elasticsearch系统学习笔记9-聚合分析 Aggregations
elasticsearch系统学习笔记9-聚合分析 Aggregations概念分类指标聚合数据准备max 统计最大值min 统计最小值value_count 统计文档数量cardinality 基数统计(统计去重后的文档数量)avg 计算平均值sum 计算总和stats 基本统计extended_
09、Hadoop框架Zookeeper Java API
Hadoop框架Zookeeper Java API
RabbitMQ不公平分发和预取值(channel.basicQos)
Qos(Quality of Service,服务质量)概念:当网络发生拥塞的时候,所有的数据流都有可能被丢弃;为满足用户对不同应用不同服务质量的要求,就需要网络能根据用户的要求分配和调度资源,对不同的数据流提供不同的服务质量:对实时性强且重要的数据报文优先处理;对于实时性不强的普通数据报文,提供较
情人节撩妹装逼小方法,一学就会
情人节撩妹小技巧1、右键新建,选择新建文本文件(可以根据自己的需要修改名字)。2、打开新建的文本文件,输入如图的字符:msgbox("此处可替换成你想要出现的文字"),括号和引号是英文状态下的标点。(可根据自己的需要输入多行)msgbox("在吗")msgbox("其实我一直在寻觅有什么方法可以不去
08、Hadoop框架HDFS HA 的高可用
Hadoop框架HDFS HA 的高可用
漫谈数据治理一-数据老有问题,我们该如何提高数据质量?
一、前言大家好,我是王老狮,狮是工程师的狮哈。细心地小伙伴应该发现我改名字了,具体改名原因呢?毕竟过了一年了,我也成长了,DarkKing感觉有点太中二了,因此换个成熟稳重一点的名字。(难道我会告诉你我有起名困难症吗?)随着互联网后期以及物联网的崛起,甚至互联网公司们已经不满足现实世界,诞生了元宇宙
04、Hadoop框架HDFS NN、SNN、DN工作原理
Hadoop框架HDFS NN、SNN、DN工作原理
spark运行架构和基础
基本 概念RDD:(官方概念)弹性分布式数据集,就是一个个的在内存里的数据。就是数据的基本单位,所有spark都是来操作他的 DAG 是有向无环图,它的作用主要是反应rdd之间的关系。 Excutor 就是一个容器,就像Hadoop的node一样,用来运行的 应用 顾名思义来编写spark程序的 任
RabbitMQ入门小结
RabbitMQ概述RabbitMQ是基于Erlang语言开发的开源消息通信中间件,官网地址:Messaging that just works — RabbitMQ
06、Hadoop框架HDFS读写流程
Hadoop框架HDFS读写流程
【如何成为SQL高手】第九关:高级复杂查询
高级复杂查询
在Windows系统上安装zookeeper
文章目录概述下载安装单机版集群版配置介绍概述ZooKeeper 是分布式应用程序的高性能协调服务。它在一个简单的界面中公开了常用服务,例如命名、配置管理、同步和组服务,因此可以不必从头开始编写它们。可以现成地使用它来实现共识、组管理、领导者选举和存在协议,也可以根据自己的特定需求在此基础上进行构建。
点击曝光日志的数据处理
点击曝光日志的基本处理方法
RabbitMQ之如何保证发送消息的可靠性?
1.消费发送的机制1.1消息发送我们都知道会先发送到交换机上,然后再根据定的路由规则,由交换机将消息路由到不同的 Queue(队列)中,再由不同的消费者去消费。如下图所以我们就应该保证消息成功到达交换机 和对列,如果都做到了纳闷我们消息就发送成功了对吧2.常见的方案2.1开启事务机制2.2 发送方确
Elastic Stack 8.0 安装 - 保护你的 Elastic Stack 现在比以往任何时候都简单
在 8.0 中,我们很高兴为所有用户带来简化的安全功能。 从 7.1 开始,我们向所有人免费提供了确保 Elastic Stack 安全所需的所有功能。然而,我们知道设置安全性并不好玩,你需要专注于你的项目目标。 好消息给你! 从 8.0 开始,自管理集群默认启用 Elastic Stack 安全性
Flink常用算子
OperatorsmapDataStream → DataStreamflatMapDataStream → DataStreamfliterDataStream → DataStreamkeyByDataStream → KeyedStream对数据进行分流reduceKeyedStream/Ke
Linux 部署项目
文章目录:一、官网下载压缩包二、配置安装三、打包发布
开源云原生大潮下的消息和流系统演进
云原生的诞生是为了解决传统应用在架构、故障处理、系统迭代等方面的问题,而开源则为企业打造云原生的架构贡献了中坚力量。本文作者在全身心投入开源以及每日参与云原生的过程中,对开源行业和云原生流系统解决方案有了不一样的思考与实践。作者 | 李鹏辉 责编 | 唐小引出品 | 新程序员随着业务与环
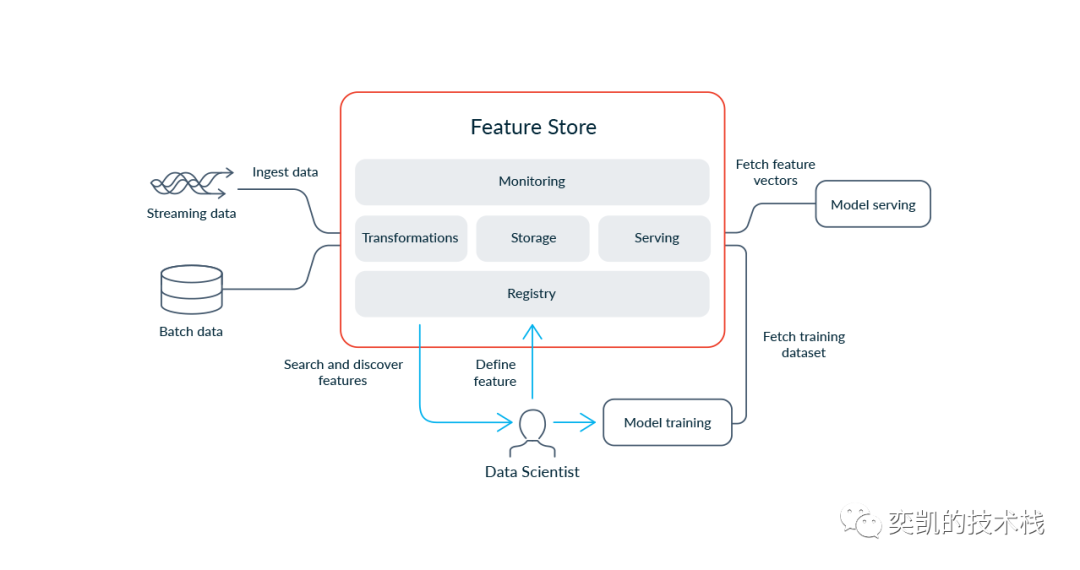
你真的需要特征存储吗?
如无必要 勿增实体
Flink常见机制
反压机制Flink在1.5版本之前是基于TCP的流量控制和反压的。缺点:一个TaskManager执行的一个Task触发反压,该TaskManager和上游TaskManager的Socket就不能传输数据,从而影响到其他Task,也会影响到Barrier的流动,导致作业雪崩。在1.5版本之后,Fl



