
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的自动驾驶汽车无人驾驶目标检测算法系统
设计思路
一、课题背景与意义
自动驾驶计算平台的资源有限,需要在有限的计算资源下同时处理多种传感和计算任务。为了应对道路背景复杂和小目标信息缺失的问题,提出了一种改进的目标检测网络。该网络具有较小的内存占用率和计算资源占用率,适应自动驾驶场景的需求。通过准确定位目标位置和提高小目标检测效果,为自动驾驶汽车提供更丰富的目标信息,提升目标检测的精度和鲁棒性。
二、算法理论原理
2.1 YOLOv5算法
在基于YOLOv5s的目标检测网络中,进行了两方面的改进:在颈部网络中添加了位置注意力模块,帮助网络感知道路目标在图像中的空间位置分布,从而增强了网络的特征提取能力;在主干网络中添加了小目标增强模块,丰富了检测网络对小目标的特征信息,提高了网络在小目标检测方面的精度。
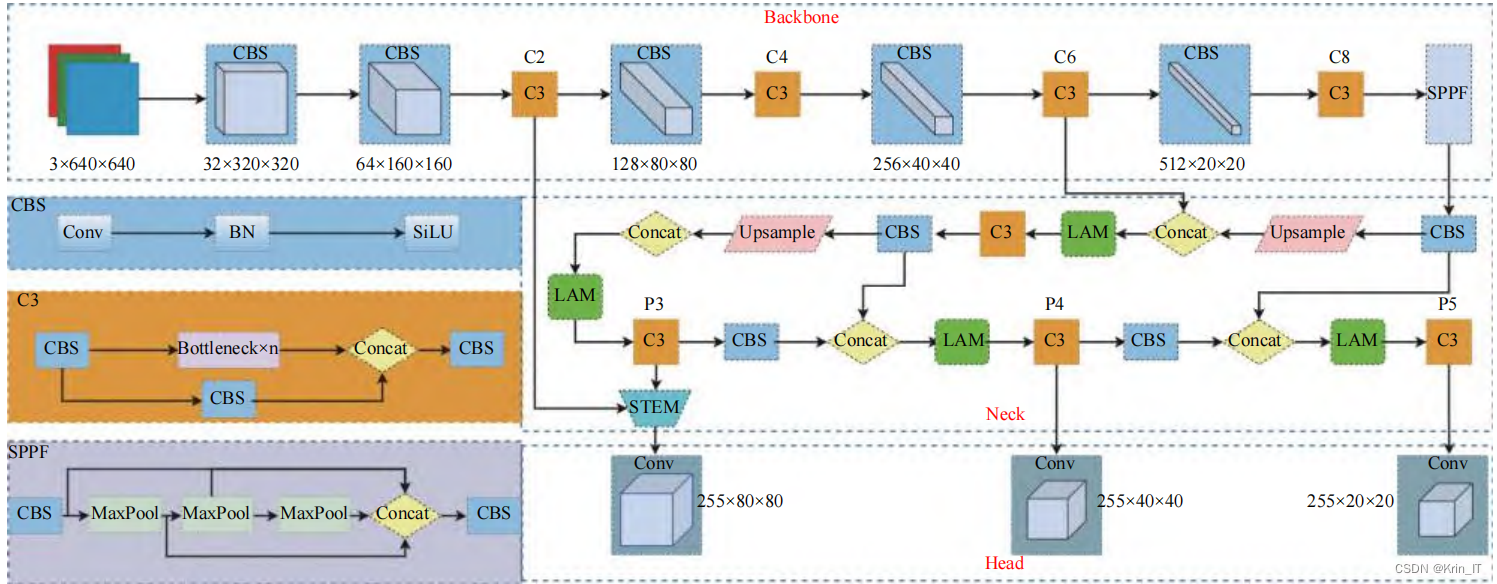
这些改进使得网络在目标检测任务中具有更好的性能。通过位置注意力模块,网络能够更准确地定位目标的位置,提高目标检测的准确性和鲁棒性。而小目标增强模块则有助于增强网络对于小目标的特征提取能力,提高小目标的检测效果。
在基于HANet的基础上设计了一种位置注意力模块,用于提取自动驾驶场景中的空间位置注意力特征,以增强网络对目标类别和位置分布的感知和定位能力。该模块通过特征压缩、全局平均池化和1×1卷积等步骤,对特征图进行处理,压缩冗余通道特征,从而计算出位置注意力特征图。为了捕获像素间的空间上下文相关性和通道间的语义相关性,同时提高计算效率,该模块同时使用通道注意力和空间注意力,并采用并联的方式提取注意力特征。
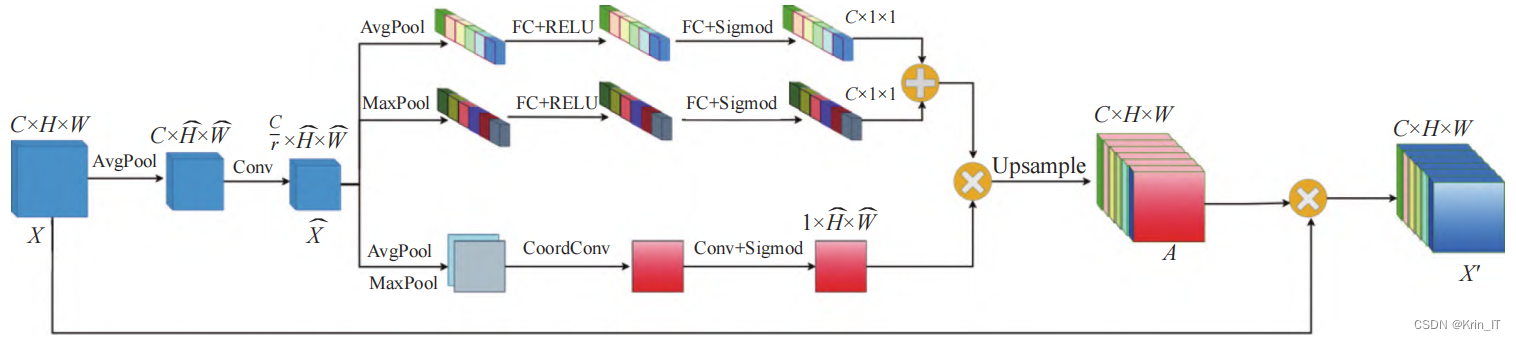
通过引入位置注意力模块,网络能够更准确地感知和定位自动驾驶场景中目标的位置分布,从而增强目标检测的能力。同时,该模块的设计考虑了计算效率,以减少计算时间成本。总之,该位置注意力模块在自动驾驶场景中能够提供更强的感知能力,并为目标检测任务带来明显的性能提升。
相关代码示例:
# 定义改进后的YOLOv5s网络
class ImprovedYOLOv5s(nn.Module):
def __init__(self, num_classes):
super(ImprovedYOLOv5s, self).__init__()
# 主干网络,包含多个卷积层和池化层
self.backbone = nn.Sequential(
# ...
)
# 位置注意力模块
self.position_attention = PositionAttentionModule(in_channels=512)
# 小目标增强模块
self.small_object_enhancement = SmallObjectEnhancementModule(in_channels=256)
# 检测层,用于预测目标的类别和位置
self.detection = nn.Sequential(
# ...
)
def forward(self, x):
# 主干网络的前向传播
backbone_output = self.backbone(x)
# 位置注意力模块的前向传播
position_attention_output = self.position_attention(backbone_output)
# 小目标增强模块的前向传播
enhanced_feature = self.small_object_enhancement(backbone_output, position_attention_output)
# 检测层的前向传播
detection_output = self.detection(enhanced_feature)
return detection_output
2.2 小目标增强模块
为了提高小目标的检测精度,在非对称上下文调制模块的基础上进行改进,设计了一种小目标增强模块。该模块由自下而上的逐点通道上下文调制模块和自上而下的全局上下文调制模块构成。在小目标增强模块中,通过对浅层高分辨率特征和深层高级语义特征进行多尺度交换,获得包含小目标细节信息和语义信息的增强特征。自下而上的逐点通道上下文调制模块使用逐点通道注意力,将每个空间位置的通道特征上下文单独聚合。该模块利用浅层特征中丰富的小目标细节信息生成空间细节上下文调制权重,以补充深层特征中缺失的小目标细节信息。
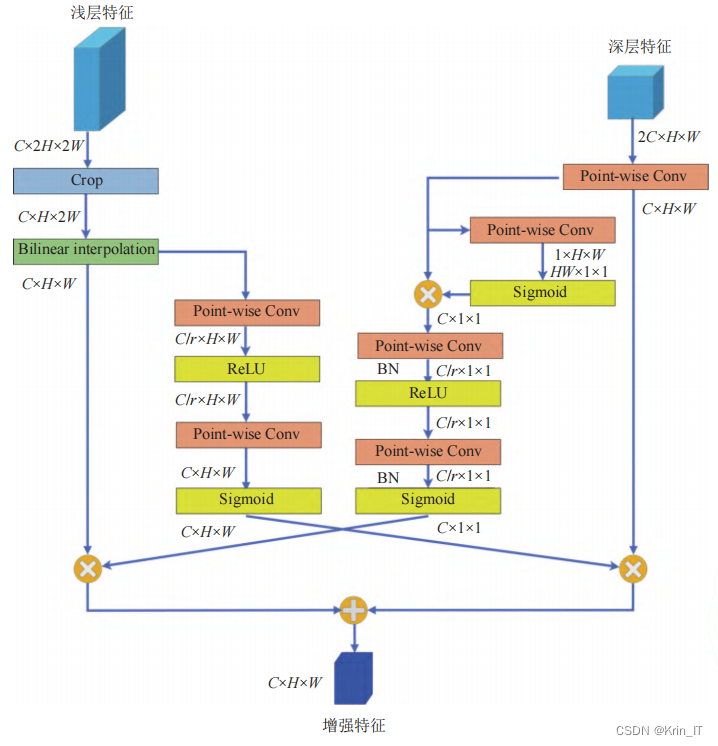
为了设计小目标增强模块,采取了以下步骤:
特征裁剪:首先,在浅层特征中选择高度比例为0.4-0.7、宽度比例为0.3-0.6的区域进行裁剪,以获取包含小目标的特征区域,并减少冗余特征和参数量。
尺度匹配:为了解决特征尺寸不匹配的问题,采用双线性插值算法生成与深层特征相同宽高的特征图,确保两者尺寸一致。
计算调制权重:通过两次逐点卷积和激活函数操作,计算调制权重。这些权重用于调制浅层特征,最终通过逐点相乘将调制后的高级特征得到。
自上而下的全局上下文调制模块利用全局上下文信息来指导浅层特征,将全局语义特征嵌入到浅层特征中,以减少浅层特征中的噪声干扰。
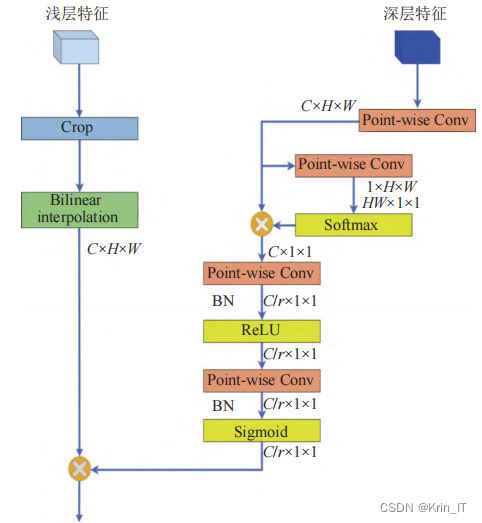
通过特征裁剪、尺度匹配和计算调制权重等操作,小目标增强模块能够有效地处理小目标,提取具有增强语义和细节信息的特征。自上而下的全局上下文调制模块则有助于减少浅层特征的噪声干扰,提高小目标检测的准确性。
相关代码:
# 定义位置注意力模块
class PositionAttentionModule(nn.Module):
def __init__(self, in_channels):
super(PositionAttentionModule, self).__init__()
# 注意力模块的网络结构,用于学习位置注意力权重
self.conv = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
attention = self.sigmoid(self.conv(x))
return x * attention
# 定义小目标增强模块
class SmallObjectEnhancementModule(nn.Module):
def __init__(self, in_channels):
super(SmallObjectEnhancementModule, self).__init__()
# 小目标增强模块的网络结构,用于融合浅层和深层特征
self.conv1 = nn.Conv2d(in_channels, in_channels, kernel_size=1)
self.conv2 = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1)
self.relu = nn.ReLU(inplace=True)
def forward(self, x1, x2):
x1 = self.conv1(x1)
x2 = self.conv2(x2)
enhanced_feature = self.relu(x1 + x2)
return enhanced_feature
三、检测的实现
3.1 数据集
由于网络上缺乏适用的自动驾驶目标检测数据集,我决定亲自采集数据并创建一个全新的数据集。我使用了自动驾驶车辆和相应的传感器设备,在各种真实驾驶场景下拍摄了大量图片和视频。这些数据包含了不同道路条件、天气状况和交通情况下的自动驾驶目标。在筛选了不均衡的类别后,我从原始数据集中选取了46500张图片用于训练。按照7:2:1的比例,将这些图片随机分配到训练集、验证集和测试集中。其中,训练集包含32550张图片,验证集包含9300张图片,测试集包含4650张图片。

为了重新分类道路目标,我将它们分为了六个类别,包括汽车、大车、人、两轮车、交通灯和交通标识。通过这样的重新分类,可以使数据集更加具有针对性,有助于训练模型更好地识别和检测这些道路目标。重新分类后的数据集提供了更准确、更全面的标注信息,能够为自动驾驶目标检测的研究和应用提供更有价值的资源。
3.2 实验环境搭建
在实验中,使用了NVIDIA GeForce RTX 3090显卡进行模型的训练和测试,并搭配Intel(R) Xeon(R) Platinum 8255C作为CPU。操作系统和软件环境方面,采用的是Ubuntu 22.04,Python版本为3.8.10。深度学习框架选择了PyTorch 1.10.2来实现模型的训练和推理。这些硬件和软件环境的配置提供了强大的计算和深度学习支持,有助于进行高效的模型训练和测试。

3.3 实验及结果分析
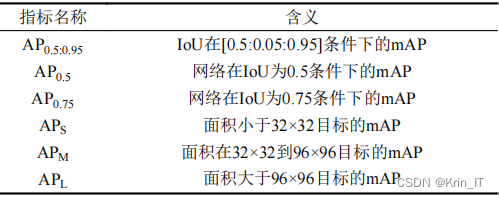
为了更好地观察网络对不同尺度目标的检测效果,使用 COCO 评价指标进行评价
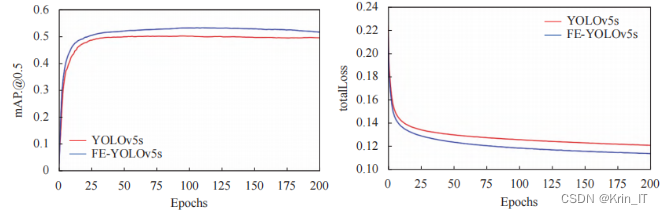
引入了位置注意力模块和小目标增强模块后,网络在检测道路目标的性能上取得了显著的提升。位置注意力模块使网络能够学习到道路目标的空间位置分布规律,增强了特征提取能力,从而提高了检测精度。小目标增强模块则结合了浅层小目标细节信息和深层语义信息,有效地提升了小目标的检测性能,而不影响对中大目标的检测。
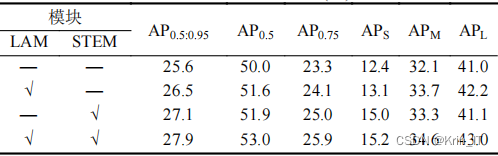
经过添加了LAM模块的改进后,网络对预测目标的注意力更加集中,显著减少了各类别对错误区域的特征响应。这表明LAM模块能够学习数据集中各类别的空间分布特征,并根据目标类别抑制错误空间区域的响应,帮助网络聚焦于关键区域,从而提高了网络的分类和定位准确度。

改进后的SE-YOLOv5s网络在道路目标检测方面表现更好。它能够检测出YOLOv5s漏检和错检的道路目标,并且在不同光照条件和复杂道路场景下具有更强的鲁棒性,能够准确地识别目标。在实际的道路目标检测任务中,它能够提供更准确、鲁棒的检测效果,对于实际应用具有重要的意义
相关代码如下:
# 加载预训练的Faster R-CNN模型
model = torch.hub.load('pytorch/vision:v0.10.0', 'faster_rcnn_resnet50_fpn', pretrained=True)
# 设置输入图像的预处理转换
preprocess = T.Compose([
T.Resize((800, 800)), # 调整图像大小为800x800(根据模型要求)
T.ToTensor() # 转换为Tensor
])
# 加载图像
image_path = 'path/to/image.jpg' # 图像文件路径
image = Image.open(image_path).convert('RGB')
# 对图像进行预处理
input_image = preprocess(image)
# 将图像输入模型进行目标检测
model.eval()
with torch.no_grad():
predictions = model([input_image])
# 可以根据需要进一步处理检测结果,如绘制检测框、筛选目标等
创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
最后
本文转载自: https://blog.csdn.net/weixin_55149953/article/details/135575690
版权归原作者 weixin_55149953 所有, 如有侵权,请联系我们删除。
版权归原作者 weixin_55149953 所有, 如有侵权,请联系我们删除。