公益AI免登录无限制
大家好,我们很高兴地宣布,我们最近完成了一个重要的项目,这也是我们这段时间没有更新的原因。这段时间我们一直在忙于搭建一个公益网站,旨在让所有人都能便捷地使用 GPT 模型,而不需要登录、翻墙或支付任何费用,如果有更好的建议可以联系我。
【python实战】利用代理ip爬取Alibaba海外版数据
对于希望获取跨境市场信息的企业来说,这些限制带来了巨大的挑战,尤其是在需要获取实时且准确的数据时,传统的爬虫技术往往面临失效的风险。然后,进入一个循环,在每一页中构造相应的URL,调用get_ip()获取代理IP,使用get_page()获取该页的HTML,接着调用parse_page()提取供应商
《人工智能》—— Python编程语言
Python基本语法与数据类型Python语言基本语法t = input('请输入带符号的温度值:') # 用键盘输入温度值print('转换后的温度是{:.2f}C'.format(c))print('转换后的温度是{:.2f}F'.format(f))else:print("输入格式错误")其中
Web自动化测试之selenium环境搭建
【代码】Web自动化测试之selenium环境搭建。
Python 连接和操作 PostgreSQL 数据库的详解
Python 作为一种高级编程语言,因其简洁易读的语法和丰富的库支持,成为了数据处理和数据库操作的理想选择。本文将详细介绍如何使用 Python 连接和操作 PostgreSQL 数据库,包括环境搭建、连接数据库、执行 SQL 查询和更新操作,以及处理异常和事务管理等内容。从环境搭建到高级功能的使用
探索 ShellGPT:终端中的 AI 助手
在当今快速发展的技术领域,命令行界面(CLI)依然是开发者和系统管理员的强大工具。但记忆复杂的命令和语法对于新手来说可能是个挑战。这就是ShellGPT库应运而生的原因。它是一个基于 AI 大型语言模型(LLM)的命令行工具,能够理解自然语言并生成相应的 shell 命令、代码片段和文档,极大地提高
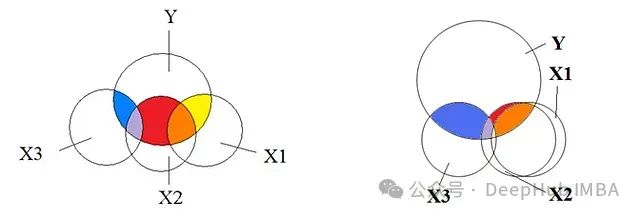
深入理解多重共线性:基本原理、影响、检验与修正策略
本文将深入探讨多重共线性的本质,阐述其重要性,并提供有效处理多重共线性的方法,同时避免数据科学家常犯的陷阱。
使用Python和Selenium获取BOOS直聘职位信息
spider类是爬虫的核心,它接受职位类型和起始页面作为参数,并初始化爬取的URL模板。page=是页数通过上述步骤,可以自动爬取招聘网站上的职位信息,并将其整理成结构化的数据。这不仅节省了大量的手动查找和整理时间,还可以为后续的数据分析和决策提供支持。但是这段代码只是实现了基本的爬虫功能,其实还有
【Python数据分析】利用Pandas库轻松处理大数据
Pandas是基于Python的开源数据分析库,主要用于处理和分析结构化数据。Pandas提供了高效的数据结构,主要是Series和DataFrame,并为数据处理、清洗和转换等操作提供了丰富的API。Series: 一维数据结构,类似于Python中的列表和字典。DataFrame: 二维表格数据
毕设开源 深度学习的人体跌倒检测与识别(源码+论文)
🔥这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是🚩毕业设计 深度学习的人体跌倒检测与识别(源码
【果蔬识别】Python+卷积神经网络算法+深度学习+人工智能+机器学习+TensorFlow+计算机课设项目+算法模型
果蔬识别系统,本系统使用Python作为主要开发语言,通过收集了12种常见的水果和蔬菜(‘土豆’, ‘圣女果’, ‘大白菜’, ‘大葱’, ‘梨’, ‘胡萝卜’, ‘芒果’, ‘苹果’, ‘西红柿’, ‘韭菜’, ‘香蕉’, ‘黄瓜’),然后基于TensorFlow库搭建CNN卷积神经网络算法模型,
Pyspark中pyspark.sql.functions常用方法(1)
是 PySpark 中用于定义用户自定义函数(UDF)的工具。UDF允许你在Spark DataFrame中使用Python函数处理数据。UDF的性能通常不如内置的Spark函数,因为它们会引入额外的Python虚拟机开销。只有当没有其他选项时才应该使用UDF。# 自定义函数df2.show()#
使用Selenium时,如何模拟正常用户行为?
Selenium作为自动化测试和网页数据抓取的利器,被广泛应用于自动化网页交互、爬虫开发等领域。然而,随着网站反爬虫技术的不断升级,简单的自动化脚本很容易被识别和阻止。因此,模拟正常用户行为,降低被检测的风险,成为Selenium使用者必须掌握的技能。本文将详细介绍如何使用Selenium模拟正常用
python selenium4 EdgeDriver动态页面爬取
截止至2024.7.16chrome浏览器最新版本为126.0.6478.127但对应的chromeDriver版本都低于此版本,因此,转用Edge浏览器。
Python毕业设计-基于 Python flask 的前程无忧招聘可视化系统,Python大数据招聘爬虫可视化分析
嗨喽,大家好,今天为大家带来的是Python 基于 flask 的前程无忧招聘可视化系统,Python大数据招聘爬虫可视化分析,该项目使用 flask框架,Mysql 数据库,request,selenium 框架进行爬虫,实现招聘数据的采集,清洗等,该项目总体来说还是挺不错的,界面美观,可用于 P
通义灵码-----阿里巴巴推出的 AI 编程助手,一站式安装使用教程。 我自己就是在用,感觉写代码会高效很多
通义灵码是阿里巴巴推出的一个 AI 编程助手插件,提供了多种智能辅助功能。可以帮助我们更高效的编写代码。
SMOTE算法进行过采样
【代码】SMOTE算法进行过采样。
【Python开发实践】AI人机对战五子棋——AI功能实现
人机对战五子棋——AI功能实现
Python毕业设计选题:基于协同过滤的校园音乐推荐系统小程序-django+uniapp
小程序首页是用户注册登录后进入的第一个界面,用户可通过小程序端首页进入对应的页面或者通过小程序最下面的那一行导航栏中的“首页、音乐信息、我的”,也可以点击“我的”进入我的页面,在我的页面可以对我的收藏管理、留言板等进行详细操作。管理员登录系统后,可以对系统首页、个人中心、用户管理、音乐信息管理、音乐
在Pycharm中新建虚拟环境的方法并使用
虚拟环境是在本地创建一个独立的Python环境,这个环境拥有自己的独立的Python解释器和包管理器,不与系统环境和其他虚拟环境产生干扰。



