人工智能——机器学习——神经网络(深度学习)
人工智能是让机器获得像人类一样具有思考和推理机制的智能技术,这一概念最早出现在 1956 年召开的达特茅斯会议上。其中深度学习可以理解为神经网络。刚开始只有神经网络的概念,随着神经网络的层数增加,就逐渐将神经网络叫做深度学习。神经网络的发展历程大致分为浅层神经网络阶段和深度学习阶段。
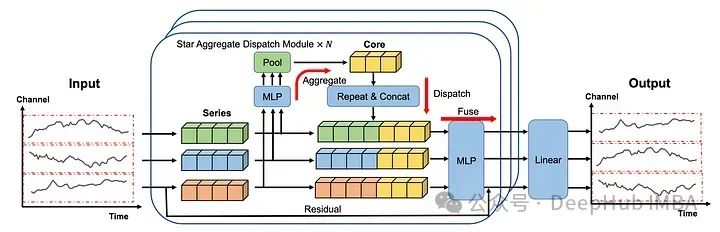
SOFTS: 时间序列预测的最新模型以及Python使用示例
这是2024年4月提出的新模型,采用集中策略来学习不同序列之间的交互,从而在多变量预测任务中获得最先进的性能。
【机器学习】QLoRA:基于PEFT亲手微调你的第一个AI大模型
本文首先对量化和微调的原理进行剖析,接着以Qwen2-7B为例,基于QLoRA、PEFT一步一步带着大家微调自己的大模型,本文参考全网peft+qlora微调教程,一步一排坑,让大家在网络环境不允许的情况下,也能丝滑的开启大模型微调之旅。
AI训练,为什么需要GPU?
随着人工智能热潮,GPU成为了AI大模型训练平台的基石,决定了算力能力。为什么GPU能力压CPU,成为炙手可热的主角呢?首先我们要先了解一下GPU的分类。提到分类,就得提及到芯片。半导体芯片分为和。其中,数字芯片的市场规模占比较大,达到70%左右。。由上图可以看到,。现在特别火爆的AI,用到的所谓“
人工智能核心技术:机器学习总览
💡机器学习作为人工智能的核心,与计算机视觉、自然语言处理、语音处理和知识图谱密切关联💡【机器学习】是实现人工智能的核心方法,专门研究计算机如何模拟/实现生物体的学习行为,获取新的知识技能,利用经验来改善特定算法的性能。深度学习是机器学习算法的一种,深度学习算法具有多层神经网络结构,其在图像识别、
政安晨【零基础玩转各类开源AI项目】:解析开源项目:Champ 利用三维参数指导制作可控且一致的人体图像动画
介绍了一种人体图像动画制作方法,该方法利用潜在扩散框架中的三维人体参数模型,来增强 curernt 人体生成技术中的形状排列和运动引导。该方法利用 SMPL(Skinned Multi-Person Linear)模型作为三维人体参数模型,建立统一的身体形状和姿势表示。这有助于从源视频中准确捕捉复杂
Rust AI:机器学习Candle 和Burn框架的简单对比
Candle和Burn代表了Rust生态系统在机器学习和人工智能方面令人兴奋的发展。Candle为深度学习任务提供了简单性和高性能,而Burn则提供了更全面的ML堆栈和更大的灵活性。CandleBurn。
【机器学习】机器学习与金融科技在智能投资中的融合应用与性能优化新探索
机器学习是一种通过数据训练模型,并利用模型对新数据进行预测和决策的技术。其基本思想是让计算机通过样本数据学习规律,而不是通过明确的编程指令。根据学习的类型,机器学习可以分为监督学习、无监督学习和强化学习。金融科技(Fintech)是指将技术应用于金融服务和管理的创新。智能投资系统是金融科技的重要应用

通过元学习优化增益模型的性能:基础到高级应用总结
因果推断帮助我们理解不同变量间的因果关系,而增益模型则专注于评估干预措施对个体的影响,从而优化策略和行动。
自动驾驶人工智能
自动驾驶技术是一个复杂的领域,它依赖于算法和过滤器来解释传感器数据、做出决策和控制车辆。在本节中,我们将探讨自动驾驶技术中使用的不同类型的算法和过滤器,并用通俗易懂的语言来解释它们。
实验六 Spark机器学习库MLlib编程初级实践
数据集:下载Adult数据集(http://archive.ics.uci.edu/ml/datasets/Adult),该数据集也可以直接到本教程官网的“下载专区”的“数据集”中下载。//获取训练集测试集(需要对测试集进行一下处理,adult.data.txt的标签是>50K和50K.和
【Educoder】— 机器学习(PCA第二关)
PCA的算法流程。
【Centos7】解决 CentOS 7 中出现 “xx: command not found“ 错误的全面指南
【Centos7】解决 CentOS 7 中出现 “xx: command not found“ 错误的全面指南
机器学习、深度学习、AI工程师、人工智能面试热点问题(一)
混淆矩阵(Confusion matrix)计算过程混淆矩阵作为分类模型结果的更加细致精确的可视化展示,有时也被称为误差矩阵或者可能性表格,通常混淆矩阵会应用于二分类问题中,对此首先有如下关键定义:Actual condition:样本真实标签;·Predicated condition:模型预测标
【AI】人工智能(AI)的崛起与未来展望
本文将探讨AI的基本概念、发展历程、应用场景,并通过一些Python代码示例来展示AI的实际应用,最后对AI的未来进行展望。人机协同将成为未来AI发展的重要方向。随着技术的不断进步和应用场景的不断拓展,AI将在未来发挥更加重要的作用,为人类创造更加美好的未来。AI的发展经历了符号主义、连接主义和深度
常见的开源人脸检测模型有哪些
常见的开源人脸检测模型有哪些
【python】在【机器学习】与【数据挖掘】中的应用:从基础到【AI大模型】
Python在数据挖掘和机器学习中的应用,涵盖了数据预处理、特征工程、监督学习、非监督学习和深度学习。
人工智能、机器学习、深度学习:技术革命的深度解析
人工智能是一个广泛的概念,它涵盖了使机器执行通常需要人类智能的任务的能力。这包括但不限于学习、推理、解决问题、知识理解、语言识别、视觉感知、运动和操控。机器学习是人工智能的一个分支,它使计算机系统能够从数据中学习并做出决策或预测,而不需要进行明确的编程。深度学习是机器学习的一个子领域,它使用多层神经
【机器学习】机器学习与医疗健康在智能诊疗中的融合应用与性能优化新探索
机器学习是一种通过数据训练模型,并利用模型对新数据进行预测和决策的技术。其基本思想是让计算机通过样本数据学习规律,而不是通过明确的编程指令。根据学习的类型,机器学习可以分为监督学习、无监督学习和强化学习。医疗健康是指通过预防、诊断、治疗和康复等手段,维护和促进人类健康的过程。智能诊疗系统是医疗健康领
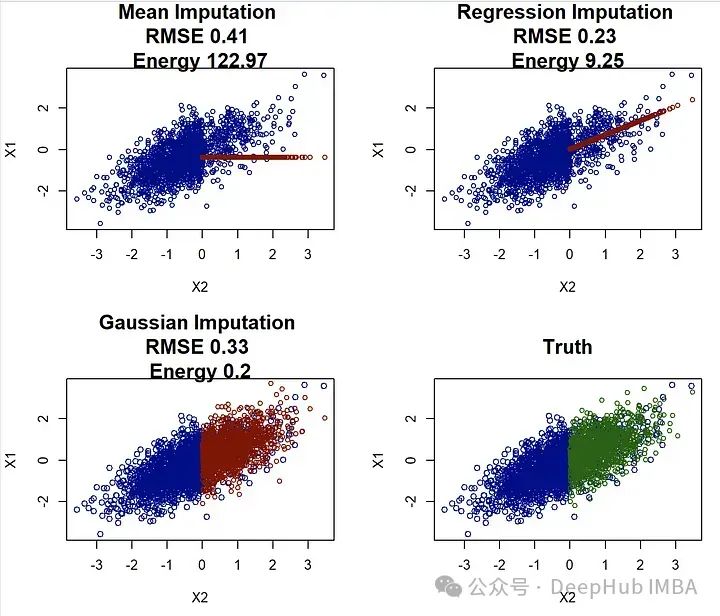
如何应对缺失值带来的分布变化?探索填充缺失值的最佳插补算法
本文将探讨了缺失值插补的不同方法,并比较了它们在复原数据真实分布方面的效果,处理插补是一个不确定性的问题,尤其是在样本量较小或数据复杂性高时的挑战,应选择能够适应数据分布变化并准确插补缺失值的方法。



