土地利用/土地覆盖数据整理
土地利用/土地覆盖数据是开展地理、生态、环境等研究的基础数据,本文对目前主流且开源的土地利用数据进行整理,随时更新,欢迎补充!
Spark大数据分析与实战课后答案
Spark大数据分析实战课后答案
全基因组测序数据分析---WGS主流程
全基因组测序数据分析
熬夜整理!200道Python数据分析习题+50个办公自动化案例!
大家好,之前整理干货内容都是授人以鱼,这次想不一样一些,鱼和渔都想送给大家。给大家分享早起整理的三份干货 Python数据分析200题 matplotlib图鉴100+ Python办公自动化实战案例 Python数据分析200题Pandas与NumPy都是Python数据分析中的利器,因此
数据可视化—绘制简单的折线图
数据可视化—绘制简单的折线图(持续更新数据可视化相关知识)敬请期待。。。

Pandas 2.0 简单介绍和速度评测
最近 Pandas 2.0 的RC版已经最近发布了。这个版本主要包括bug修复、性能改进和增加Apache Arrow后端。当涉及到使用DF时,Arrow比Numpy提供了更多的优势。
数据包络分析(超效率-SBM模型)附python代码
超效率-SBM模型超效率SBMpython代码(部分)这段时间差不多忙完了,终于有时间可以来经营我的博客了。上阵子挺多人私信我,原谅我记性不好,可能没有回复全。这篇文章是超效率的扩展。超效率SBMSBM本身就是非径向模型(non-radial model),想要了解径向超效率的请自行去前面翻阅。上篇
数据科学必备技巧:Pandas读取外部文件与数据处理
Pandas包除了提供序列、数据框的数据存储及操作方法之外,还提供丰富的函数,比如一些常用的数据计算及处理函数,包括滚动计算函数、数据框合并函数、数据框关联函数等。
数据分析之Pandas(1)
数据分析之pandas Pandas的基本数据结构 Pandas读取数据及数据操作 数据清洗数据格式转换排序基本统计分析 数据透视
100天精通Python(数据分析篇)——第75天:Pandas数据预处理之数据标准化
专栏导读 1. 数据标准化是什么? 2. 数据标准化的作用 3. 数据标准化的方法 4. 离差标准化 5. 标准差标准化 6. 小数定标标准化
Topic 14. 临床预测模型之校准曲线 (Calibration curve)
全网总结最全的校准曲线 Calibration curve
数据挖掘(1)--基础知识学习
自20世纪90年代以来,随着数据库技术应用的普及,数据挖掘( Data Mining )技术已经引起了学术界、产业界的极大关注,其主要原因是当前各个单位已经存储了超大规模,即海量规模的数据,未来能够真正发挥这些数据的实际价值。由于数据分析和管理工作的应用需要,需将这些数据转换成有用的信息和知识,即从
可怕,chatGPT用3小时教会我数据分析
可怕,chatGPT用3小时教会我数据
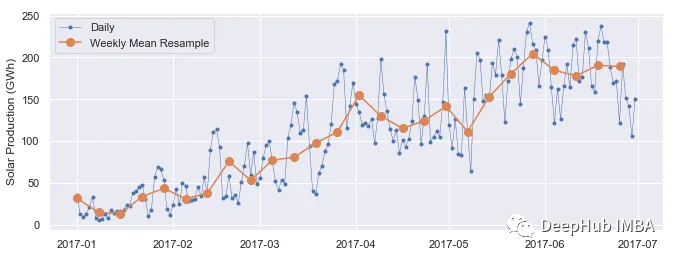
在Pandas中通过时间频率来汇总数据的三种常用方法
当我们的数据涉及日期和时间时,分析随时间变化变得非常重要。Pandas提供了一种方便的方法,可以按不同的基于时间的间隔(如分钟、小时、天、周、月、季度或年)对时间序列数据进行分组。
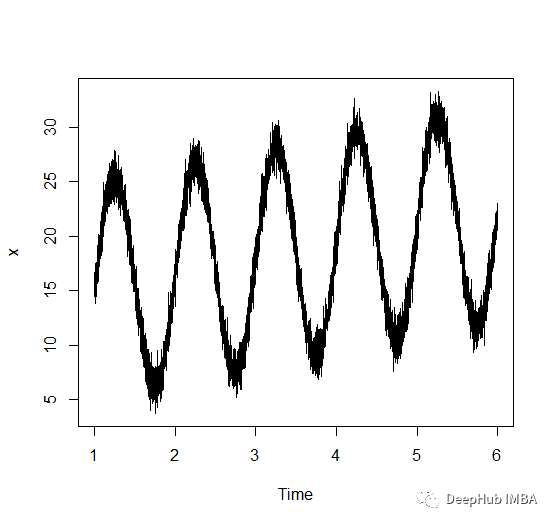
计算时间序列周期的三种方法
周期是数据中出现重复模式所需的时间长度。更具体地说,它是模式的一个完整周期的持续时间。在这篇文章中,将介绍计算时间序列周期的三种不同方法。
PySpark数据分析基础:核心数据集RDD常用函数操作一文详解(二)
PySpark系列的专栏文章目前的话应该只会比Pandas更多不会更少,可以用PySpark实现的功能太多了,基本上Spark能实现的PySpark都能实现,而且能够实现兼容python其他库,这就给了PySpark极大的使用空间,能够结合大数据集群实现更高效更精确的大数据处理或者预测。如果能够将这
100天精通Python(数据分析篇)——第48天:数据分析入门知识
数据分析入门知识:1. 为什么要学数据分析?2. 数据分析的概念3. 数据分析涉及哪些能力4. 数据分析的流程5. Python做数据分析学什么?
python处理csv文件
csv⽂件其实就是⽂本⽂件,遵循了⼀定的格式,常⻅的csv⽂件⼀般是⽤逗号来隔开列,⽤换⾏符隔开不同的⾏,注意这⾥的符号都是英⽂符号。我们可以直接⽤open函数来打开csv⽂件;本实验使用csv文件(example.csv)分享:https://osswangting.oss-cn
PySpark数据分析基础:核心数据集RDD原理以及操作一文详解(一)
要进行大数据分析是离不开Spark的,不然怎么说是大数据呢,数据量不达到几个TB也好意思叫大数据(哈...),之前一直使用的Pandas做一些少量数据的分析处理的,发现最近要玩的数据量实在过于巨大了,不得不搬上我们的spark用集群去跑了。但是用Scala总感觉很别扭,主要是已经好久没写scala代
PySpark数据分析基础:核心数据集RDD常用函数操作一文详解(三)
RDD作为分布式计算弹性数据集在PySpark占有十分重要的地位,因此学会如何操作RDD的pyspark的接口函数显得十分重要,PySpark系列的专栏文章目前的话应该只会比Pandas更多不会更少,可以用PySpark实现的功能太多了,基本上Spark能实现的PySpark都能实现,而且能够实现兼



