
主动学习是指对需要标记的数据进行优先排序的过程,这样可以确定哪些数据对训练监督模型产生最大的影响。
- 主动学习是一种学习算法可以交互式查询用户(teacher 或 oracle),用真实标签标注新数据点的策略。主动学习的过程也被称为优化实验设计。
- 主动学习的动机在于认识到并非所有标有标签的样本都同等重要。
- 主动学习通过为专家的标记工作进行优先级排序可以大大减少训练模型所需的标记数据量。降低成本,同时提高准确性。
- 主动学习是一种策略/算法,是对现有模型的增强。而不是新模型架构。
- 主动学习容易理解,不容易执行
主动学习背后的关键思想是,如果允许机器学习算法选择它学习的数据,这样就可以用更少的训练标签实现更高的准确性。——Active Learning Literature Survey, Burr Settles
主动学习简介
主动学习不是一次为所有的数据收集所有的标签,而是对模型理解最困难的数据进行优先级排序,并仅对那些数据要求标注标签。然后模型对少量已标记的数据进行训练,训练完成后再次要求对最不确定数据进行更多的标记。
通过对不确定的样本进行优先排序,模型可以让专家(人工)集中精力提供最有用的信息。这有助于模型更快地学习,并让专家跳过对模型没有太大帮助的数据。这样在某些情况下,可以大大减少需要从专家那里收集的标签数量,并且仍然可以得到一个很好的模型。这样可以为机器学习项目节省时间和金钱!
主动学习的策略
有很多论文介绍了多种如何确定数据点以及如何在方法上进行迭代的方法。本文中将介绍最常见和最直接的方法,因为这是最简单也最容易理解的。
在未标记的数据集上使用主动学习的步骤是:
- 首先需要做的是需要手动标记该数据的一个非常小的子样本。
- 一旦有少量的标记数据,就需要对其进行训练。该模型当然不会很棒,但是将帮助我们了解参数空间的哪些领域需要首标记。
- 训练模型后,该模型用于预测每个剩余的未标记数据点的类别。
- 根据模型的预测,在每个未标记的数据点上选择分数(在下一节中,将介绍一些最常用的分数)
- 一旦选择了对标签进行优先排序的最佳方法,这个过程就可以进行迭代重复:在基于优先级分数进行标记的新标签数据集上训练新模型。一旦在数据子集上训练完新模型,未标记的数据点就可以在模型中运行并更新优先级分值,继续标记。
通过这种方式,随着模型变得越来越好,我们可以不断优化标签策略。
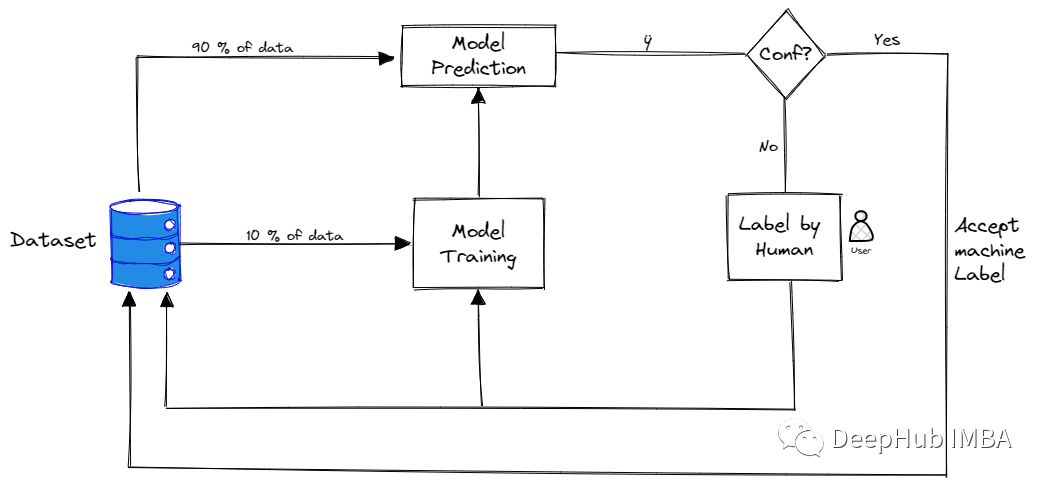
基于数据流的主动学习方法
在基于流的主动学习中,所有训练样本的集合以流的形式呈现给算法。每个样本都被单独发送给算法。算法必须立即决定是否标记这个示例。从这个池中选择的训练样本由oracle(人工的行业专家)标记,在显示下一个样本之前,该标记立即由算法接收。
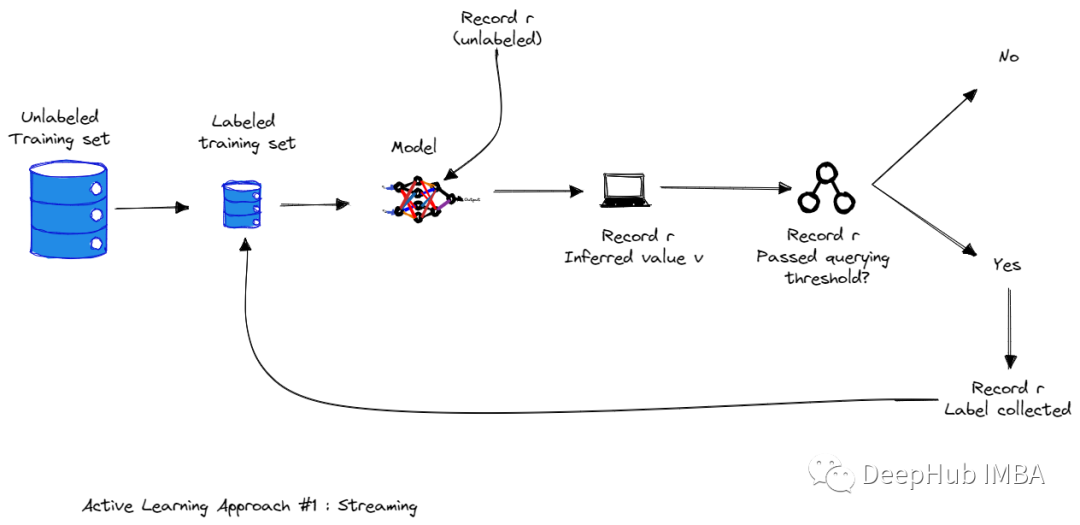
基于数据池的主动学习方法
在基于池的抽样中,训练样本从一个大的未标记数据池中选择。从这个池中选择的训练样本由oracle标记。
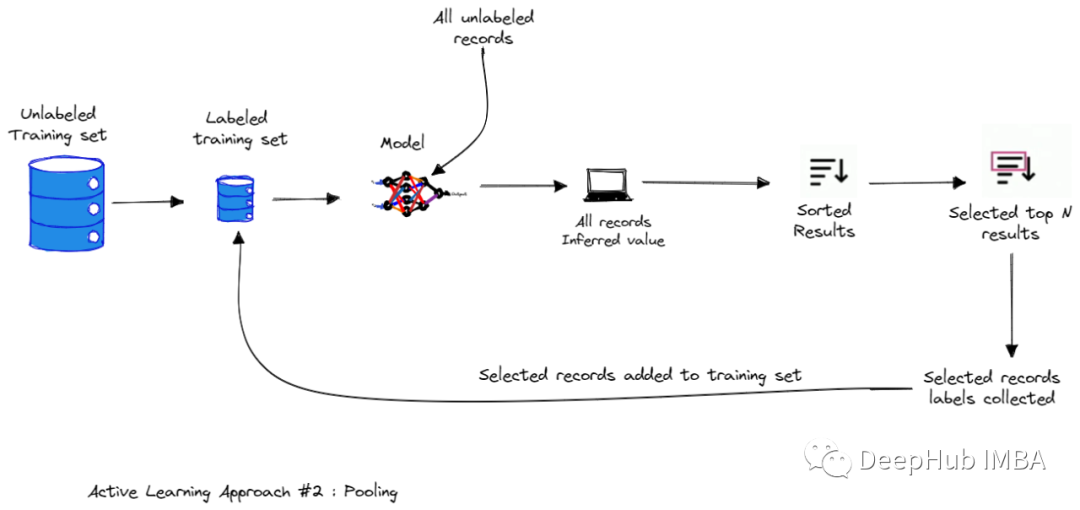
基于查询的主动学习方法
这种基于委员会查询的方法使用多个模型而不是一个模型。
委员会查询(Query by Committee),它维护一个模型集合(集合被称为委员会),通过查询(投票)选择最“有争议”的数据点作为下一个需要标记的数据点。通过这种委员会可的模式以克服一个单一模型所能表达的限制性假设(并且在任务开始时我们也不知道应该使用什么假设)。
不确定性度量
识别接下来需要标记的最有价值的样本的过程被称为“抽样策略”或“查询策略”。在该过程中的评分函数称为“acquisition function”。该分数的含义是:得分越高的数据点被标记后,对模型训练后的产生价值就越高(没模型效果好)。有很多中不同的采样策略,例如不确定性抽样,多样性采样,预期模型更改…,在本文中,我们将仅关注最常用策略的不确定性度量。
不确定性抽样是一组技术,可以用于识别当前机器学习模型中的决策边界附近的未标记样本。这里信息最丰富的例子是分类器最不确定的例子。模型最不确定性的样本可能是在分类边界附近的数据。而我们模型学习的算法将通过观察这些分类最困难的样本来获得有关类边界的更多的信息。
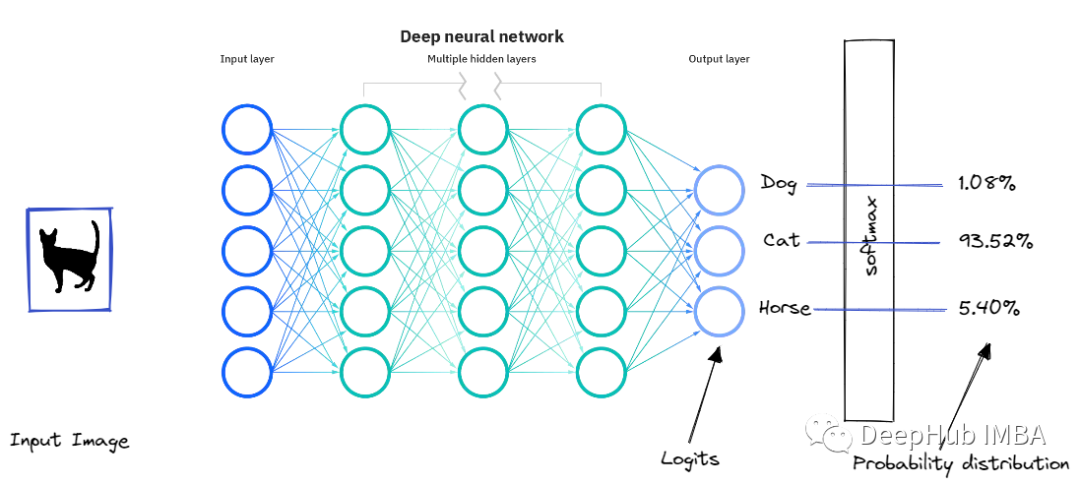
让我们以一个具体的例子,假设正在尝试建立一个多类分类,以区分3类猫,狗,马。该模型可能会给我们以下预测:
{
"Prediction": {
"Label": "Cat",
"Prob": {
"Cat": 0.9352784428596497,
"Horse": 0.05409964170306921,
"Dog": 0.038225741147994995,
}
}
}
这个输出很可能来自softmax,它使用指数将对数转换为0-1范围的分数。
最小置信度:(Least confidence)
最小置信度=1(100%置信度)和每个项目的最自信的标签之间的差异。
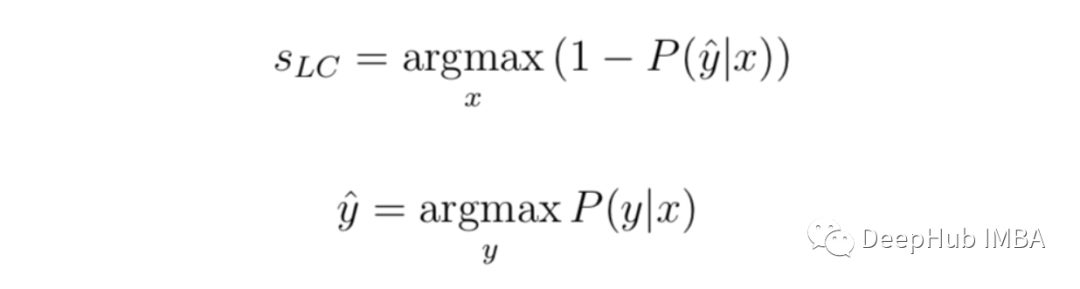
虽然可以单独按置信度的顺序进行排名,但将不确定性得分转换为0-1范围,其中1是最不确定的分数可能很有用。因为在这种情况下,我们必须将分数标准化。我们从1中减去该值,将结果乘以N/(1-N),n为标签数。这时因为最低置信度永远不会小于标签数量(所有标签都具有相同的预测置信度的时候)。
让我们将其应用到上面的示例中,不确定性分数将是:(1-0.9352) *(3/2)= 0.0972。
最小置信度是最简单,最常用的方法,它提供预测顺序的排名,这样可以以最低的置信度对其预测标签进行采样。
置信度抽样间距(margin of confidence sampling)
不确定性抽样的最直观形式是两个置信度做高的预测之间的差值。也就是说,对于该模型预测的标签对比第二高的标签的差异有多大?这被定义为:
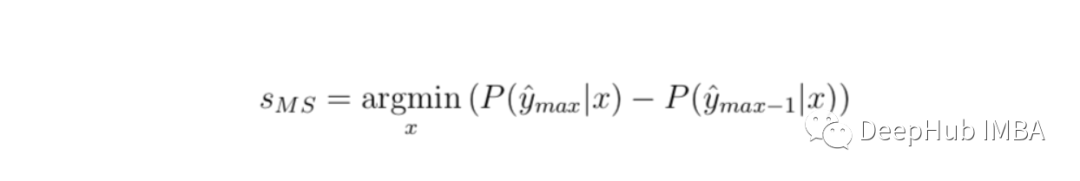
同样我们可以将其转换为0-1范围,必须再次使用1减去该值,但是最大可能的分数已经为1了,所以不需要再进行其他操作。
让我们将置信度抽样间距应用于上面的示例数据。“猫”和“马”是前两个。使用我们的示例,这种不确定性得分将为1.0 - (0.9352–0.0540)= 0.1188。
抽样比率 (Ratio sampling)
置信度比是置信度边缘的变化,是两个分数之间的差异比率而不是间距的差异的绝对值。
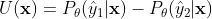
熵抽样(Entropy Sampling)
应用于概率分布的熵包括将每个概率乘以其自身的对数,然后求和取负数:
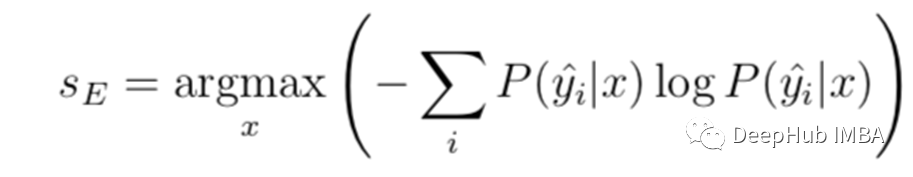
让我们在示例数据上计算熵:
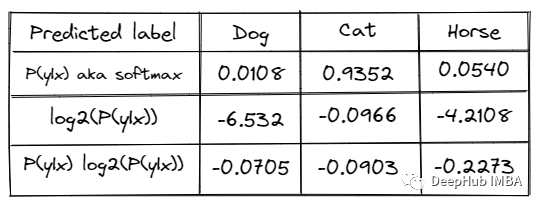
得到 0 - sum(–0.0705,–0.0903,–0.2273)= 0.3881
除以标签数的log得到0.3881/ log2(3)= 0.6151
总结
机器学习社区的大部分重点是创建更好的算法来从数据中学习。获得有用是标注数据在训练时是非常重要的,但是标注数据可能很非常的费事费力,并且如果标注的质量不佳也会对训练产生很大的影响。主动学习是解决这个问题的一个方向,并且是一个非常好的方向。
作者:Zakarya ROUZKI