适用的场景(e. g. 目标像素值不由单一像素点确定),而其效果在各版本浏览器中并不稳定(个别有 1% — 2% 的提升),我们不确定是否是因为部分 JavaScript 引擎在编译时做了诸如共有子表达式消除之类的优化。
2.锐化
我们实现的锐化函数,实际上为一个 kernel 大小为 3x3 的卷积。相较于“颜色混合”函数,最大的特点之一即单个目标像素值由 9 个源像素决定,且包含了 9 次乘法与 8 次加法,计算密度也显著更大。
(1)系统
在 Rust 的实现上,我们沿用了“颜色混合”函数中的思路,简化了对象使用和边界检查,在 Chrome 79 / Firefox 72 上,性能分别提升了 77.8% 和 88.8%。
然而我们发现,一旦处理图大小大于 2000x2000,纯 JavaScript 版本的锐化处理在诸如 Chrome 49/Windows XP 这样较低版本的配置上,可能耗时 8s 以上(在低配置 PC 上,峰值曾经达到 17s)。加之在交互设计中,锐化功能又采取了滑动条形式,实时性要求更高,这样的性能表现是无法接受的。
WebAssembly 不可用,WebGL 也无法在 Windows XP 上开启硬件加速,我们最终采取了 web worker 并行化计算的方案。当我们将单张目标图像以行拆分成 2 个块,用 2 个 worker 分别锐化时,块与块间相临的两行上的像素点的计算需要格外注意。
例如下图,原本红色行的值将与 kernel 对应位置相乘,最为下方黄色行卷积计算值的一部分,反之亦然。但当以虚线分割为上下两块独立计算后将不再互相影响,这将造成这两行的输出结果存在错误。
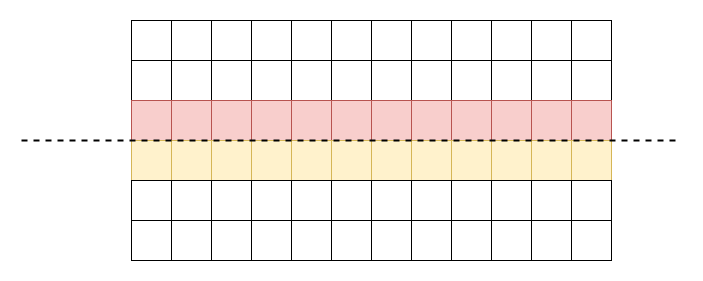
我们采取了一种简化的方式,使用了一个独立的 worker,单独计算各个边界。以 3 个 worker 为例,计算任务的划分可参见下图:
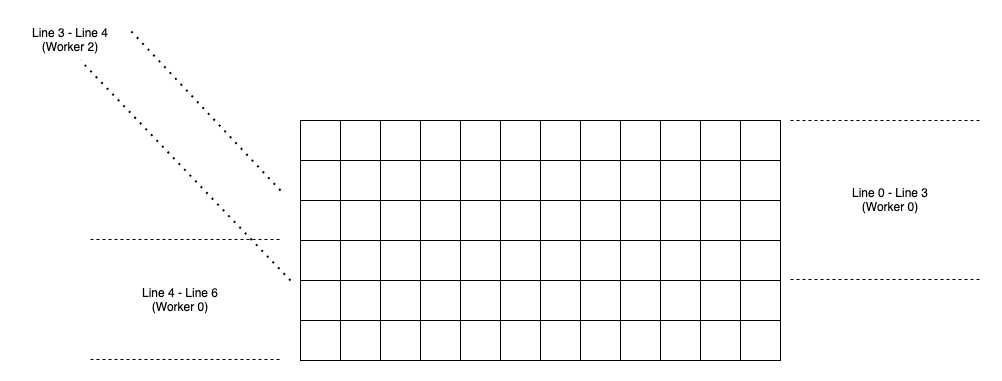
在实际应用中,对于大图,我们将之分为了 4 块,使用了 4 + 1 个 worker。这一实现在各个版本浏览器上的表现还是比较稳定的。
例如,在比较有代表性的 Chrome 49 上,平均性能提升约 69%,一定程度缓解了用户操作所感受到的卡顿。
3.其它
在一些特殊的场景下,我们也可能做算法、系统实现上做更整体性的替换,从而实现性能提升。
例如,我们的均衡滤镜实现较为特殊,流程中使用了较为昂贵的高斯模糊。在评估对计算结果准确度的要求后,我们参考了这篇文章,在 Rust 中实现了一套线性时间的近似高斯模糊算法,获得的性能提升约为 50%,我们也将这部分工作回馈了 Photon 项目。这一类的改动往往工作量、风险都更大,需要较多的评估与测试。
四、性能提升
下图展示了4 个系统中最常用的函数,优化前后的 Wasm 执行效率对比。整体性能提升还是较为显著的。
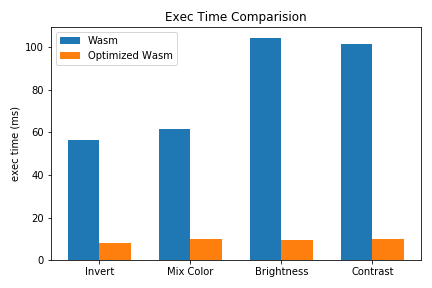
Browser: Chrome 79,Size: 2304x2304
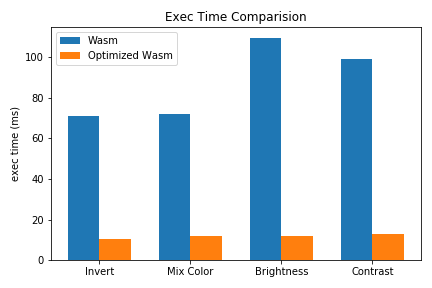
Browser: Firefox 72,Size: 2304x2304
五、总结
我们可以看到,对于计算密集型的 CV 处理而言,简单地通过替换 JavaScript 为 WebAssembly 的方案并非“银弹”。在具体场景中往往不能充分地压榨性能,从而达到理想的指标。在性能优化的过程中,对算法流程、系统实现、业务场景的理解均非常重要,基于此做细粒度的调优是值得尝试并能带来可观的性能收益的。
事实上,我们在广义的边缘端(网页前端、手机原生应用、嵌入式设备)上部署了大量的诸如 CV 处理、模型推理的计算密集型任务,而受制于设备性能、功耗等因素,以及无法避免的平台差异性,性能优化一直是一个比较有挑战的命题;我们也一直在持续地做多端的技术积累,以期能够在技术层面为系统功能提供更多的可能性。
墨奇科技有良好的工作环境和各种福利,让你能够充分的发挥自己的技术,不断挑战自我。墨奇全栈组在持续热招前端、后端、Android、C++、嵌入式等开发岗位↓
点我直接进入内推通道
版权归原作者 Moqi_AI 所有, 如有侵权,请联系我们删除。