
文章目录
Hadoop框架HDFS HA 的高可用
hdfs的HA (高可用)
zk:指zookeeper,负责协调,监控
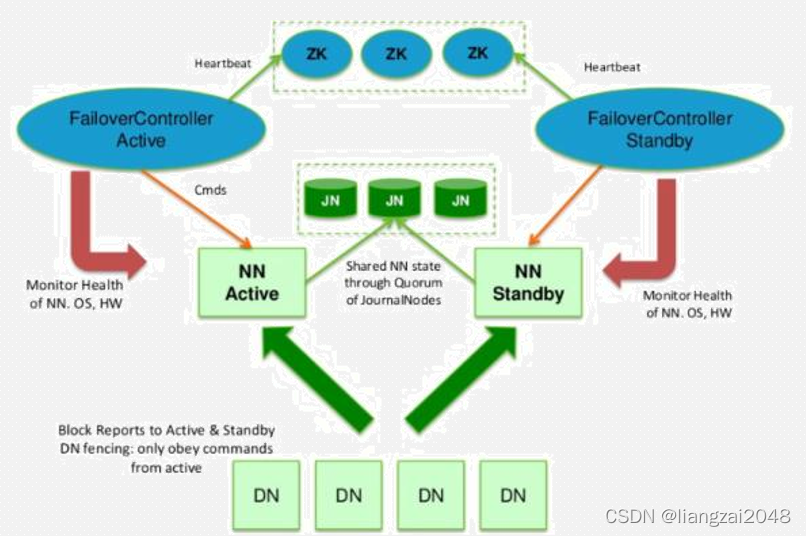
HA的failover原理
- HDFS的HA,指的是在一个集群中存在两个NameNode,分别运行在独立的物理节点上。在任何时间点,只有一个NameNodes是处于Active状态,另一种是在Standby状态。 Active NameNode负责所有的客户端的操作,而Standby NameNode用来同步Active NameNode的状态信息,以提供快速的故障恢复能力。
- 为了保证Active NN与Standby NN节点状态同步,即元数据保持一致。除了DataNode需要向两个NN发送block位置信息外,还构建了一组独立的守护进程”JournalNodes”,用来同步Edits信息。当Active NN执行任何有关命名空间的修改,它需要持久化到一半以上的JournalNodes上。而Standby NN负责观察JNs的变化,读取从Active NN发送过来的Edits信息,并更新自己内部的命名空间。一旦ActiveNN遇到错误,Standby NN需要保证从JNs中读出了全部的Edits,然后切换成Active状态。
使用HA的时候,不能启动SecondaryNameNode,会出错。
HDFS的federation
- HDFS Federation设计可解决单一命名空间存在的以下几个问题: - 1、 HDFS集群扩展性。多个NameNode分管一部分目录,使得一个集群可以扩展到更多节点,不再像1.0中那样由于内存的限制制约文件存储数目。- 2、性能更高效。多个NameNode管理不同的数据,且同时对外提供服务,将为用户提供更高的读写吞吐率。- 3、良好的隔离性。用户可根据需要将不同业务数据交由不同NameNode管理,这样不同业务之间影响很小。
federation架构图-1
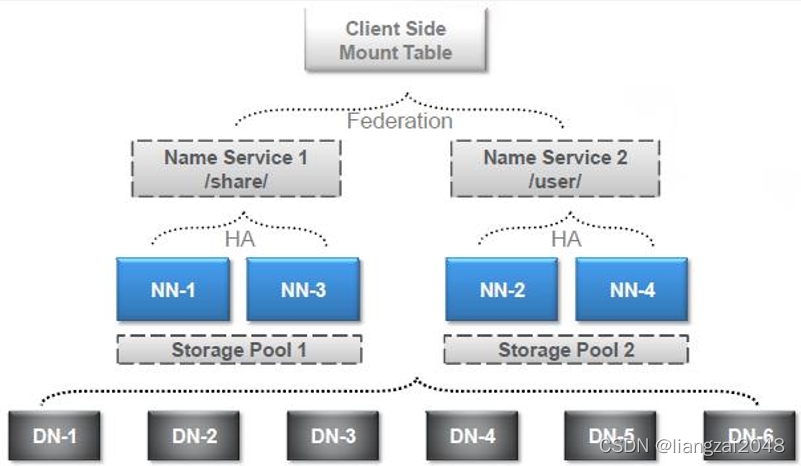
federation架构图-2

搭建HDFS HA 高可用
节点zkNNDNRMNMJNZKFCmaster11111node11111111node21111
1、关闭防火墙
service firewalld stop
2、时间同步
#查看3台系统时间是否一致
date
#时间同步
yum install ntp
ntpdate -u s2c.time.edu.cn
#或者
date -s 20180503
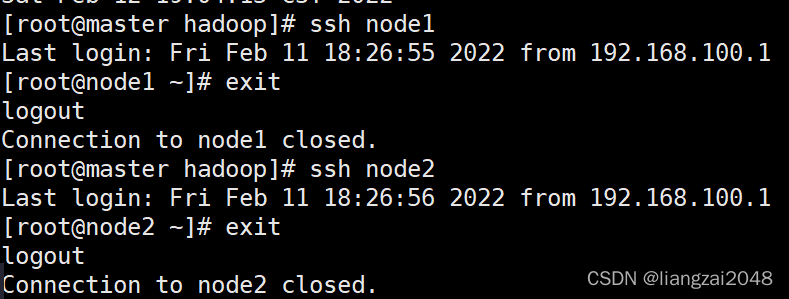
3、免密(远程执行命令)
#查看密钥是否已经配置
##查看.ssh目录下是否有私钥 id_rsa 和公钥 id_rsa.pub
cd~
cd .ssh/
ls
##使用ssh命令看是否可以免密远程登录
###master节点
ssh node1
ssh node2
### node1节点
ssh master
ssh node2
#### 退出
exit
#在两个主节点生成密钥文件
#master-->master,node1,node2
#node1-->master,node1,node2
ssh-keygen -t rsa
ssh-copy-id ip
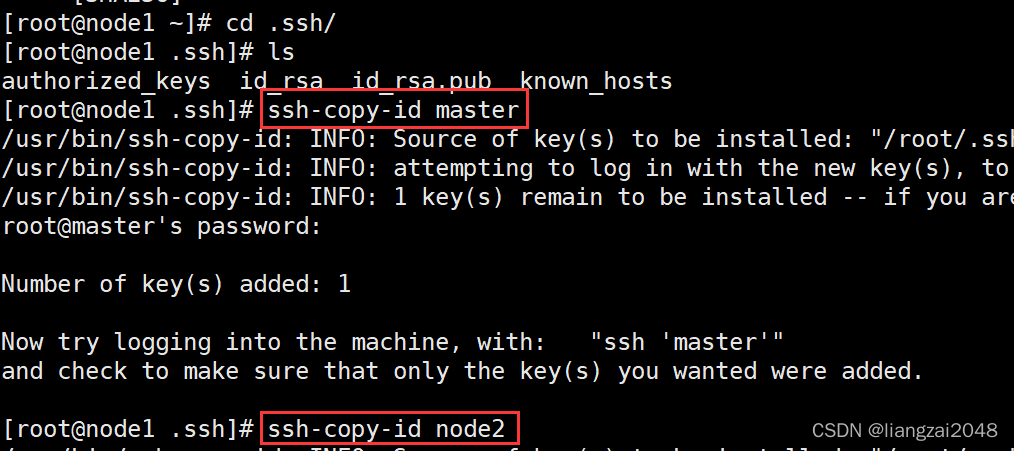
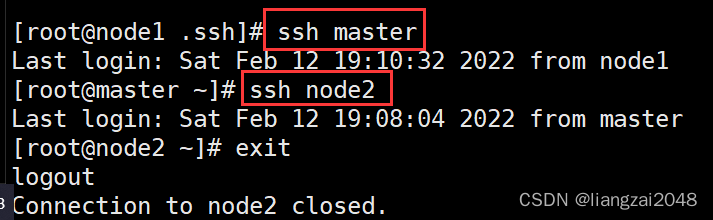
- 查看密钥是否已经配置

可见node1节点没有配置免密

- node2配置免密成功
4、修改Hadoop配置文件
# 先在master节点上将hdfs进程停掉
stop-dfs.sh
#切换到hadoop目录
cd /usr/local/soft/hadoop-2.7.6/etc/hadoop/
#停止HDFS集群
stop-dfs.sh
#修改配置文件 vim 命令
core-site.xml
hdfs-site.xml
#保存退出
esc
:wq
#同步到其它节点
#切换到hadoop目录
cd /usr/local/soft/hadoop-2.7.6/etc/hadoop/
scp ./* node1:`pwd`
scp ./* node2:`pwd`
- 在master节点上将hdfs进程停掉
- 修改core-site.xml配置文件
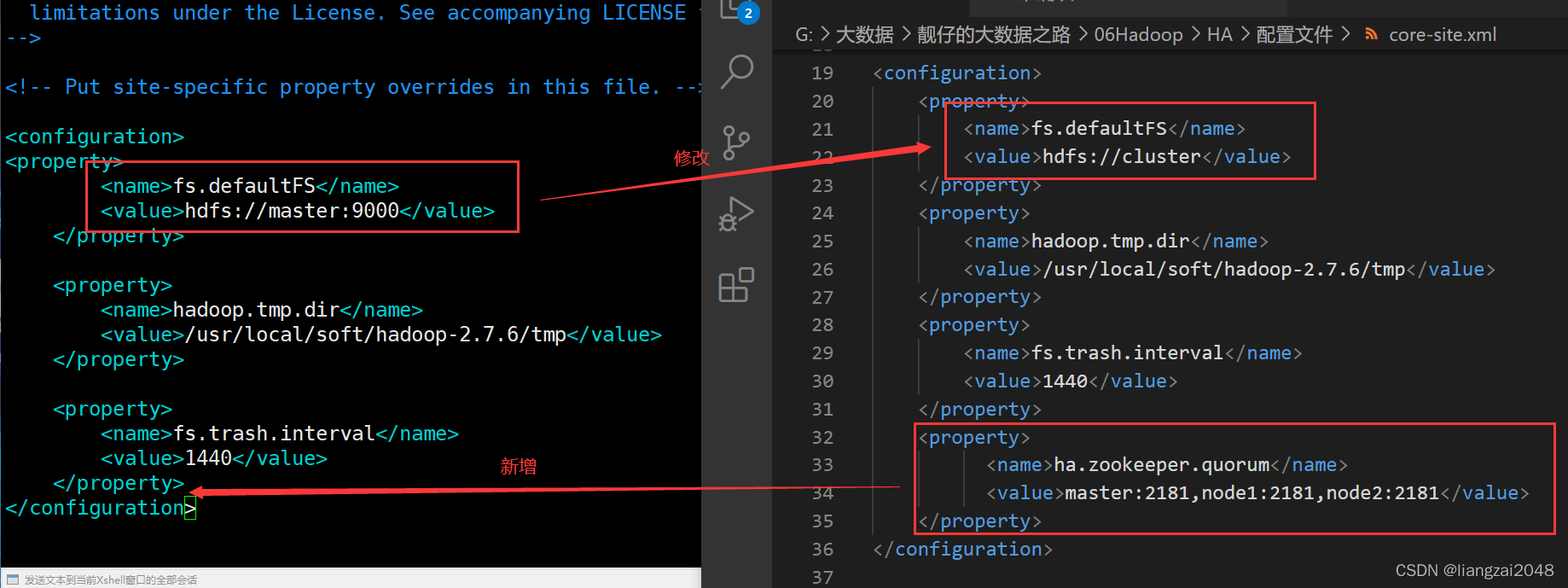
复制粘贴替换掉即可
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration><property><name>fs.defaultFS</name><value>hdfs://cluster</value></property><property><name>hadoop.tmp.dir</name><value>/usr/local/soft/hadoop-2.7.6/tmp</value></property><property><name>fs.trash.interval</name><value>1440</value></property><property><name>ha.zookeeper.quorum</name><value>master:2181,node1:2181,node2:2181</value></property></configuration>
- 修改hdfs-site.xml配置文件
复制粘贴替换掉即可
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration><!-- 指定hdfs元数据存储的路径 --><property><name>dfs.namenode.name.dir</name><value>/usr/local/soft/hadoop-2.7.6/data/namenode</value></property><!-- 指定hdfs数据存储的路径 --><property><name>dfs.datanode.data.dir</name><value>/usr/local/soft/hadoop-2.7.6/data/datanode</value></property><!-- 数据备份的个数 --><property><name>dfs.replication</name><value>1</value></property><!-- 关闭权限验证 --><property><name>dfs.permissions.enabled</name><value>false</value></property><!-- 开启WebHDFS功能(基于REST的接口服务) --><property><name>dfs.webhdfs.enabled</name><value>true</value></property><!-- //以下为HDFS HA的配置// --><!-- 指定hdfs的nameservices名称为mycluster --><property><name>dfs.nameservices</name><value>cluster</value></property><!-- 指定cluster的两个namenode的名称分别为nn1,nn2 --><property><name>dfs.ha.namenodes.cluster</name><value>nn1,nn2</value></property><!-- 配置nn1,nn2的rpc通信端口 --><property><name>dfs.namenode.rpc-address.cluster.nn1</name><value>master:8020</value></property><property><name>dfs.namenode.rpc-address.cluster.nn2</name><value>node1:8020</value></property><!-- 配置nn1,nn2的http通信端口 --><property><name>dfs.namenode.http-address.cluster.nn1</name><value>master:50070</value></property><property><name>dfs.namenode.http-address.cluster.nn2</name><value>node1:50070</value></property><!-- 指定namenode元数据存储在journalnode中的路径 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://master:8485;node1:8485;node2:8485/cluster</value></property><!-- 指定journalnode日志文件存储的路径 --><property><name>dfs.journalnode.edits.dir</name><value>/usr/local/soft/hadoop-2.7.6/data/journal</value></property><!-- 指定HDFS客户端连接active namenode的java类 --><property><name>dfs.client.failover.proxy.provider.cluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- 配置隔离机制为ssh --><property><name>dfs.ha.fencing.methods</name><value>
sshfence
shell(/bin/true)
</value></property><!-- 指定秘钥的位置 --><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><!-- 开启自动故障转移 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property></configuration>
5、启动zookeeper 三台都需要启动
- 利用XShell撰写窗口发送到全部回话

zkServer.sh start
zkServer.sh status
6、删除Hadoop数据存储目录下的文件 每个节点都需要删除
rm -rf /usr/local/soft/hadoop-2.7.6/tmp
7、启动JN 存储hdfs元数据
JournalNode负责同步NameNode元数据
#三台JN上执行 启动命令
/usr/local/soft/hadoop-2.7.6/sbin/hadoop-daemon.sh start journalnode
#jps查看三台JournalNode是否启动
jps

8、格式化 在一台NN上执行,这里选择master
警告!这里使用格式化命令如果失败,恢复快照重写搭建一定是配置文件上出了问题!
只能格式化一次,不能格式化第二次
#格式化
hdfs namenode -format
#启动当前的NN
hadoop-daemon.sh start namenode
- 格式化成功会在data目录下生成一个namenode/current目录
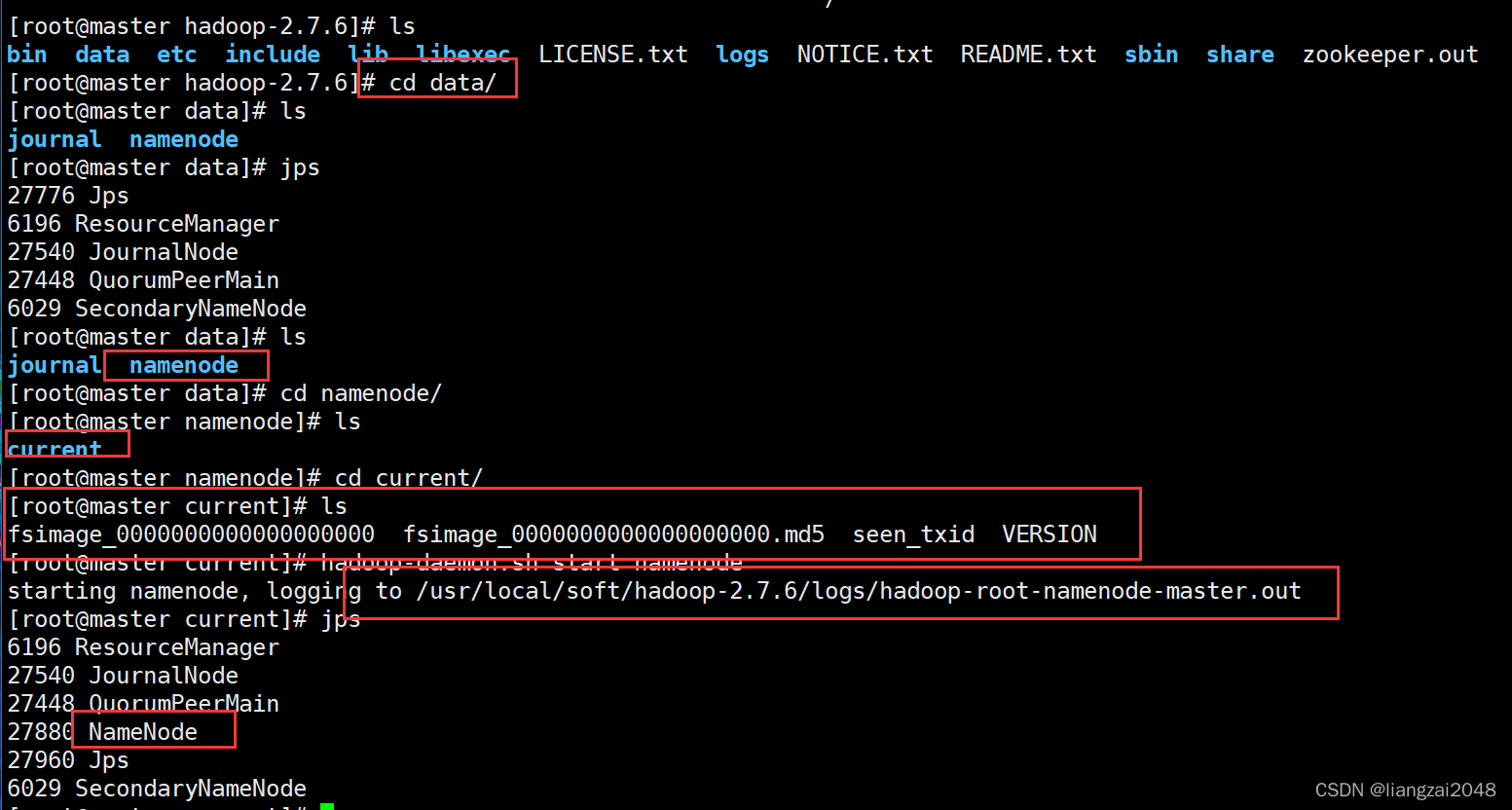
9、执行同步 没有格式化的NN上执行 在另外一个namenode上面执行 这里选择node1
/usr/local/soft/hadoop-2.7.6/bin/hdfs namenode -bootstrapStandby
10、格式化ZK 在master上面执行
!!一定要先 把zk集群正常 启动起来
/usr/local/soft/hadoop-2.7.6/bin/hdfs zkfc -formatZK
#启动node1的zk服务
zkCli.sh -server node1:2181
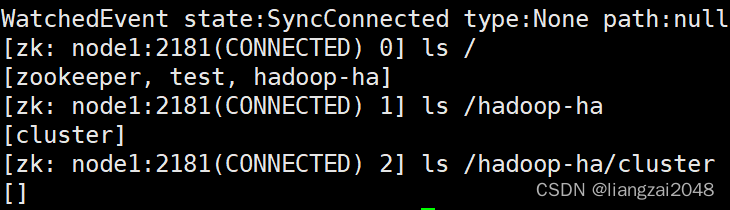
ls /
ls /hadoop-ha/cluster
这里多了一个hadoop-ha/cluster目录
11、启动hdfs集群,在master上执行
start-dfs.sh
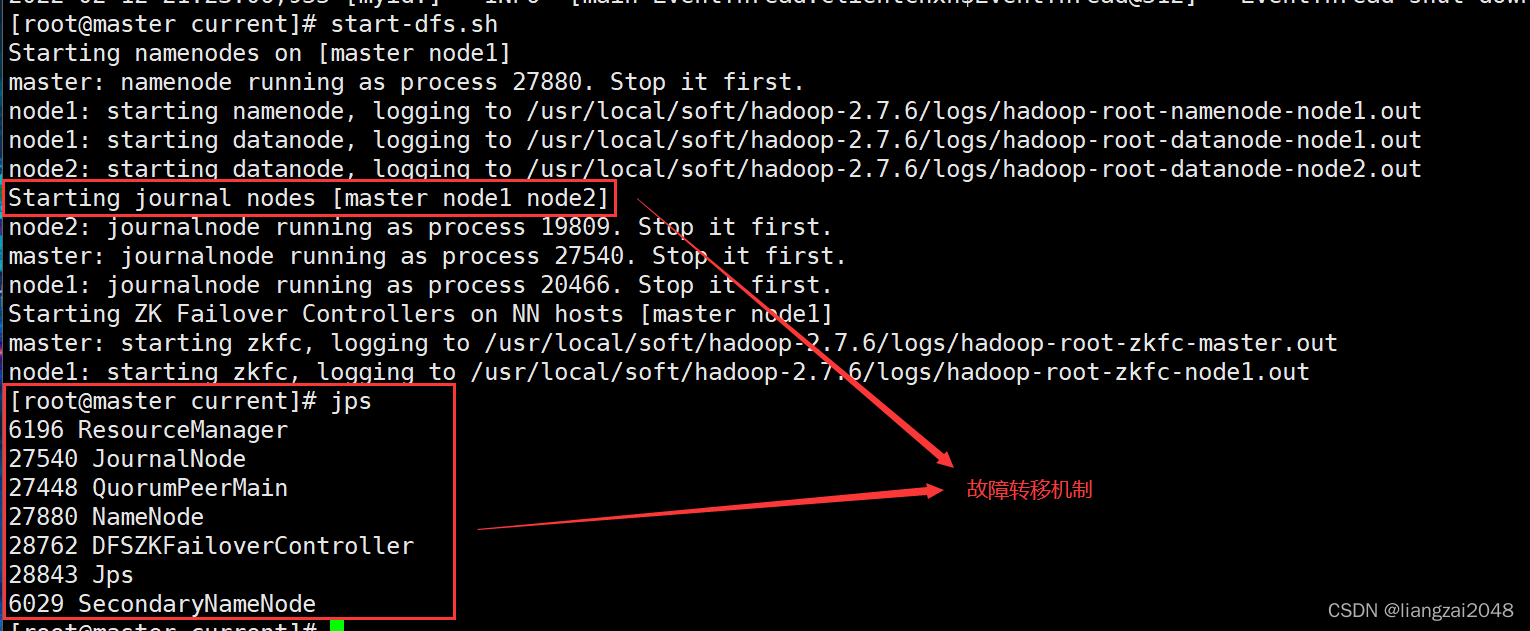
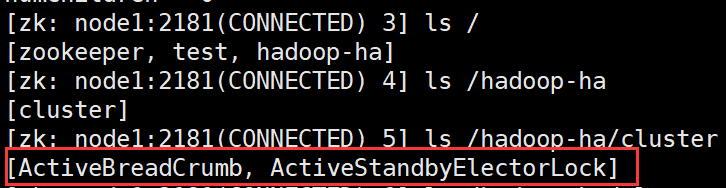
这个时候再启动node1的ZK
#启动node1的zk服务
zkCli.sh -server node1:2181
12、在IDEA中安装zookeeper插件
File->Settings->Plugins->搜索zookeeper
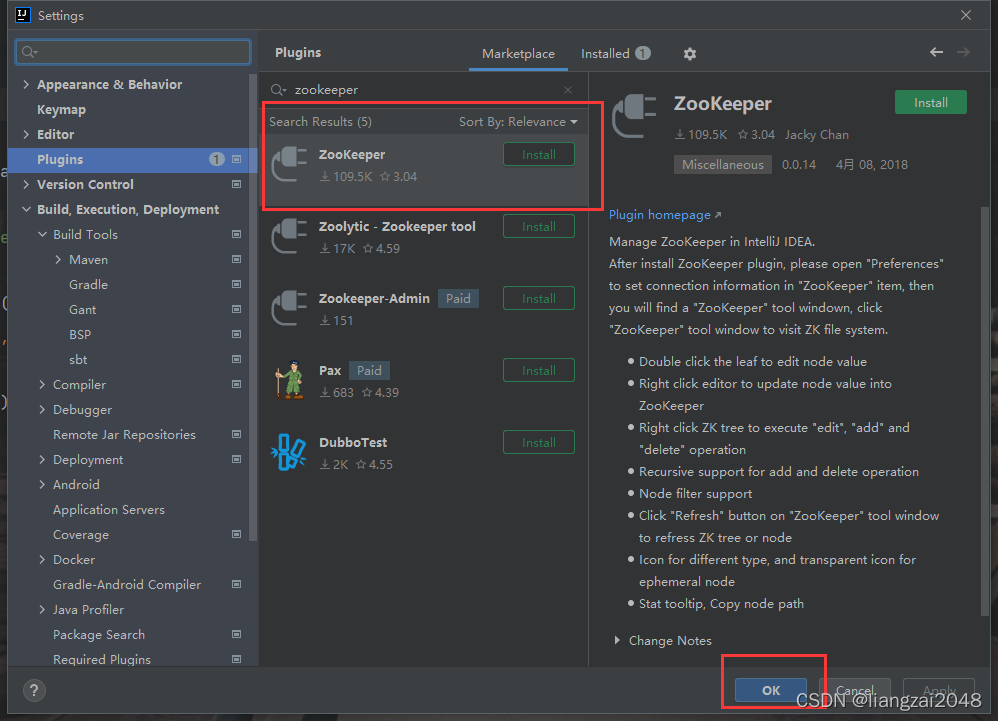
- 重启IDEA
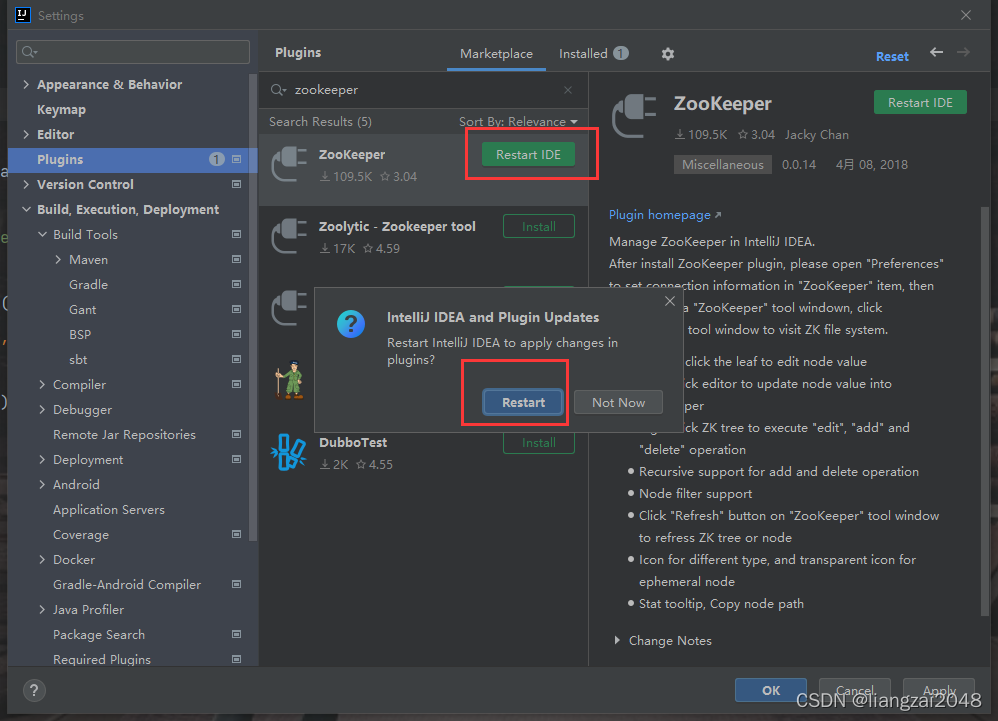
- 开启集群
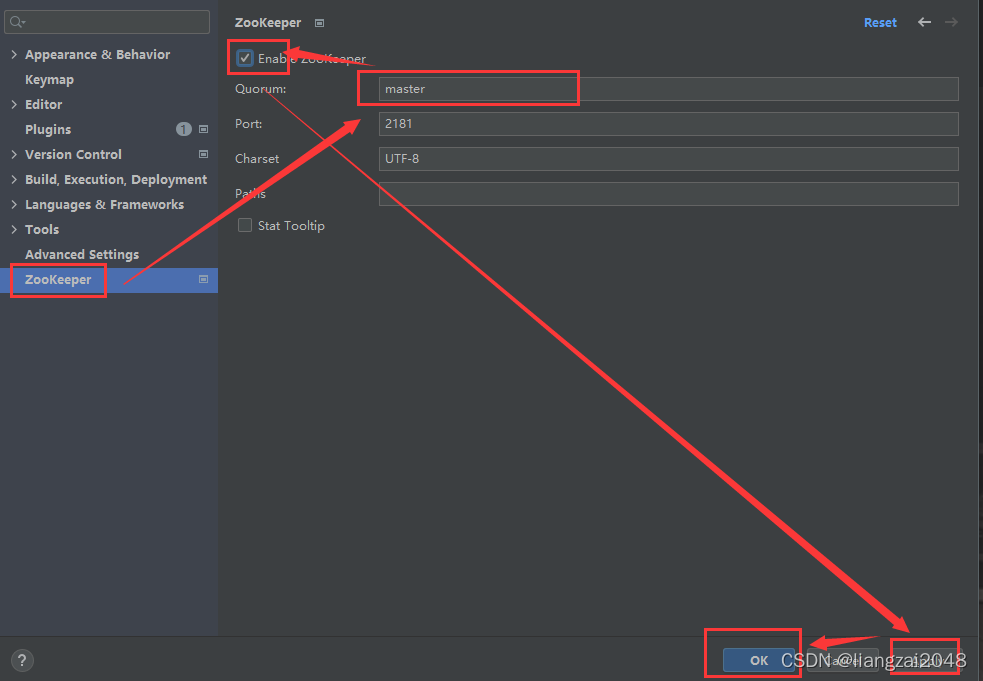
- 查看
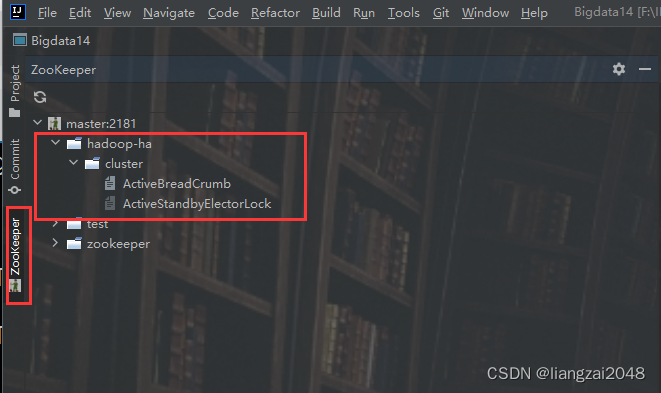
13、master、node1 访问web ui 50070端口
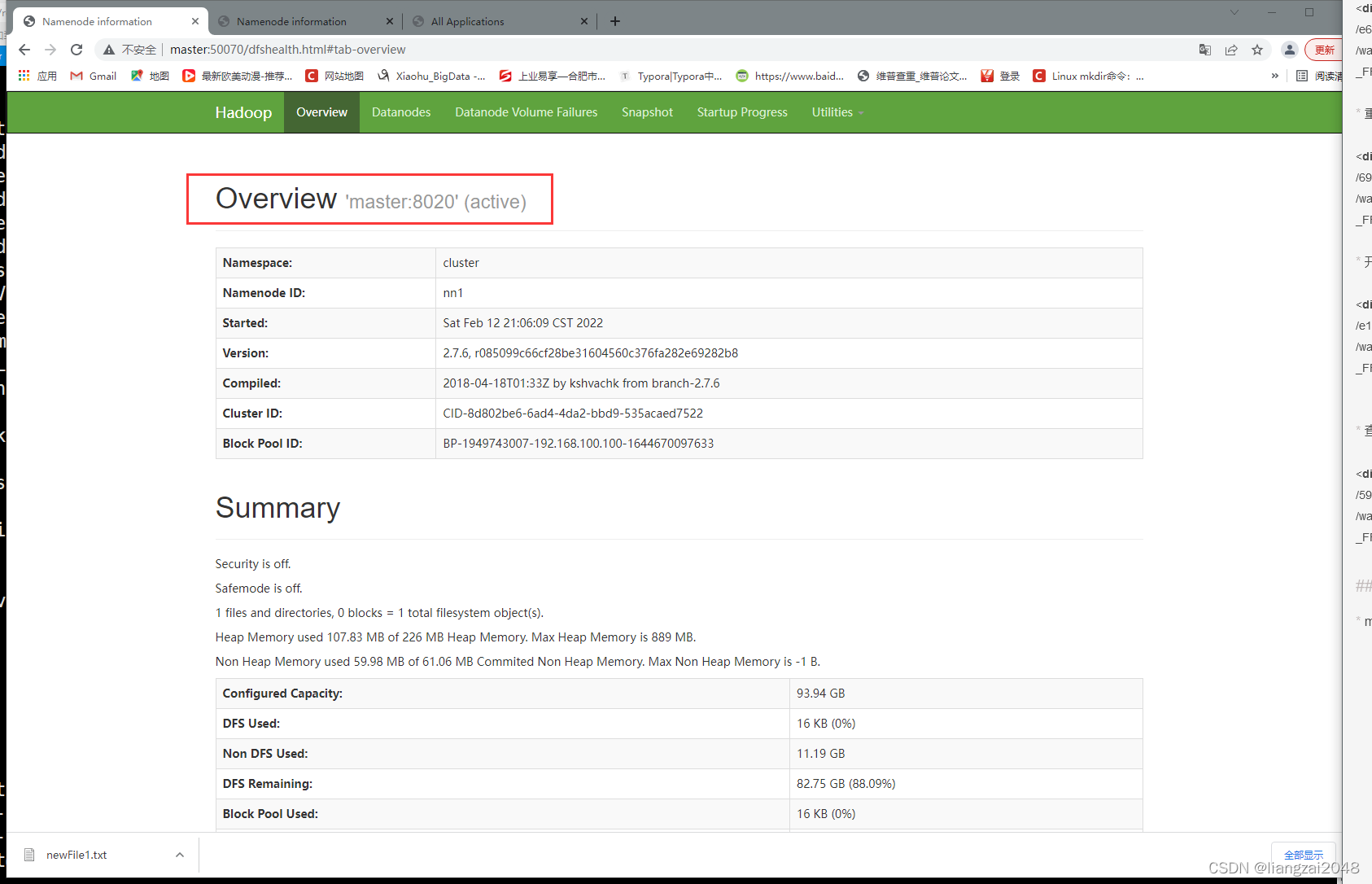
- master:50070
active状态
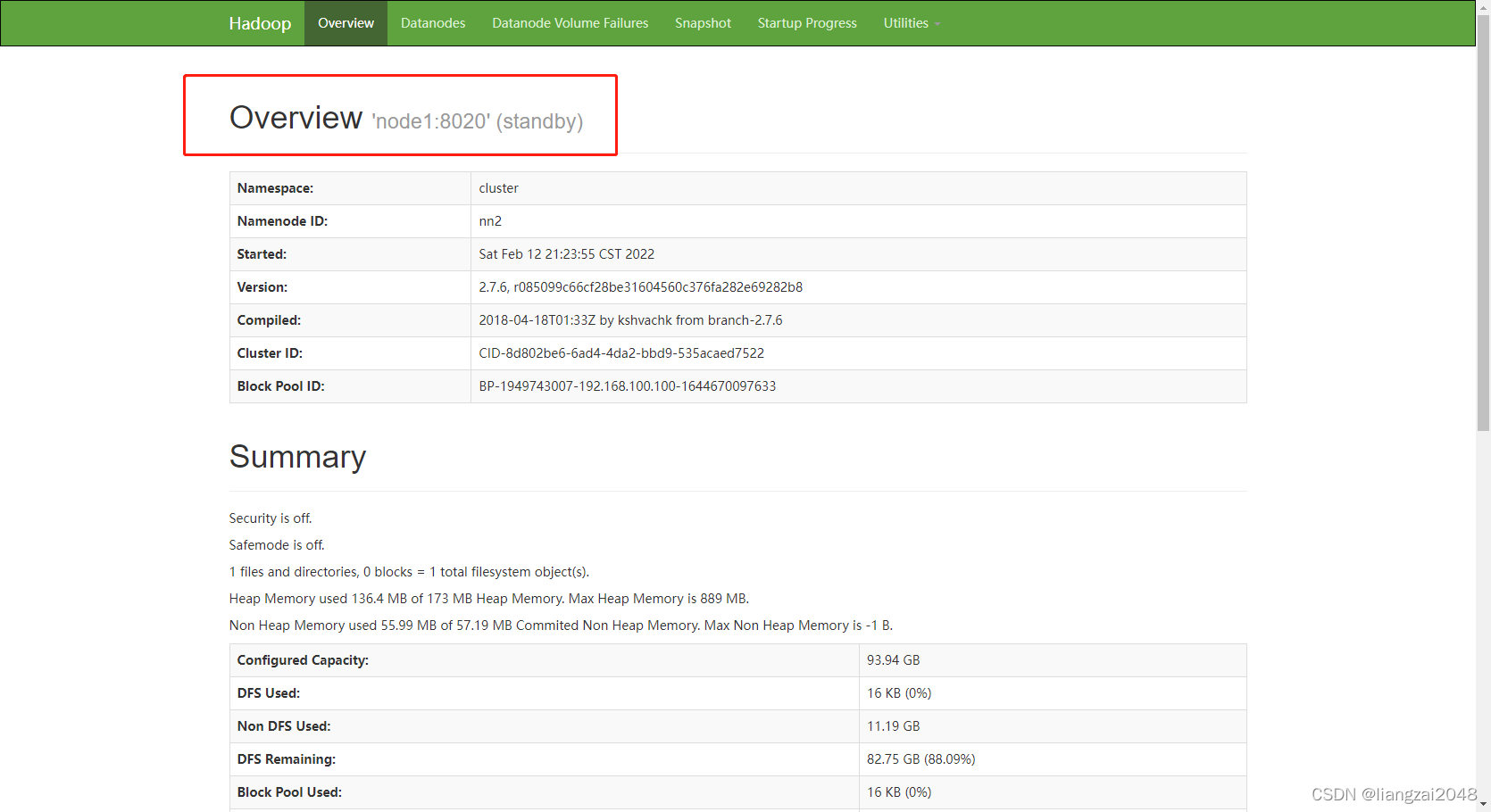
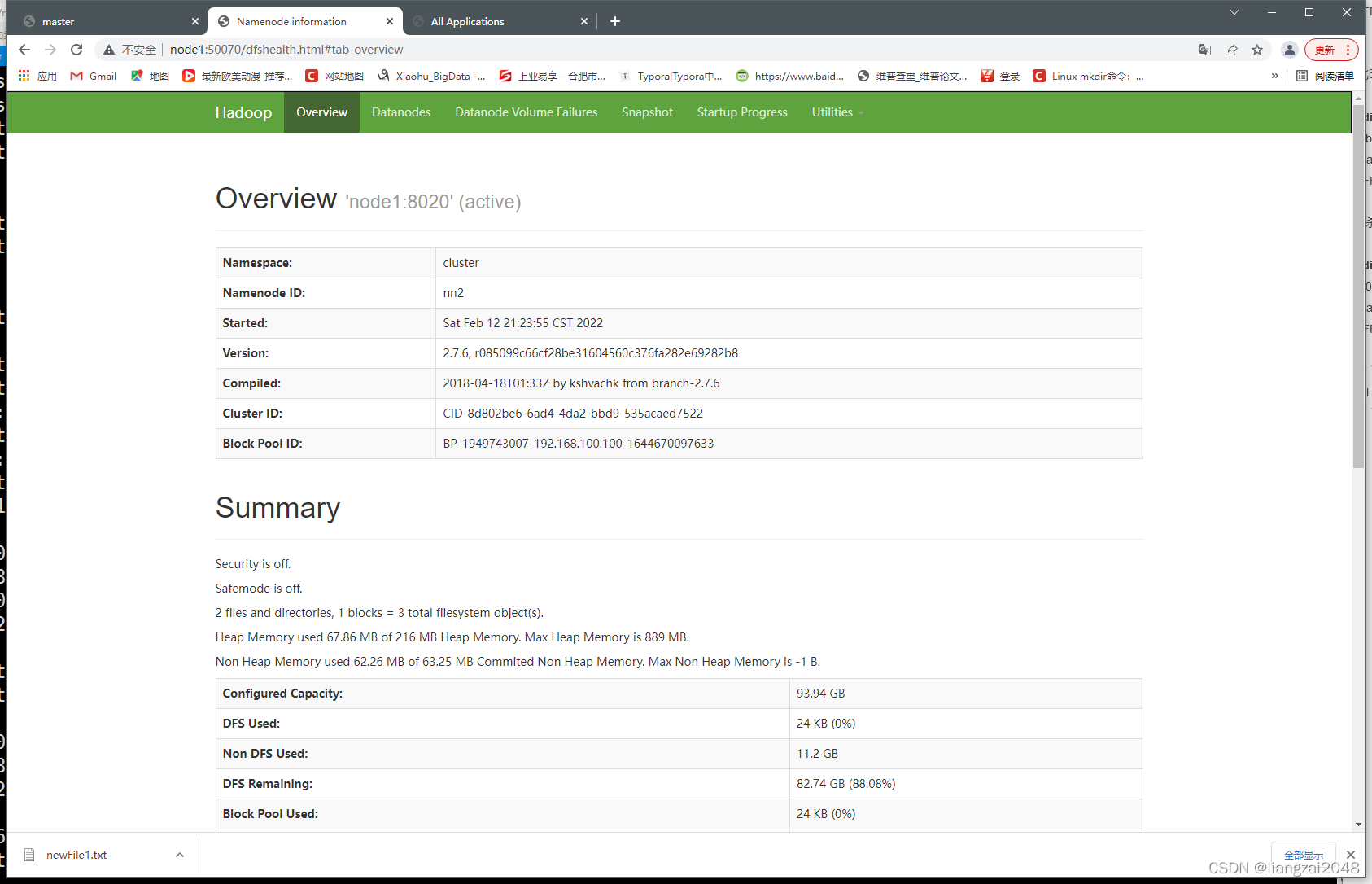
- node1:50070
standby状态
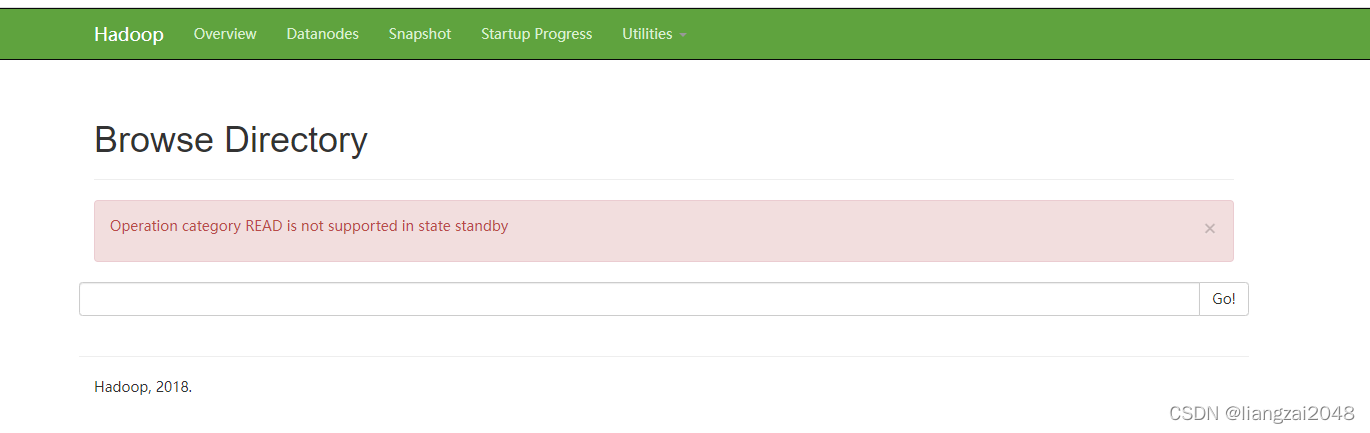
此时node1里没有文件
- 杀死master的NameNode进程
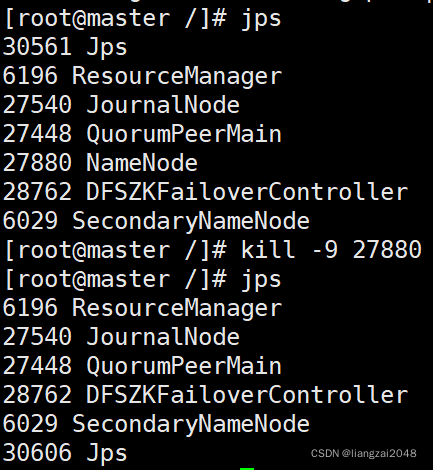
kill -9 27880
- 此时node1就变成了active状态了 (高可用)
到底啦!觉得靓仔的文章对你学习Hadoop有所帮助的话,一波三连吧!q(≧▽≦q)
本文转载自: https://blog.csdn.net/hujieliang123/article/details/122900442
版权归原作者 liangzai2048 所有, 如有侵权,请联系我们删除。
版权归原作者 liangzai2048 所有, 如有侵权,请联系我们删除。