
数据分析案例-大数据相关招聘岗位可视化分析

✍🏻作者简介:机器学习,深度学习,卷积神经网络处理,图像处理
🚀B站项目实战:https://space.bilibili.com/364224477
😄 如果文章对你有帮助的话, 欢迎评论 💬点赞👍🏻 收藏 📂加关注+
🤵♂代码获取:@个人主页
数据集介绍
本次数据集来源于xx招聘网共计4223条招聘信息,每条招聘信息字段包括岗位名称、公司名称、工作经验要求、学历要求、工作地点、薪酬、公司规模、发布时间、公司福利共9条字段信息。

数据预处理
首先导入本次数据集,
import pandas as pd
data = pd.read_csv('job_data.csv')
data.head()
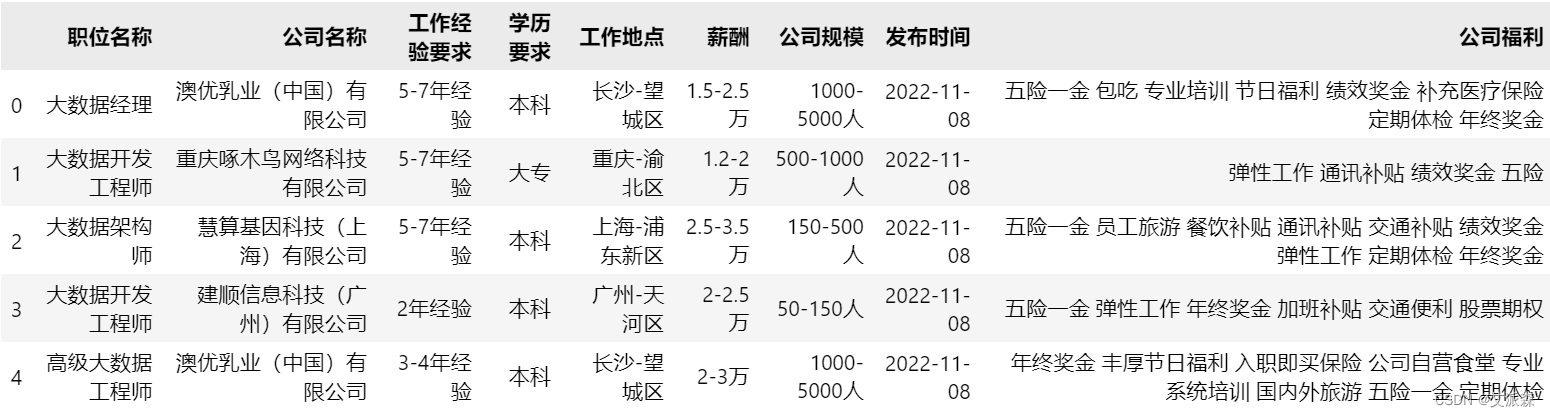
查看数据缺失值情况,
data.isnull().sum()

通过缺失值情况,我们发现公司规模缺失值较多,而这个字段数据对于本次分析没有太大用处,故在这里直接删除这一列,对于其他少量缺失值,直接删除就好。
data.drop('公司规模',axis=1,inplace=True)
data.dropna(inplace=True)
data.shape

接着就是处理数据集中的字段信息,便于后面的数据可视化
# 处理工作经验要求
data['工作经验要求'] = data['工作经验要求'].replace(to_replace=
{'无需经验':'经验不限','经验在校/应届':'经验不限','1年经验':'1-3年','2年经验':'1-3年','经验1-3年':'1-3年',
'经验1年以下':'1-3年','3-4年经验':'3-5年','经验3-5年':'3-5年','5-7年经验':'5-10年','经验5-10年':'5-10年',
'8-9年经验':'5-10年','10年以上经验':'10年以上','经验10年以上':'10年以上'})
# 处理学历要求
data['学历要求'] = data['学历要求'].replace(to_replace={'大专':'专科及以下','高中':'专科及以下','不限':'专科及以下','中技/中专':'专科及以下'})
# 获取工作城市
data['工作城市'] = data['工作地点'].apply(lambda x:x.split('-')[0])
data['工作城市'] = data['工作城市'].apply(lambda x:x.split('·')[0])
def avg_salary(x):
try:
start = x.split('-')[0]
end = x.split('-')[1]
if end[-1] == '千':
start_salary = float(start)*1000
end_salary = float(end[:-1])*1000
elif end[-1] == '万':
if start[-1] == '千':
start_salary = float(start[:-1])*1000
end_salary = float(end[:-1])*10000
else:
start_salary = float(start)*10000
end_salary = float(end[:-1])*10000
elif end[-1] == 'k':
start_salary = float(start[:-1])*1000
end_salary = float(end[:-1])*1000
elif end[-1] == '薪':
salary_number = float(end.split('·')[1][:-1])
if end.split('·')[0][-1] == '万':
if start[-1] == '千':
start_salary = float(start[:-1])*1000/12*salary_number
end_salary = float(end.split('·')[0][:-1])*10000/12*salary_number
else:
start_salary = float(start)*10000/12*salary_number
end_salary = float(end.split('·')[0][:-1])*10000/12*salary_number
elif end.split('·')[0][-1] == '千':
start_salary = float(start)*1000/12*salary_number
end_salary = float(end.split('·')[0][:-1])*1000/12*salary_number
elif end[-1] == '年':
end = end[:-2]
if end[-1] == '万':
if start[-1] == '千':
start_salary = float(start[:-1])*1000
end_salary = float(end[:-1])*10000
else:
start_salary = float(start)*10000
end_salary = float(end[:-1])*10000
return (start_salary+end_salary)/2
except:
return 10000
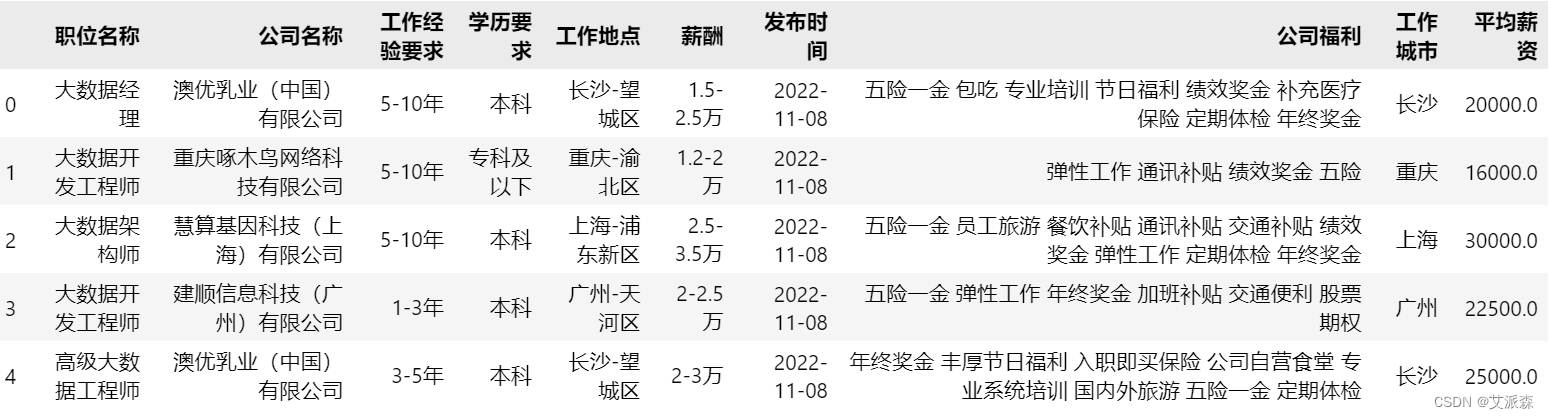
data['平均薪资'] = data['薪酬'].apply(avg_salary)
data.head()
在这里,我把工作经验和学历要求进行了清洗整理,划分为固定的几个分类,然后提取了工作城市,以及处理了原始薪资数据(数据是真的很杂,需要花点时间来处理),最后得到平均薪资。
数据可视化
先导入数据可视化需要用到的第三方包,
import pandas as pd
import matplotlib.pyplot as plt
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.globals import ThemeType
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签
plt.rcParams['axes.unicode_minus']=False
分析各工作经验要求占比
# 工作经验要求
df1 = data['工作经验要求'].value_counts()
a1 = Pie(init_opts=opts.InitOpts(theme = ThemeType.DARK))
a1.add(series_name='工作经验要求',
data_pair=[list(z) for z in zip(df1.index.to_list(),df1.values.tolist())],
radius='70%',
)
a1.set_global_opts(title_opts=opts.TitleOpts(title="工作经验要求占比",
pos_left='center',
pos_top=30))
a1.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger='item',formatter='{a} <br/>{b}:{c} ({d}%)'))
a1.render_notebook()
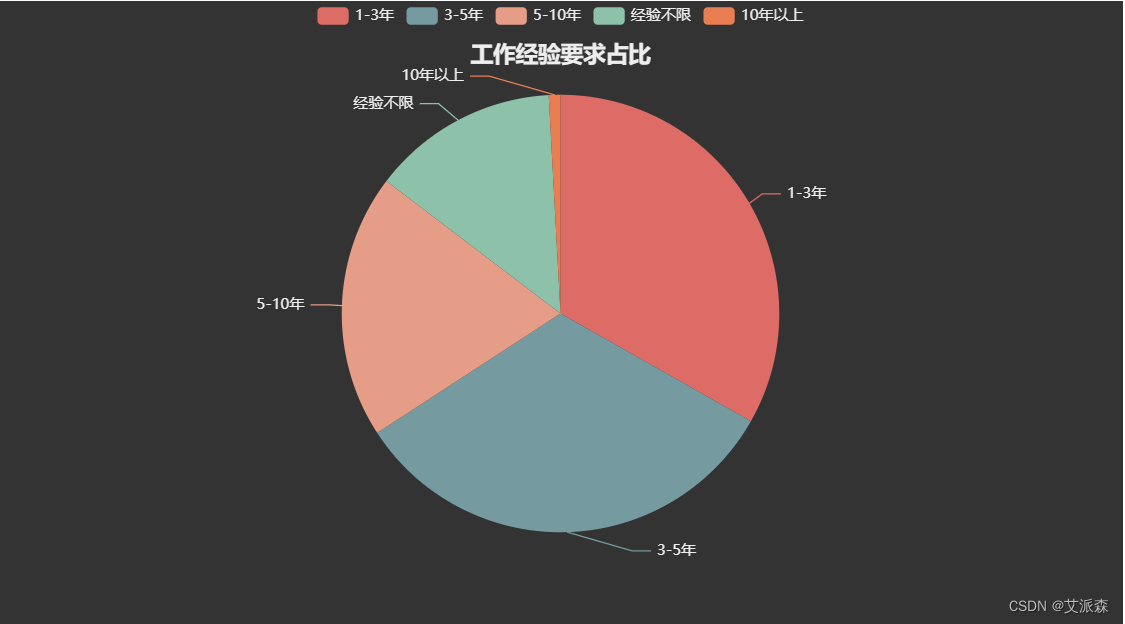
通过图表我们发现,除了10年以上,其他区间的经验要求占比相差不大,说明各个区间的经验要求需求岗位量大体相似。
** 分析不同工作经验的岗位数量和薪资变化**
x = ['经验不限','1-3年','3-5年','5-10年','10年以上']
bar =Bar()
bar.add_xaxis(x)
bar.add_yaxis('岗位数量',[399,724,870,535,27],label_opts=opts.LabelOpts(is_show=False))
bar.set_global_opts(
title_opts=opts.TitleOpts('不同工作经验的岗位数量和薪资变化'),
tooltip_opts=opts.TooltipOpts(is_show=True,trigger='axis',axis_pointer_type='cross'),
xaxis_opts= opts.AxisOpts(type_='category',axispointer_opts=opts.AxisPointerOpts(is_show=True,type_='shadow'))
)
bar.extend_axis(yaxis=opts.AxisOpts(
name='月薪',min_=0,max_= 110000,
interval = 10000
))
line = Line()
line.add_xaxis(x)
line.add_yaxis('平均薪资',[18468,17011,32701,40371,101429],yaxis_index=1,label_opts=opts.LabelOpts(is_show=False))
bar.overlap(line) # 合并图
bar.render_notebook()

通过图表,我们发现经验要求的需求量大体呈正态分布,薪酬是随着经验年限的增长而逐渐递增。
分析不同学历要求占比
# 学历要求
df2 = data['学历要求'].value_counts()
a2 = Pie(init_opts=opts.InitOpts(theme = ThemeType.DARK))
a2.add(series_name='学历要求',
data_pair=[list(z) for z in zip(df2.index.to_list(),df2.values.tolist())],
radius='70%',
)
a2.set_global_opts(title_opts=opts.TitleOpts(title="学历要求占比",
pos_left='center',
pos_top=30))
a2.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger='item',formatter='{a} <br/>{b}:{c} ({d}%)'))
a2.render_notebook()

通过图表我们发现,本科学历占据了65%,本科及以下共高达95%,对于学历这块,要求似乎要求不是很高。
分析不同学历要求的岗位数量和薪酬变化
x = ['专科及以下','本科','硕士','博士']
bar =Bar()
bar.add_xaxis(x)
bar.add_yaxis('岗位数量',[684,1753,109,9],label_opts=opts.LabelOpts(is_show=False))
bar.set_global_opts(
title_opts=opts.TitleOpts('不同学历要求的岗位数量和薪资变化'),
tooltip_opts=opts.TooltipOpts(is_show=True,trigger='axis',axis_pointer_type='cross'),
xaxis_opts= opts.AxisOpts(type_='category',axispointer_opts=opts.AxisPointerOpts(is_show=True,type_='shadow'))
)
bar.extend_axis(yaxis=opts.AxisOpts(
name='月薪',min_=0,max_= 45000
))
line = Line()
line.add_xaxis(x)
line.add_yaxis('平均薪资',[11888,33784,44118,34148],yaxis_index=1,label_opts=opts.LabelOpts(is_show=False))
bar.overlap(line) # 合并图
bar.render_notebook()

随着学历的增长,薪资也在增长,这里博士学历应该是数据量太少导致出现了下滑异常,总体趋势肯定还是学历越高,薪资越高。
**分析岗位需求量最高的前五名公司 **
data['公司名称'].value_counts().head().plot(kind='barh')
plt.title('岗位需求量最高的前五名公司')
plt.show()
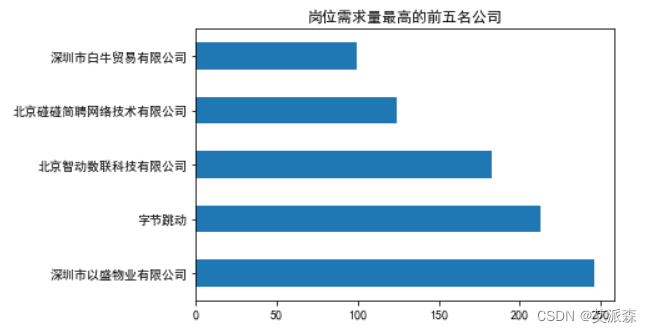
岗位需求量大的公司貌似都集中在深圳北京等一线城市。
词云图可视化
先定义一个制作词云图的函数
import jieba
import collections
import re
import stylecloud
from PIL import Image
# 封装一个画词云图的函数
def draw_WorldCloud(df,pic_name,color='black'):
data = ''.join([item for item in df])
# 文本预处理 :去除一些无用的字符只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = "".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data, cut_all=True)
result_list = []
with open('停用词库.txt', encoding='utf-8') as f: #可根据需要打开停用词库,然后加上不想显示的词语
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
for word in seg_list_exact:
if word not in stop_words and len(word) > 1:
result_list.append(word)
word_counts = collections.Counter(result_list)
# 词频统计:获取前100最高频的词
word_counts_top = word_counts.most_common(100)
print(word_counts_top)
# 绘制词云图
stylecloud.gen_stylecloud(text=' '.join(result_list),
collocations=False, # 是否包括两个单词的搭配(二字组)
font_path=r'C:\Windows\Fonts\msyh.ttc', #设置字体
size=800, # stylecloud 的大小
palette='cartocolors.qualitative.Bold_7', # 调色板
background_color=color, # 背景颜色
icon_name='fas fa-circle', # 形状的图标名称
gradient='horizontal', # 梯度方向
max_words=2000, # stylecloud 可包含的最大单词数
max_font_size=150, # stylecloud 中的最大字号
stopwords=True, # 布尔值,用于筛除常见禁用词
output_name=f'{pic_name}.png') # 输出图片
# 打开图片展示
img=Image.open(f'{pic_name}.png')
img.show()
接着使用岗位名称数据来进行词云图可视化,看看大数据相关岗位的情况
draw_WorldCloud(data['职位名称'],'大数据职位名称词云图')

通过词云图发现,大数据相关岗位大体主要分为数据分析、大数据开发、架构师等。
使用公司福利数据来词云图分析一下
draw_WorldCloud(data['公司福利'],'公司福利词云图')

通过词云图看出,大数据相关岗位福利主要为各种奖金、补贴、培训等等。
通过热力地图分析各城市岗位分布
df3 = data['工作城市'].value_counts()
city_data = city_data = [[x+'市',y] if x[-3:] != '自治州' else [x,y] for x,y in zip(df3.index.to_list(),df3.values.tolist())]
map = Map()
map.add('地区',city_data,
maptype='china-cities',
is_map_symbol_show=False,
label_opts=opts.LabelOpts(is_show=False))
map.set_global_opts(
title_opts=opts.TitleOpts('各城市岗位数量分布'),
visualmap_opts=opts.VisualMapOpts(max_=100,min_=1)
)
map.render(path='各城市岗位数量分布.html')
map.render_notebook()
通过热力地图我们看出,大数据岗位在上海,北京、深圳等城市需求量较高 。(热力地图如在手机端无法查看可用PC端打开查看)
✍🏻作者简介:机器学习,深度学习,卷积神经网络处理,图像处理
🚀B站项目实战:https://space.bilibili.com/364224477
😄 如果文章对你有帮助的话, 欢迎评论 💬点赞👍🏻 收藏 📂加关注+
🤵♂代码获取:@个人主页
版权归原作者 Jackie_AI 所有, 如有侵权,请联系我们删除。