
基本 概念
- RDD:(官方概念)弹性分布式数据集,就是一个个的在内存里的数据。就是数据的基本单位,所有spark都是来操作他的
- DAG 是有向无环图,它的作用主要是反应rdd之间的关系。
- Excutor 就是一个容器,就像Hadoop的node一样,用来运行的
- 应用 顾名思义来编写spark程序的
- 任务 运行的excutor单元
架构设计
如图
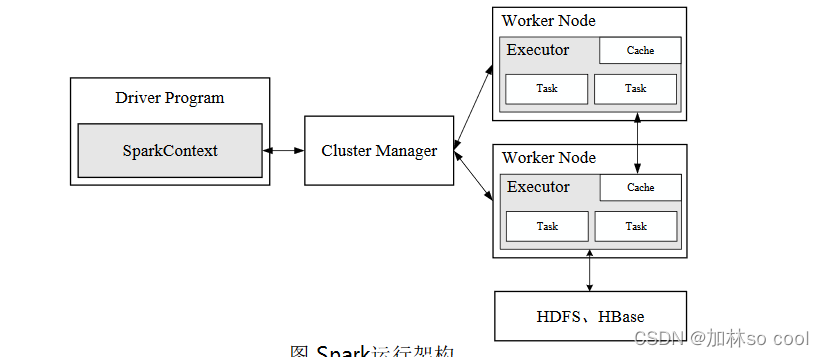
整个图一目了然,spark的架构,关于hdfs和hebase是一种可以读取的源数据类型,除此之外还有很多类型也会被这个读取比如Kafka,或者套接字流,当然这些数据源大概率都会在sparkstreaming里体现。
不止一次说过继续强调一遍,与Hadoop相比,spark读写基本上都是发生在内存里,所以更快。
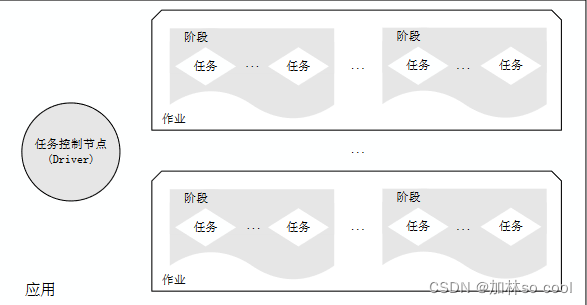
spark运行的基本流程
1.当一个spark被提交时,driver会先创造一个sparkcontext的对象,由它向资源管理器进行资源的申请,然后他就辉获得Excutor的资源,总而言之一个sparkcontext就像中场球员串联全场。
2.资源管理器--->excutor分配资源,excutor——>资源管理器运行的信息。
3.sparkcontext 根据rdd的依赖关系构建dag图,由dag图让所有资源得以利用。
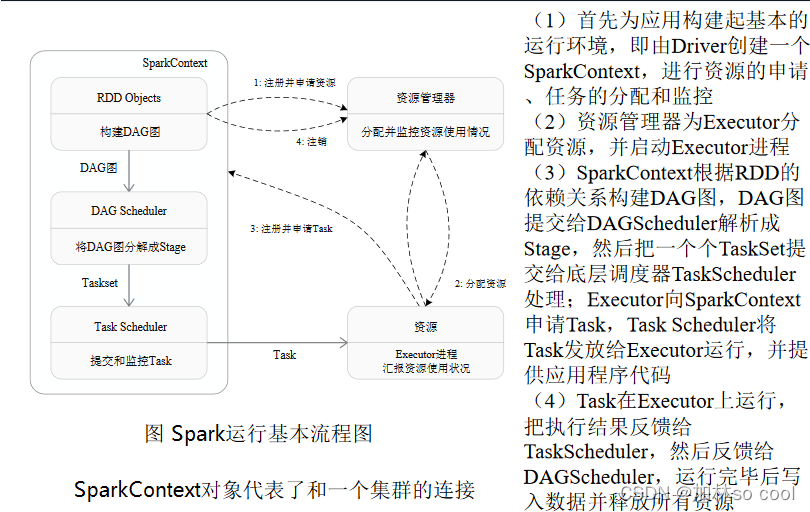
这个图摘自林子雨主编的spark
总而言之,spark框架有以下集中特点
1.每个应用都有自己专属的excutor,而且每个任务都是多线程而不是多进程从而节省很多资源,
2.还有一点我一直强调的就是spark的运行速度快是因为把东西都放在内存里了,此时就有一个BlockManager的模块类似于hdfs的模块从而实现的数据的读取.
3.计算向数据靠拢(具体在后面的文章讲
本文转载自: https://blog.csdn.net/qq_52310720/article/details/122885824
版权归原作者 加林so cool 所有, 如有侵权,请联系我们删除。
版权归原作者 加林so cool 所有, 如有侵权,请联系我们删除。