AI 大模型 LLM 中的注意力架构原理
上文所举的机器翻译的例子里,因为在计算Attention的过程中,Source中的Key和Value合二为一,指向的是同一个东西,也即输入句子中每个单词对应的语义编码,所以可能不容易看出这种能够体现本质思想的结构。在一般任务的Encoder-Decoder框架中,输入Source和输出Target内
跟李沐学AI 动手学深度学习 环境配置d2l、pytorch的安装 (windows环境、python版本3.7)
我们的任务主要有:配置过程中主要参考了以下文章:https://blog.csdn.net/qq_38311396/article/details/120768038配置详细步骤:第一步:根据操作系统下载并安装MinicondaMiniconda下载地址:(https://conda.io/en/m
U-ViT(CVPR2023)——ViT与Difussion Model的结合
扩散模型(Diffusion Model)最近在图像生成领域大火。而在扩散模型中,带有U-Net的卷积神经网络居于统治地位。U-ViT网络是将在图像领域热门的结合应用在了中。本文将从Vision Transformer出发,分析U-ViT这篇CVPR2023的Paper并记录一些感想。
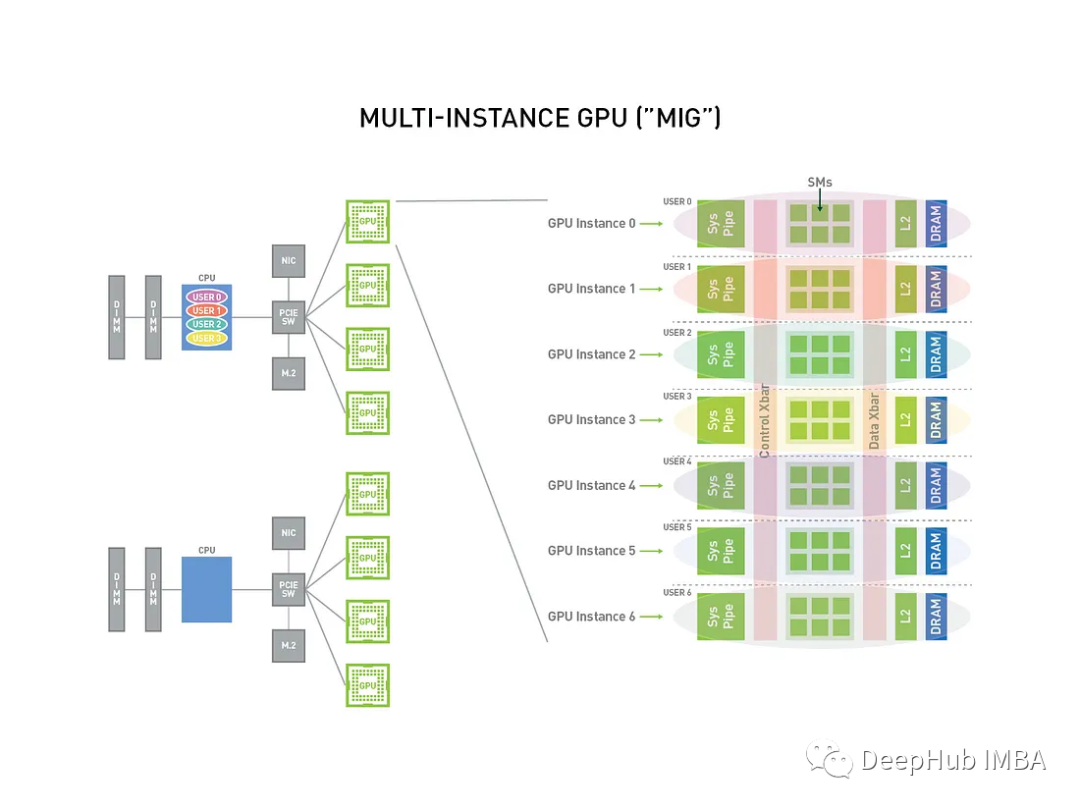
GPU 虚拟化技术MIG简介和安装使用教程
使用多实例GPU (MIG/Multi-Instance GPU)可以将强大的显卡分成更小的部分,每个部分都有自己的工作,这样单张显卡可以同时运行不同的任务。本文将对其进行简单介绍并且提供安装和使用的示例。
人工智能智能决策支持系统:技术、特点和挑战
机器学习:机器学习是一种人工智能技术,通过训练模型,让模型从数据中学习规律,并自动调整模型参数,从而实现对决策问题的分析和预测。深度学习:深度学习是一种更加先进的机器学习技术,通过多层神经网络的训练,可以实现更加复杂的特征提取和特征表示,从而实现更加准确的分析和预测。自然语言处理:自然语言处理是一种
3、TensorFlow教程--- 理解人工智能
遵循机器学习概念的程序的能力是改善其对观测数据的性能。数据转换的主要动机是为了提高其知识,以便在未来实现更好的结果,为特定系统提供更接近所期望的输出。监督学习或监督训练包括一个过程,其中训练集作为输入提供给系统,在这个过程中,每个示例都带有一个期望的输出值标签。在这种类型的训练中,使用特定损失函数的
Windows 下载与安装CUDA和Pytorch【安装教程、深度学习】
我们训练速度每秒处理2510张样本,而在云上,则可以处理到4722张样本每秒。出现了这个错误的话,是网络原因(可以先切换一下网络xxx,然后再次启动)将下面显示的命令复制到我们刚才打开的Miniconda中。可以直接选择Windows打开,将会显示新添加的模块。这里需要安装的包有点大,需要等待一会儿
人工智能大模型(LLM)的核心能力、具体的应用场景和具体的落地步骤
零样本学习能力是指模型在没有人工干预的情况下,可以通过大规模数据的学习,自动掌握各类任务的知识和规律,并进行准确的预测和推理。在众多的自然语言处理任务中,语言模型被广泛应用于机器翻译、问答系统、文本摘要、对话系统等,这些任务需要模型理解人类语言的语义和上下文信息,并进行准确的预测和生成。以上为人工智
人工智能:神经细胞模型到神经网络模型
1969年,美国麻省理工学院(MIT)出版了关于感知机的专著《Perceptrons:An Introduction to Computational Geometry》,作者为明斯基(M.L.Minsky)等,对简单感知机的研究结果进行了总结与系统的分析,指出简单感知机有严重的缺陷,无法识别线性
【人工智能】ChatGPT 技术架构与相关技术栈清单
在基于语言模型的生成式模型中,模型会根据输入的上下文预测下一个词,并不断地生成文本,直到达到预定长度为止。通过不断与人类进行交互,模型可以学习和优化自己的回复策略,并通过PPO机制,提高模型在强化学习任务上的表现能力,从而产生更加符合人类语言习惯的对话回复。在基于模型的迁移学习中,模型会将已学习的模
归一化(Normalization)
归一化是一种数据处理方式,能将数据经过处理后限制在某个固定范围内。归一化存在两种形式,一种是在通常情况下,将数处理为 [0, 1] 之间的小数,其目的是为了在随后的数据处理过程中更便捷。例如,在图像处理中,就会将图像从 [0, 255] 归一化到 [0, 1]之间,这样既不会改变图像本身的信息储存,
深度学习中常用的损失函数(一) —— MSELoss()
MSELoss() 损失函数学习笔记
注意力机制
在神经网络学习中,一般而言模型的参数越多则模型的表达能力越强,模型所存储的信息量也越大,但这会带来信息过载的问题。通过引入注意力机制,在众多的输入信息中聚焦于对当前任务更为关键的信息,降低对其他信息的关注度,甚至过滤掉无关信息,就可以解决信息过载问题,并提高任务处理的效率和准确性。
自监督表征学习方法——DINO方法
在这项工作中,我们展示了自监督预训练一个标准ViT模型的潜力,实现的性能是与为此设置设计的最佳凸网相媲美的。我们还看到了两个可以在未来应用中利用的特性:k-NN分类中特征的质量具有图像检索的潜力,其中ViT已经显示出了有希望的结果。然而,本文的主要结果是,我们有证据表明,自我监督学习可能是开发一个基
从GPU的内存访问视角对比NHWC和NCHW
NHWC和NCHW之间的选择会影响内存访问、计算效率吗?本文将从模型性能和硬件利用率来尝试说明这个问题。
华为开源自研AI框架昇思MindSpore应用案例:分布式并行训练基础样例(CPU)
华为开源自研AI框架昇思MindSpore应用案例:分布式并行训练基础样例
U-Net 模型改进和应用场景研究性综述
参考之前的一篇文章:U-Net代码练习结构性改进就三种情况,编码器解码器改进,跳连接改进,以及模型整体结构改进;大 部 分 改 进 工 作是在原有模块的基础上,增加残差模块、Dense 模 块 、Inception 模 块 、Attention 模 块 等 经 典 网 络 模 块 , 或 综 合 运
使用python实现LDA线性判别分析
LDA(Linear Discriminant Analysis)线性判别分析是一种监督学习的线性分类算法,它可以将一个样本映射到一条直线上,从而实现对样本的分类。LDA的目标是找到一个投影轴,使得经过投影后的两类样本之间的距离最大,而同一类样本之间的距离最小。LDA的过程可以分为以下几步:1.计算
【人工智能】深度强化学习的新突破:如何打造智能决策系统
在深度强化学习中,有很多的概念和术语需要我们去了解。本文介绍了深度强化学习技术的相关概念、原理及应用,以及如何使用深度强化学学实现智能决策系统。在深度强化学习中,模型设计、数据集选择、模型评估和应用场景都是需要我们注意的重要因素。通过实际案例的演示,我们可以看到深度强化学习技术在实践中的应用和实现过

CLIP与DINOv2的图像相似度对比
在本文中,我们将探讨CLIP和DINOv2的优势和它们直接微妙的差别。我们的目标是发现哪些模型在图像相似任务中真正表现出色。



