
目前的研究倾向于使用更深层次的卷积神经网络来提高性能。然而,盲目增加网络深度不能有效改善网络。更糟糕的是,随着网络深度的增加,训练过程中出现了更多的问题,需要更多的训练技巧。在本文中,我们提出了一种新颖的多尺度残差网络 (MSRN) 来充分利用图像特征,该网络优于大多数最先进的方法。基于残差块,我们引入不同大小的卷积核,以自适应地检测不同尺度的图像特征。同时,我们让这些特征相互作用以获得最有效的图像信息,我们将这种结构称为多尺度残差块 (MSRB)。此外,每个MSRB的输出都用作全局特征融合的分层特征。最后,将所有这些特征送到重建模块,以恢复高质量的图像。
特征提取模块

图a是基础的残差块,可以加深网络。图b是密集残差块,相比于基础残差块,密集残差块具有更多的跳跃连接,这加强了特征的复用。基础残差块和密集残差块都是使用单一大小的卷积核。图c是inception结构,其主要思想就是为了寻找最优的局部稀疏结构。但是作者认为不同尺度的特征简单串联将会导致局部特征利用不足。
模型结构

首先,我们使用MSRB获取不同尺度的图像特征,这被认为是局部多尺度特征。其次,将每个MSRB的输出组合起来进行全局特征融合。最后,将局部多尺度特征与全局特征相结合,可以最大限度地利用LR图像特征,彻底解决特征在传输过程中消失的问题。此外,我们引入了具有1 × 1内核的卷积层作为瓶颈层,以进行全局特征融合。
MSRB
为了检测不同尺度的图像特征,我们提出了多尺度残差块。我们的MSRB包含两个部分: 多尺度特征融合和局部残差学习。
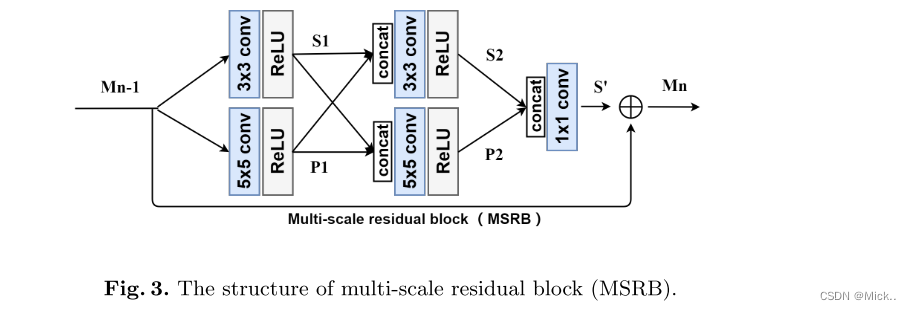


分层特征融合(HFFS)
对于SISR问题,输入和输出图像高度相关。充分利用输入图像的特征并将其传输到网络末端进行重建至关重要。但是,随着网络深度的增加,这些特征在传输过程中逐渐消失。在这个问题的驱动下,提出了各种方法,其中跳过连接是最简单,最有效的方法。所有这些方法都试图在不同的层之间创建不同的连接。不幸的是,这些方法不能充分利用输入图像的特征,并生成过多的冗余信息。
在实验中,我们注意到随着深度的增长,网络的空间表达能力逐渐降低,而语义表达能力逐渐增强。此外,每个MSRB的输出都包含不同的特征。因此,如何充分利用这些层次特征将直接影响重建图像的质量。在这项工作中,使用了简单的分层特征融合结构。我们将MSRB的所有输出发送到网络的末端进行重建。一方面,这些特征图包含大量冗余信息。另一方面,直接使用它们进行重建会大大增加计算复杂度。为了从这些层次特征中自适应地提取有用的信息,我们引入了瓶颈层,这对于具有1 × 1内核的卷积层至关重要。

这里接收了所有MSRB的输出,包括一开始的卷积层,如果这些特征直接输入重建网络会出现特征冗余,计算量比较大,所以作者这里引入了1*1的瓶颈层。
重建模块

实验
数据集
选择DIV2K [11] 作为我们的训练数据集,这是一种新的高质量图像数据集,可应对图像恢复挑战。在测试过程中,我们选择了五个广泛使用的基准数据集: Set5 [17],Set14 [18],BSDS100 [19],Urban100 [20] 和Manga109 [21]。这些数据集包含各种各样的图像,可以完全验证我们的模型。在先前的工作之后,我们所有的训练和测试都基于YCbCr色彩空间中的亮度通道,并且使用缩放因子: × 2,× 3,× 4,× 8进行训练和测试。
具体细节
在 [6] 之后,我们以三种方式增强训练数据 :( 1) 缩放 (2) 旋转 (3) 翻转。在每个训练批中,我们随机提取16个大小为64 × 64的LR图像块,并且训练1000个epoch。通过设置学习率lr = 0.0001,我们使用ADAM优化器 [22] 训练模型。在我们的最终模型中,我们使用8个多尺度残差块 (MSRB,N = 8),每个MSRB的输出具有64个特征图。同时,每个瓶颈层 (1 × 1卷积层) 的输出具有64个特征图。
对比算法
除了EDSR,其他全部都是重新训练的
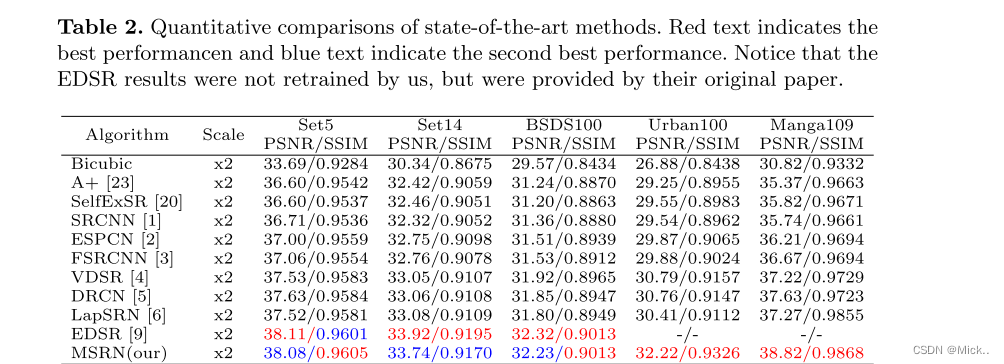
** 和EDSR的对比**

可以看到相比EDSR,MSRN模型的参数量更小。
消融实验
验证了多尺度特征提取块的作用
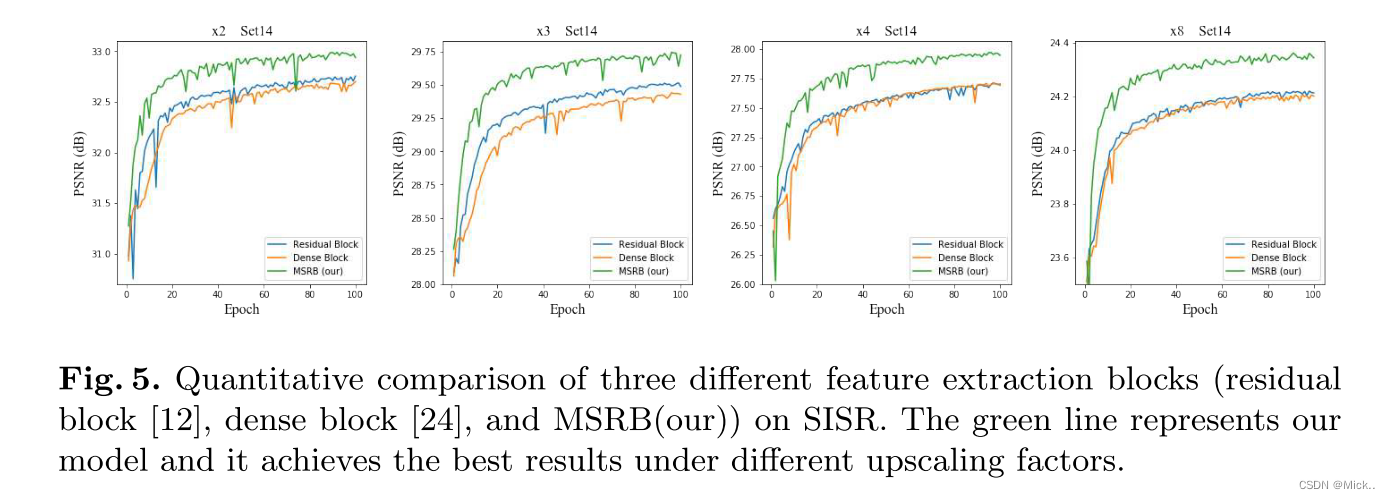
多尺度特征提取块的数量
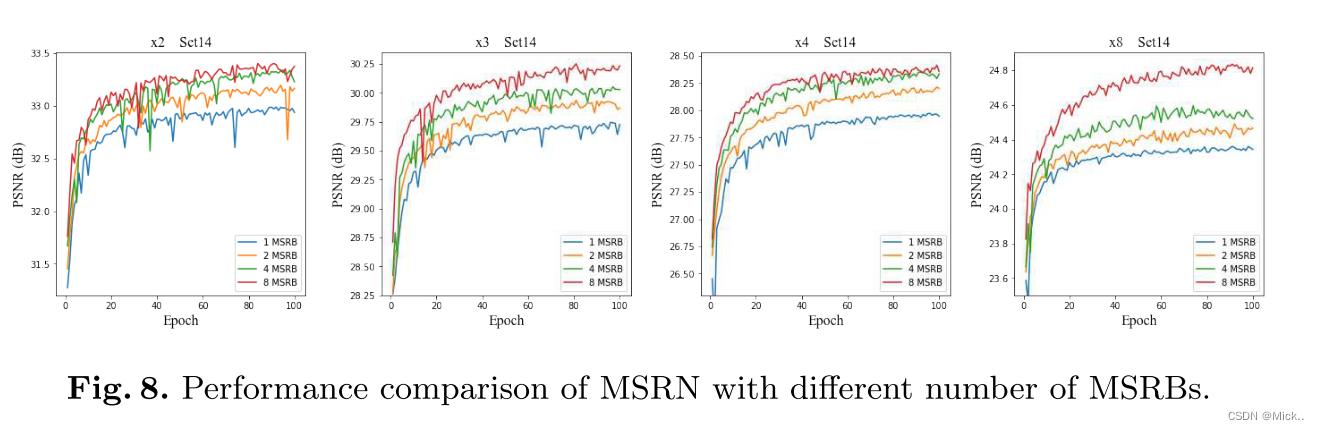
不同特征提取模块中间特征图的可视化

讨论
在SISR中,已经提出了许多训练技巧,以使重建的图像更加逼真。例如,在 [4],[9] 中使用了多尺度 (此处的尺度表示上缩放因子) 混合训练方法,在 [9] 中提出了几何自系综方法。我们相信这些训练技巧也可以提高我们的模型性能。然而,我们更倾向于探索一个有效的模型,而不是使用训练技巧。尽管我们的模型显示出卓越的性能,但在较大的放大因子下,重建的图像仍然不够清晰。在今后的工作中,我们将更加关注大尺度因子的图像重建
总结
在本文中,我们提出了一种有效的多尺度残差块 (MSRB),用于自适应地检测不同尺度的图像特征。基于MSRB,我们提出了多尺度残差网络 (MSRN)。这是一个简单而有效的SR模型,因此我们可以充分利用局部多尺度特征和层次特征来获得准确的SR图像。此外,我们通过将MSRB模块应用于其他计算机视觉任务,如图像去噪和图像去雾,取得了令人鼓舞的结果
import math
import torch
import torch.nn as nn
def default_conv(in_channels, out_channels, kernel_size, bias=True):
return nn.Conv2d(
in_channels, out_channels, kernel_size,
padding=(kernel_size//2), bias=bias)
class MeanShift(nn.Conv2d):
def __init__(self, rgb_range, rgb_mean, rgb_std, sign=-1):
super(MeanShift, self).__init__(3, 3, kernel_size=1)
std = torch.Tensor(rgb_std)
self.weight.data = torch.eye(3).view(3, 3, 1, 1)
self.weight.data.div_(std.view(3, 1, 1, 1))
self.bias.data = sign * rgb_range * torch.Tensor(rgb_mean)
self.bias.data.div_(std)
self.requires_grad = False
class BasicBlock(nn.Sequential):
def __init__(
self, in_channels, out_channels, kernel_size, stride=1, bias=False,
bn=True, act=nn.ReLU(True)):
m = [nn.Conv2d(
in_channels, out_channels, kernel_size,
padding=(kernel_size//2), stride=stride, bias=bias)
]
if bn: m.append(nn.BatchNorm2d(out_channels))
if act is not None: m.append(act)
super(BasicBlock, self).__init__(*m)
class ResBlock(nn.Module):
def __init__(
self, conv, n_feats, kernel_size,
bias=True, bn=False, act=nn.ReLU(True), res_scale=1):
super(ResBlock, self).__init__()
m = []
for i in range(2):
m.append(conv(n_feats, n_feats, kernel_size, bias=bias))
if bn: m.append(nn.BatchNorm2d(n_feats))
if i == 0: m.append(act)
self.body = nn.Sequential(*m)
self.res_scale = res_scale
def forward(self, x):
res = self.body(x).mul(self.res_scale)
res += x
return res
class Upsampler(nn.Sequential):
def __init__(self, conv, scale, n_feats, bn=False, act=False, bias=True):
m = []
if (scale & (scale - 1)) == 0: # Is scale = 2^n?
for _ in range(int(math.log(scale, 2))):
m.append(conv(n_feats, 4 * n_feats, 3, bias))
m.append(nn.PixelShuffle(2))
if bn: m.append(nn.BatchNorm2d(n_feats))
if act == 'relu':
m.append(nn.ReLU(True))
elif act == 'prelu':
m.append(nn.PReLU(n_feats))
elif scale == 3:
m.append(conv(n_feats, 9 * n_feats, 3, bias))
m.append(nn.PixelShuffle(3))
if bn: m.append(nn.BatchNorm2d(n_feats))
if act == 'relu':
m.append(nn.ReLU(True))
elif act == 'prelu':
m.append(nn.PReLU(n_feats))
else:
raise NotImplementedError
super(Upsampler, self).__init__(*m)
class MSRB(nn.Module):
def __init__(self, conv=default_conv, n_feats=64):
super(MSRB, self).__init__()
kernel_size_1 = 3
kernel_size_2 = 5
self.conv_3_1 = conv(n_feats, n_feats, kernel_size_1)
self.conv_3_2 = conv(n_feats * 2, n_feats * 2, kernel_size_1)
self.conv_5_1 = conv(n_feats, n_feats, kernel_size_2)
self.conv_5_2 = conv(n_feats * 2, n_feats * 2, kernel_size_2)
self.confusion = nn.Conv2d(n_feats * 4, n_feats, 1, padding=0, stride=1)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
input_1 = x
output_3_1 = self.relu(self.conv_3_1(input_1))
output_5_1 = self.relu(self.conv_5_1(input_1))
input_2 = torch.cat([output_3_1, output_5_1], 1)
output_3_2 = self.relu(self.conv_3_2(input_2))
output_5_2 = self.relu(self.conv_5_2(input_2))
input_3 = torch.cat([output_3_2, output_5_2], 1)
output = self.confusion(input_3)
output += x
return output
class MSRN(nn.Module):
def __init__(self,scale=2, conv=default_conv):
super(MSRN, self).__init__()
n_feats = 64
n_blocks = 8
kernel_size = 3
self.scale = scale
act = nn.ReLU(True)
self.n_blocks = n_blocks
# RGB mean for DIV2K
rgb_mean = (0.4488, 0.4371, 0.4040)
rgb_std = (1.0, 1.0, 1.0)
self.sub_mean = MeanShift(255, rgb_mean, rgb_std)
# define head module
modules_head = [conv(3, n_feats, kernel_size)]
# define body module
modules_body = nn.ModuleList()
for i in range(n_blocks):
modules_body.append(
MSRB(n_feats=n_feats))
# define tail module
modules_tail = [
nn.Conv2d(n_feats * (self.n_blocks + 1), n_feats, 1, padding=0, stride=1),
conv(n_feats, n_feats, kernel_size),
Upsampler(conv, self.scale, n_feats, act=False),
conv(n_feats, 3, kernel_size)]
self.add_mean = MeanShift(255, rgb_mean, rgb_std, 1)
self.head = nn.Sequential(*modules_head)
self.body = nn.Sequential(*modules_body)
self.tail = nn.Sequential(*modules_tail)
def forward(self, x):
x = self.sub_mean(x)
x = self.head(x)
res = x
MSRB_out = []
for i in range(self.n_blocks):
x = self.body[i](x)
MSRB_out.append(x)
MSRB_out.append(res)
res = torch.cat(MSRB_out,1)
x = self.tail(res)
x = self.add_mean(x)
return x
def load_state_dict(self, state_dict, strict=False):
own_state = self.state_dict()
for name, param in state_dict.items():
if name in own_state:
if isinstance(param, nn.Parameter):
param = param.data
try:
own_state[name].copy_(param)
except Exception:
if name.find('tail') >= 0:
print('Replace pre-trained upsampler to new one...')
else:
raise RuntimeError('While copying the parameter named {}, '
'whose dimensions in the model are {} and '
'whose dimensions in the checkpoint are {}.'
.format(name, own_state[name].size(), param.size()))
elif strict:
if name.find('tail') == -1:
raise KeyError('unexpected key "{}" in state_dict'
.format(name))
if strict:
missing = set(own_state.keys()) - set(state_dict.keys())
if len(missing) > 0:
raise KeyError('missing keys in state_dict: "{}"'.format(missing))
if __name__=='__main__':
model=MSRN(scale=2)
print(model)
from torchinfo import summary
x=torch.rand(1,3,48,48)
print('*'*20)
summary(model,x.shape)
from torchstat import stat
x=torch.rand(3,48,48)
print('*'*20)
stat(model,x.shape)
版权归原作者 南妮儿 所有, 如有侵权,请联系我们删除。