深度学习常用的backbone有哪些
深度学习中常用的backbone有resnet系列(resnet的各种变体)、NAS网络系列(RegNet)、Mobilenet系列、Darknet系列、HRNet系列、Transformer系列和ConvNet。
Prompt Learning详解
现阶段NLP最火的两个idea 一个是对比学习(contrastive learning) 另一个就是 promptprompt 说简单也很简单 看了几篇论文之后发现其实就是构建一个语言模板 但是仔细想想又觉得复杂 总感觉里面还有很多细节 因此我想从头到尾梳理一下prompt 很多地方会把它翻译成[
超分之EDSR
这篇文章是SRResnet的升级版——EDSR,其对网络结构进行了优化(去除了BN层),省下来的空间可以用于提升模型的size来增强表现力。此外,作者提出了一种基于EDSR且适用于多缩放尺度的超分结构——MDSR。EDSR在2017年赢得了NTIRE2017超分辨率挑战赛的冠军。参考目录:①深度学习
准确率、精确率、召回率、F1-score
追求召回率高,则通常会影响精确率。F1值为算数平均数除以几何平均数,且越大越好,将Precision和Recall的上述公式带入会发现,当F1值小时,True Positive相对增加,而false相对减少,即Precision和Recall都相对增加,即F1对Precision和Recall都进行
笔记--Ubuntu20.04安装Nvidia驱动、CUDA Toolkit和CUDA CuDNN
注:选择合适的版本进行安装,确保 CUDA Toolkit 的版本低于 Nvidia 驱动的版本!时,表明 pytorch 安装成功,pytorch 可以使用 Cuda 进行加速,Nvidia驱动、CUDA Toolkit 和 CUDA CuDNN 等均安装成功!末尾添加以下两条路径:(由于博主安装
ChatGPT国内怎么使用-ChatGPT是什么
尽管 GPT-3 的源代码尚未发布,但StackExchange网站上的一篇帖子表明 GPT-3 是用“与 GPT-2 相同的模型和架构”编写的。它以书籍、文章和网站的文本形式在有偏见和无偏见的数据上进行了良好的训练。一旦它对语言有了足够的了解,它就可以根据给定的提示或主题生成自己的文本。对于从事各
基于深度神经网络的中药材识别
近年来,受到我国国民经济发展与社会财富积累增速加快的影响,人们对自己的身体健康也越来越重视,很多的人都选择在服用中草药来治疗疾病、改善体质,因此,我国的中药材行业在这一段时间内也迎来了蓬勃的发展。人们对中医健康养生越来越重视,而中药材是中医健康养生体系的重要组成部分。中药材种类纷繁复杂,普通人对中药
编码器-解码器架构
编码器-解码器架构
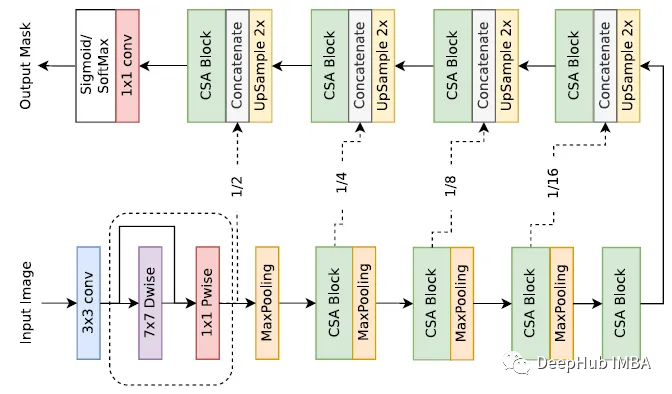
论文推荐:DCSAU-Net,更深更紧凑注意力U-Net
这是一篇23年发布的新论文,论文提出了一种更深、更紧凑的分裂注意力的U-Net,该网络基于主特征守恒和紧凑分裂注意力模块,有效地利用了底层和高层语义信息。
1DCNN原理详解
一维卷积神经网络(1DCNN)前向计算原理详解
yolov7开源代码讲解--训练代码
以前看CNN训练代码的时候,往往代码比较易懂,基本很快就能知道各个模块功能,但到了后面很多出来的网络中,由于加入了大量的trick,导致很多人看不懂代码,代码下载以后无从下手。训练参数和利用yaml定义网络详细过程可以看我另外的文章,都有写清楚。其实不管什么网络,训练部分大体都分几个部分:1.网络的
超参数调优框架optuna(可配合pytorch)
全自动超参数调优框架——optuna
YOLOv5改进之添加注意力机制
本文主要给大家讲解一下,如何在yolov5中添加注意力机制,这里提供SE通道注意力的改进方法,其他注意力的添加方法,大同小异首先找到SE注意力机制的pytorch代码class SELayer(nn.Module): def __init__(self, c1, r=16): s
【深度学习经典网络架构—8】:注意力机制之SE_Block
😺一、引言类似于人脑的注意力感知,那卷积神经网络能否也能产生注意力效果呢?答案是:**可以!****SE_Block是SENet的子结构**,作者将SE_Block用于ResNeXt中,并在ILSVRC 2017大赛中拿到了分类任务的第一名,在ImageNet数据集上将top-5 error降低到
pycharm运行yolov5-v5.0 (深度学习yolov5-篇二)
pycharm 运行yolov5-v5.0
详解准确率acc、精确率p、准确率acc、F1 score
准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 Score
GPT-4——比GPT-3强100倍
ChatGPT的地位可能即将被自家的GPT-4超越。
一文详解 ChatGPT:背后的技术,数据,未来发展
LM有基于大量训练数据的天然的迁移学习能力,但要在新域上获得较好的性能,使用Fine-tuning,就要求重新多次训练预训练模型,导致吃内存。ChatGPT 的卓越表现得益于其背后多项核心算法的支持和配合,包括作为其实现基础的 Transformer 模型、激发出其所蕴含知识的 Prompt/Ins
【深度学习笔记】特征融合concat和add的区别
在网络模型当中,经常要进行不同通道特征图的信息融合相加操作,以整合不同通道的信息,在具体实现方面特征的融合方式一共有两种,一种是 ResNet 和 FPN 等当中采用的 element-wise add ,另一种是 DenseNet 等中采用的 concat。add相当于加了一种prior,当两路输
GPT视角学习:spring注解『文末赠书:提供免费国内GPT链接』
GPT视角学习:spring注解『文末赠书:评论区提供免费稳定国内GPT链接』



