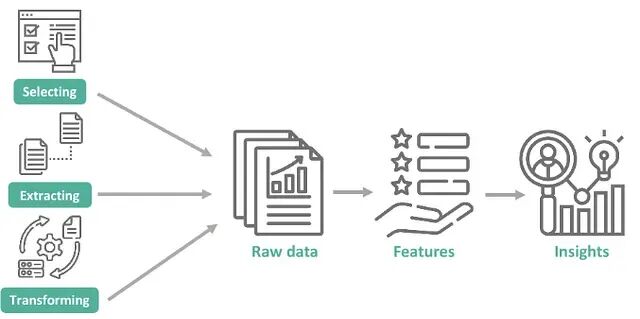
Feature Engineering 实战:Pandas + Scikit-learn的机器学习特征工程的完整代码示例
Feature engineering 是机器学习 pipeline 里最关键的一环。
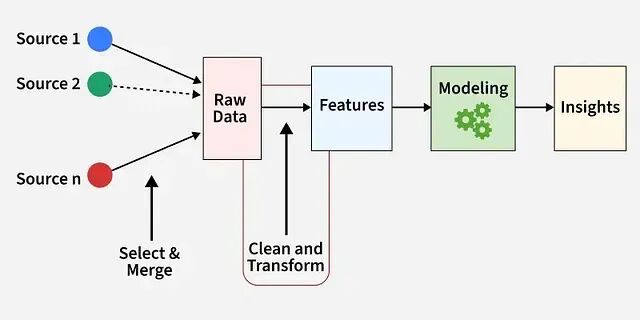
机器学习特征工程:缩放、编码、聚合、嵌入与自动化
好模型的秘诀不在于更花哨的算法,而在于更好的特征。
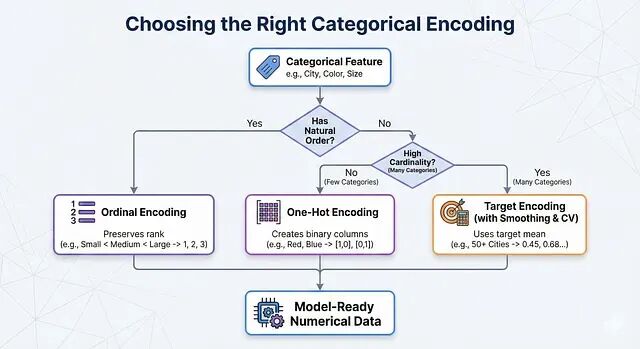
机器学习特征工程:分类变量的数值化处理方法
实际操作中可以这样判断:特征有天然顺序就用 Ordinal Encoding;没有顺序、类别数量也不多就用 One-Hot Encoding;类别太多就上 Target Encoding,记得配合 Smoothing 和交叉验证。
使用 tsfresh 和 AutoML 进行时间序列特征工程
本文将介绍多步时间序列预测的构建方式、auto-sklearn 如何扩展用于时间序列、tsfresh 的工作原理和使用方法

机器学习时间特征处理:循环编码(Cyclical Encoding)与其在预测模型中的应用
使用正弦和余弦进行循环编码,是一种优雅且低成本的修正手段。它保留了数据的邻近性,消除了人工伪影,能让模型学得更快、更准。
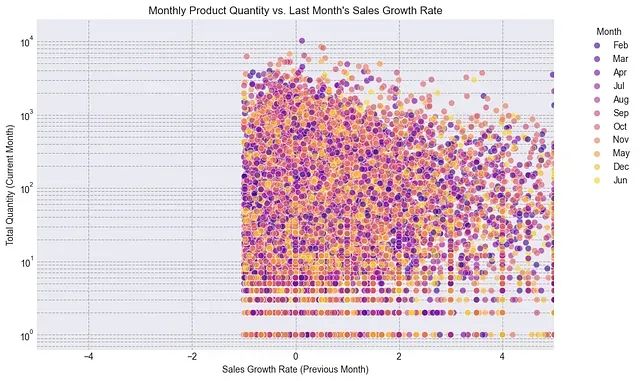
大数据集特征工程实践:将54万样本预测误差降低68%的技术路径与代码实现详解
本文通过实际案例演示特征工程在回归任务中的应用效果,重点分析包含数值型、分类型和时间序列特征的大规模表格数据集的处理方法。
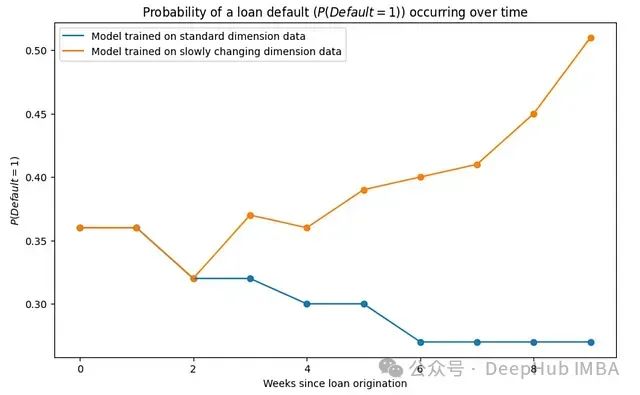
特征时序化建模:基于特征缓慢变化维度历史追踪的机器学习模型性能优化方法
本文将通过缓慢变化维度(Slowly Changing Dimensions)这一数据建模技术来解决上面的这个问题。通过本文的介绍,可以了解历史数据存储对模型性能的重要影响,以及如何在实际应用中实施这一技术方案。
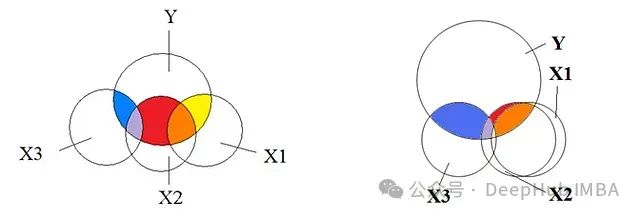
深入理解多重共线性:基本原理、影响、检验与修正策略
本文将深入探讨多重共线性的本质,阐述其重要性,并提供有效处理多重共线性的方法,同时避免数据科学家常犯的陷阱。

特征工程在营销组合建模中的应用:基于因果推断的机器学习方法优化渠道效应估计
因果推断方法为特征工程提供了一个更深层次的框架,使我们能够区分真正的因果关系和简单的统计相关性。

数据准备指南:10种基础特征工程方法的实战教程
特征工程是将原始数据转化为更具信息量的特征的过程。本文将详细介绍十种基础特征工程技术,包括其基本原理和实现示例。

8种数值变量的特征工程技术:利用Sklearn、Numpy和Python将数值转化为预测模型的有效特征
特征工程通常涉及对现有数据应用转换,以生成或修改数据,这些转换后的数据在机器学习和数据科学的语境下用于训练模型,从而提高模型性能。
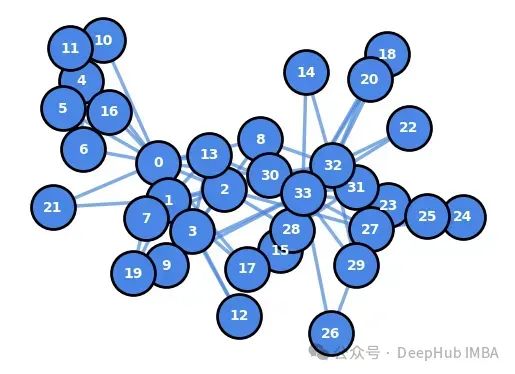
图特征工程实践指南:从节点中心性到全局拓扑的多尺度特征提取
本文将介绍如何利用NetworkX在不同层面(节点、边和整体图)提取重要的图特征。

时间序列特征提取:从理论到Python代码实践
**时间序列**是一种特殊的存在。这意味着你对表格数据或图像进行的许多转换/操作/处理技术对于时间序列来说可能根本不起作用。

特征工程与数据预处理全解析:基础技术和代码示例
我们将深入研究处理异常值、缺失值、编码、特征缩放和特征提取的各种技术。

时间序列预测:探索性数据分析和特征工程的实用指南
我在本文中我们将EDA总结为六个步骤:描述性统计、时间图、季节图、箱形图、时间序列分解、滞后分析。
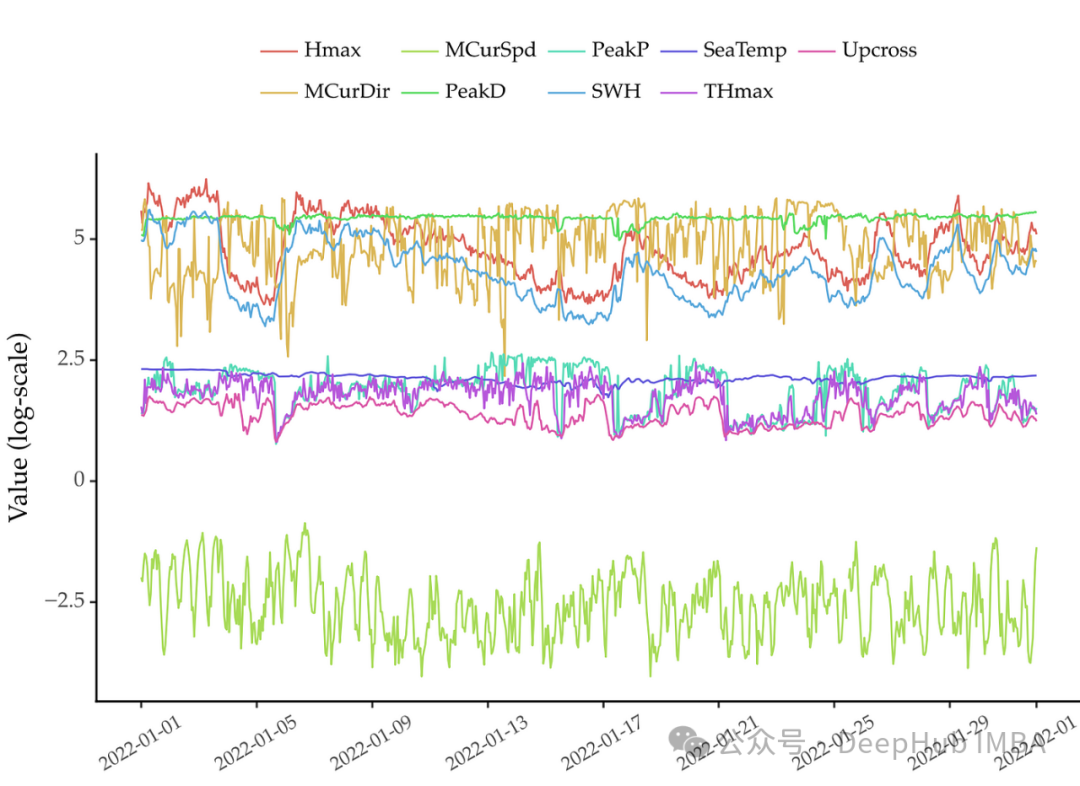
掌握时间序列特征工程:常用特征总结与 Feature-engine 的应用
本文将通过使用feature-engine来简化这些特征的提取
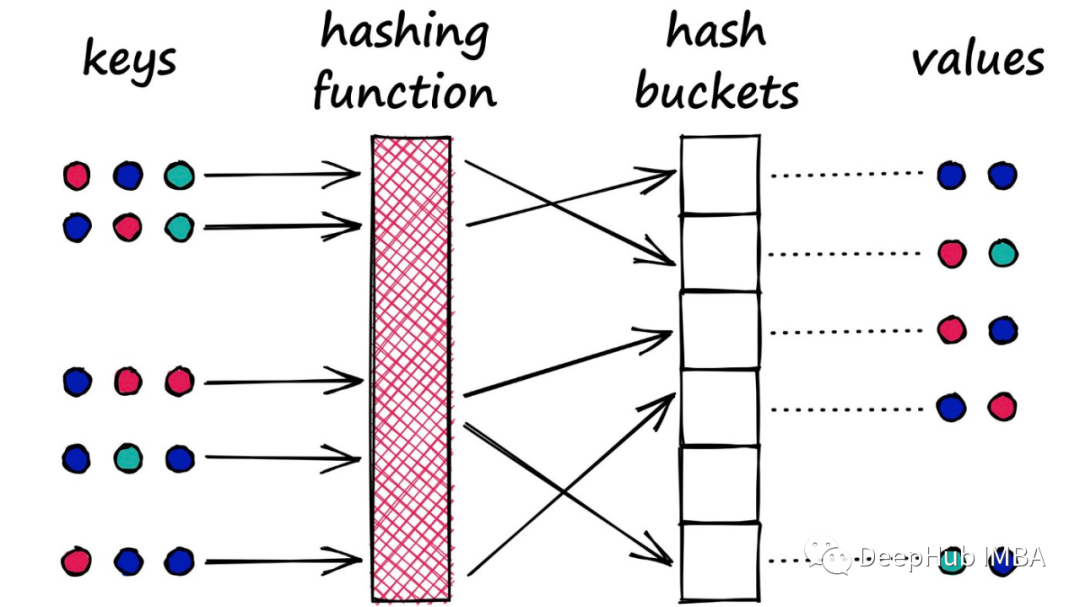
使用LSH 进行特征提取
局部敏感哈希(LSH)通常用于近似最近邻算法(ANN) 操作(向量搜索)。LSH的特性也可以在以矢量为输入的神经网络模型中得到利用(例如,各种的音频、视频和文本嵌入等内容信号)。
Python-sklearn之PCA主成分分析
文章目录写在前面一、PCA主成分分析1、主成分分析步骤2、主成分分析的主要作二、Python使用PCA主成分分析写在前面作为大数据开发人员,我们经常会收到一些数据分析工程师给我们的指标,我们基于这些指标进行数据提取。其中数据分析工程师最主要的一个特征提取方式就是PCA主成分分析,下面我将介绍Pyth
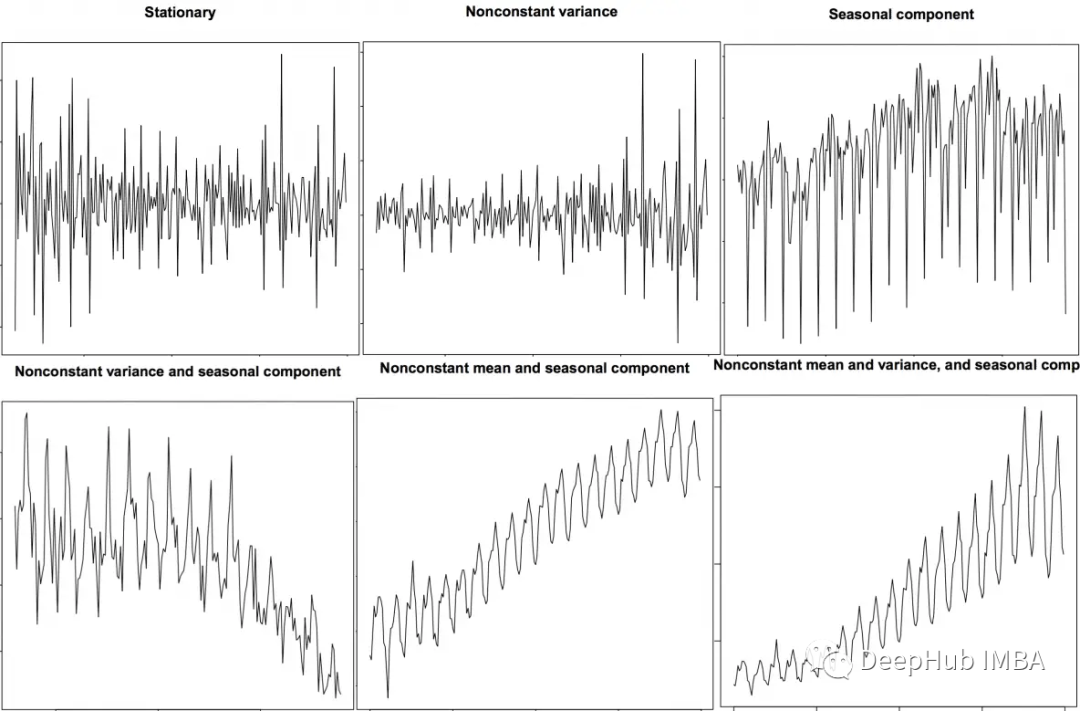
时间序列特征提取的Python和Pandas代码示例
使用Pandas和Python从时间序列数据中提取有意义的特征,包括移动平均,自相关和傅里叶变换。

使用手工特征提升模型性能
本文将使用信用违约数据集介绍手工特征的概念和创建过程。
- 1
- 2



