parcharm+selenium+webdriver+chrome报错
运行from selenium import webdriver。
Anaconda 环境下的 Python-Selenium 与 Edge 驱动配置全攻略
在 Anaconda 环境下安装和配置 Selenium,以及设置 Edge 浏览器驱动,是开始自动化测试或爬虫项目的关键步骤。本文将详细介绍如何在 Anaconda 环境中安装 Selenium 库,并配置 Microsoft Edge 浏览器驱动。通过以上步骤,您已经在 Anaconda 环境中
【python爬虫】超越Selenium的自动化爬虫神器--DrissionPage语法解析与应用实战
DrissionPage 是一个基于 Python 的网页自动化和抓取工具,它通过整合 Selenium 和 Requests 的优点,提供了高效、简洁的网页操作和数据抓取解决方案。无论是浏览器自动化控制,还是直接发送和接收数据包,DrissionPage 都以页面为单位进行封装,极大地降低了开发难
【技术前沿】 Deep-Live-Cam入门部署教程-实时AI换脸、开源、一键、免费!
最近有一个爆火的Github项目叫做 Deep-Live-Cam。它可以用 AI 技术在直播的时候,实时生成虚拟人脸。它的作用是让你在直播的时候,保护你的隐私,同时也可以让你看起来很酷(By 项目原作者)。这个项目特别适合那些喜欢直播又想保护自己隐私的人使用。项目的代码托管在GitHub 上。通过访
web自动化测试框架-selenium
selenium是一个用于web应用的工具:可以实现web自动化测试,以及爬虫。可以在多个浏览器上进行自动化测试。
Python爬虫——Selenium方法爬取LOL页面
Selenium介绍、用Selenium方法爬取LOL每个英雄的图片及名字
【Datawhale AI 夏令营】电力需求预测 Task01
给定多个房屋对应电力消耗历史N天的相关序列数据等信息,预测房屋对应电力的消耗。也就是一个时序预测问题数据集由字段id(房屋id)、 dt(日标识)、type(房屋类型)、target(实际电力消耗)组成。
W30-python01-Selenium Web自动化基础--百度搜索案例-chrome浏览器为例
come on my python ,day day day up
MoneyPrinterTurbo本机利用AI大模型,一键生成高清短视频
开始之前一定要仔细阅读说明再开始,避免浪费时间。下载一键启动包,解压直接使用下载后,建议先update.bat更新到,然后双击start.bat启动Web界面下载后开始安装:pip版本太低,要求升级pip,好吧,升级。继续,又说我python版本低,没办法去下载吧。访问不了在这里下载的。直接安装即可
揭秘,PyArmor库让你的Python代码更安全
PyArmor库让你的Python代码更安全的工具
WiseFlow:开源AI信息挖掘工具,传统的爬虫可以下线了
是一款快速准确的信息挖掘工具。我们在使用时提前设定好自己的。
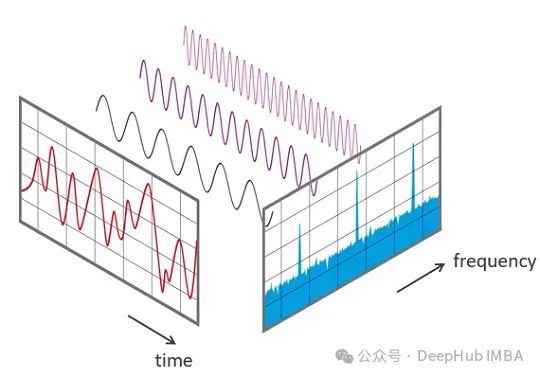
音频去噪:使用Python和FFT增强音质
声音去噪目标是改善聆听体验以及音频分析和处理的准确性。过滤掉噪音对于高保真音频来说非常重要,不仅是为了聆听,也是为了创建某些机器学习任务的数据集。
Spark 大规模机器学习(一)
原文:zh.annas-archive.org/md5/7A35D303E4132E910DFC5ADB5679B82A译者:飞龙协议:CC BY-NC-SA 4.0前言机器学习的核心是关注将原始数据转化为可操作智能的算法。这一事实使得机器学习非常适合于大数据的预测分析。因此,如果没有机器学习,要跟
Django:五、登录界面实现动态图片验证码
登录界面实现动态图片验证码
Datewhale AI夏令营第四期 AIGC方向Task1笔记
应用简介:可图是快手开源的一种名为Kolors(可图)的文本到图像生成模型,该模型具有对英语和汉语的深刻理解,并能够生成高质量、逼真的图像。下次进行文生图时描述应该更加具体(对于人的五官,神情,手指动作,物象的状态外形,大环境等),保持人物形象描述的一致等细节。prompt="二次元,一个紫色短发小
python爬虫------- Selenium下篇(二十三天)
🎈🎈作者主页:🎈🎈🎈🎈✨✨helllo,兄弟姐妹们!今天我们接着把第二十二天剩下的十个知识点学完(从第十个开始)。
【Python】PyWebIO 初体验:用 Python 写网页
在 Github 上看到一个有意思的项目:PyWebIo。它是一个 Python 第三方库,可以只用 Python 语言写出一个网页,而且支持 Flask,Django,Tornado 等 web 框架。
Scala 和 Spark 大数据分析(一)
原文:zh.annas-archive.org/md5/39EECC62E023387EE8C22CA10D1A221A译者:飞龙协议:CC BY-NC-SA 4.0前言数据持续增长,加上对这些数据进行越来越复杂的决策的需求,正在创造巨大的障碍,阻止组织利用传统的分析方法及时获取洞察力。大数据领域与
Python中高效处理大数据的几种方法
Pandas是Python中一个强大的数据分析库,提供了快速、灵活和表达式丰富的数据结构,旨在使“关系”或“标签”数据的处理既简单又直观。Pandas非常适合于处理表格数据,如CSV、Excel等。NumPy是Python的一个库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库
Python 进行单元测试
单元测试是软件开发过程中的一个关键步骤,用于验证程序的各个部分(单元)是否按预期工作。Python 提供了多种进行单元测试的方法,其中最常用的框架是unittest。



