
前言
pandas主要的数据结构是Series和DataFrame,该两种数据结构并不难理解,语言都是共通的,只要了解C语言基础的数据结构或是Python、JAVA的都能理解。关键是如何运用函数处理这些数据结构。
一、pandas库引入
首先安装可直接cmd中输入:
pip install pandas
或者直接在anaconda中Environments中手动下载:
此文章建立在Jupyter之上进行操作演示。导入必要的库(包括numpy,matplotlib):
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
二、Pandas数据结构
1.Series
(1)创建
Series要理解很简单,就像它的单词为系列的意思。类似与数据结构中的字典有索引和对应值,也可以理解为数组,在Series中的下标1,2,3,...索引对应它的不同值。

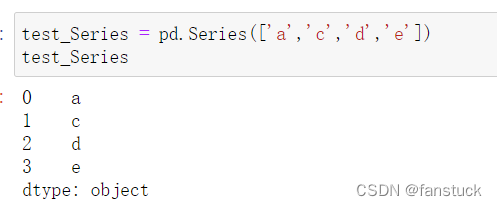
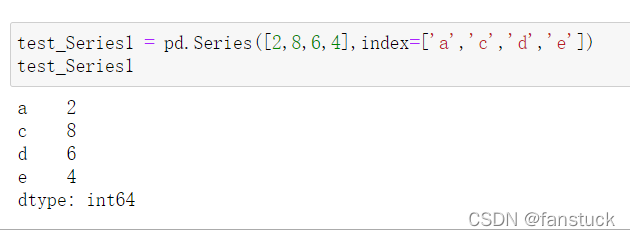
如果不指定Series的标签,它就会默认从0开始索引。当然可以设定索引数据:
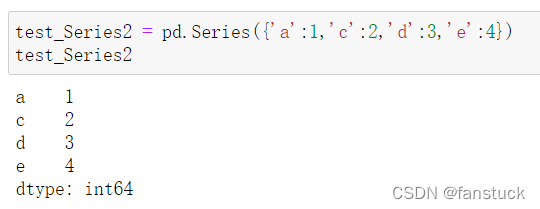
也可以像字典一样传入:
也可以给定两个数组再组成Series。

和数据一样可以通过访问它的values和index获得它的值和索引:

values返回的为数组,而index返回的是object类似为String。可以像字典一样查询索引:

若是直接传入一个字典作为值,则优先按索引列表为Series的索引列,若字典没有index的元素则默认为NaN。

(2)转换
从结构上看很明显和字典能够互相转换:

可以转换为元组列表:

转换为DataFrame:

当然这样转换的话列名会有问题,加个reset后就可以了。

(3)操作
可以通过一系列数学运算方法且索引不变,仅值发生改变。
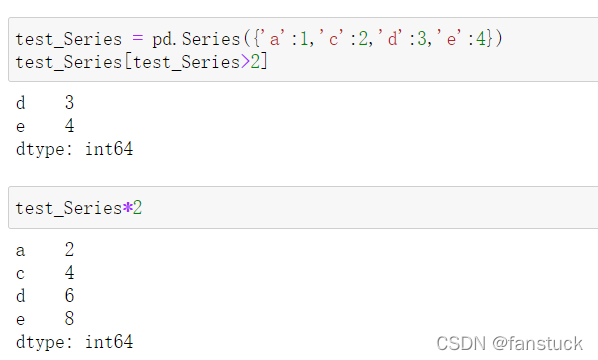
Series其中一个重要功能就是在做多个以上的Series可以做到根据索引自动对齐想加减操作:

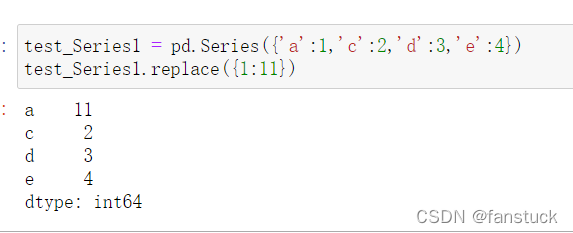
还可以使用replace()替换值:
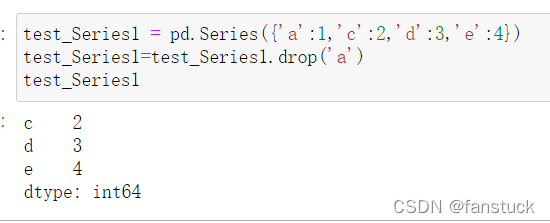
使用drop()可以丢掉索引条目及值:
两个index不同的series不能直接比较,需要提出values再进行比较。
2.DataFrame
刚才从Series转化为DataFrame就可以看出DataFrame的格式就像一张表格,包含行和列索引。通过对应的行列对DataFrame进行操作,更像是对SQL中表格处理,两者有一定的类似之处。因此学过SQL的对DataFrane的操作更容易了解。
(1)创建
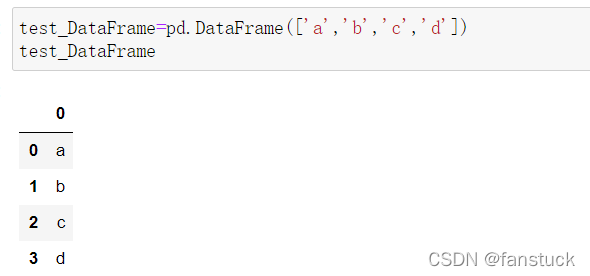
我们可以通过一个列表就可创建:
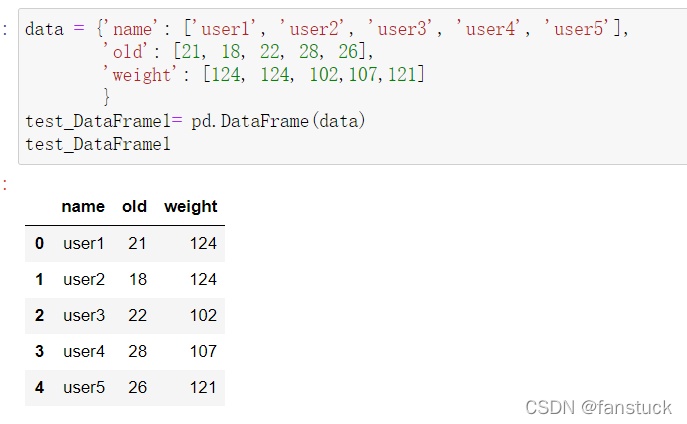
最常用的一个是用一个相等长度列表的字典或NumPy数组:
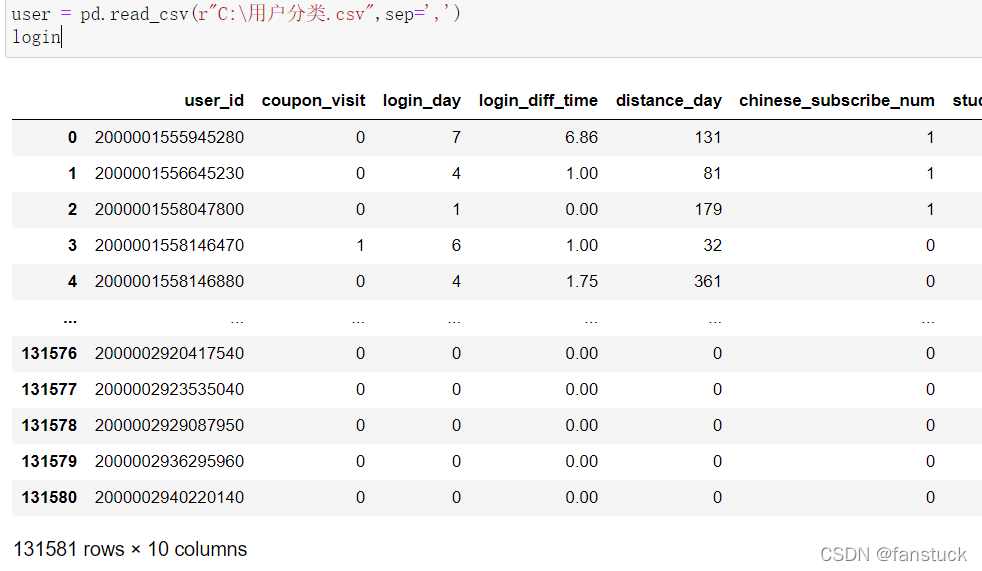
当然最常用的就是通过直接读入read_csv()函数直接创建一个基于csv格式转换而来的DataFrame:
当然如果没对行和列进行命名的话也是和Series一样从0开始依次排序的。
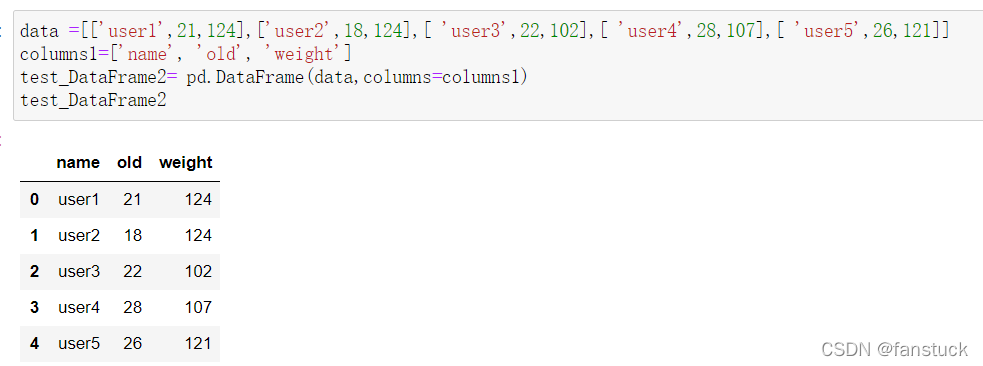
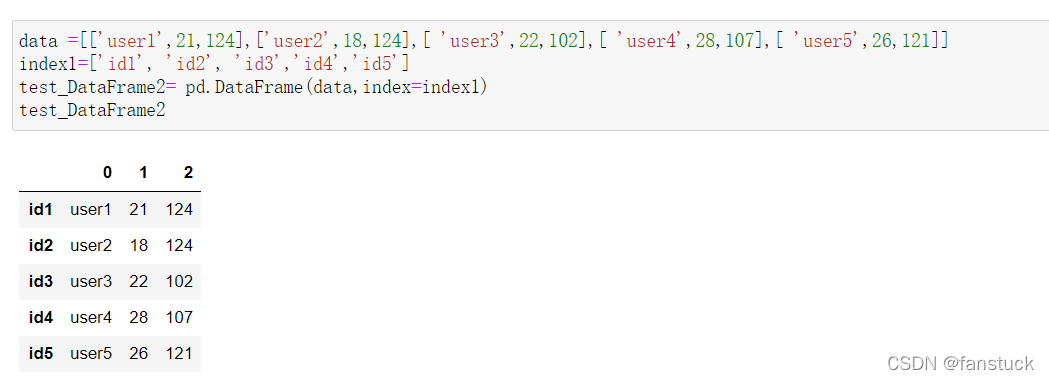
通过设定行索引和列索引创建DataFrame:
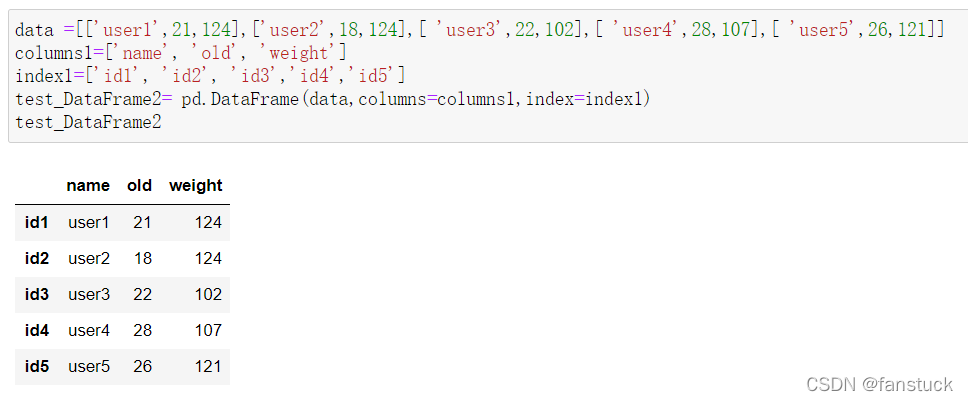
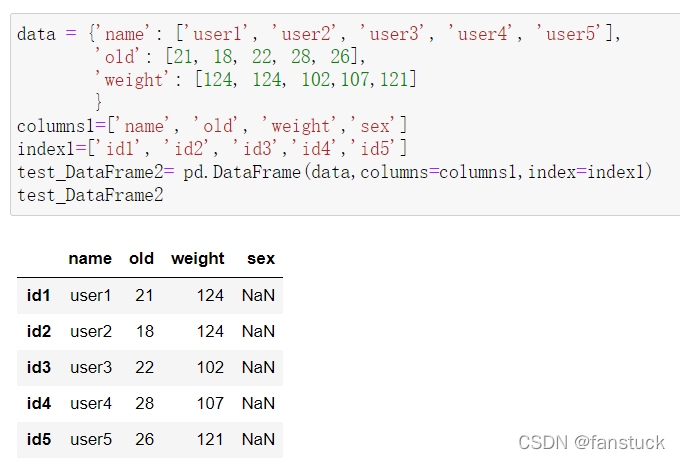
若是给了一个在原数据中并没有的列名则自动填补为空值:
若是仅有数据并没有传入字典类型结构,则根据列表维度处理,维度低于列数会报错:

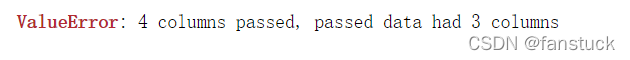
同理行也一样。
(2)转换
从DataFrame的结构中我们可以知道每一个列和行组合起来就像一个Series,和字典一样。所以转换为字典只能指定某一列来转换。

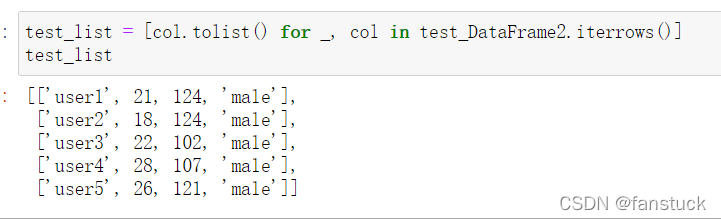
dataframe转换成嵌套list::
(3)操作
通过isnull()函数可以看到DataFrame中空值:
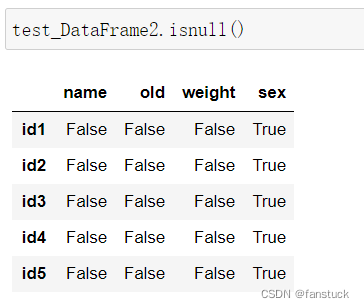
通常加上sum()函数看空值到底为多少:

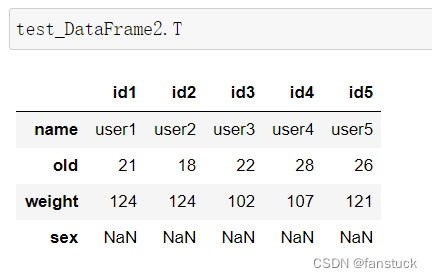
后面.T就为转置:
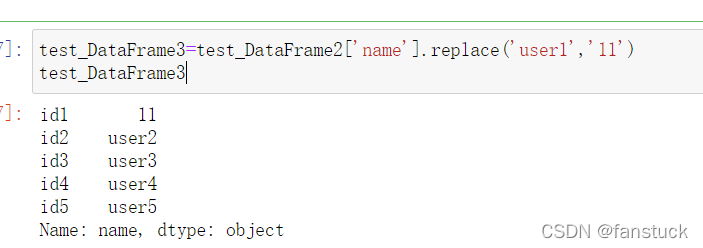
使用replace和Series可以把该结构内的所有数据都替换掉:
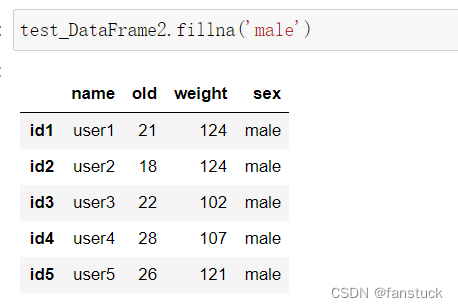
使用fillna()函数可以将空值统一替换为想要的数值(也可以设定为均值填充dataFrame.mean(),inplace = True、向上填充method=‘ffill’、向下填充method=‘bfill’、对应值填充df.replace({np.nan:‘aa’})):
然后就是drop()函数:
DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False)
参数说明:
- labels 就是要删除的行列的名字,用列表给定;
- axis 默认为0,指删除行,因此删除columns时要指定axis=1;
- index 直接指定要删除的行;
- columns 直接指定要删除的列;
- inplace=False,默认该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe;
- inplace=True,则会直接在原数据上进行删除操作,删除后无法返回。

通过head()看前5行数据和tail()可看指定行数数据:

遍历DataFrame给出了三个函数:
df.iterrows(),对DataFrame的每一行进行迭代,返回一个Tuple (index, Series):

df.iteriems(),对DataFrame相当于对列迭代:
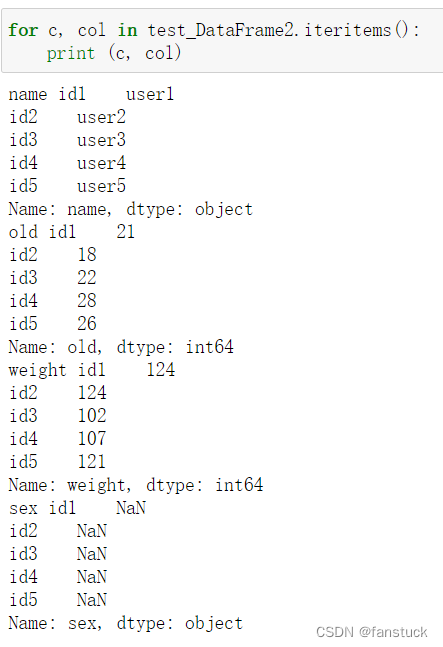
df.itertuples()迭代 DataFrame 的行,并将每行为元组进行打印:

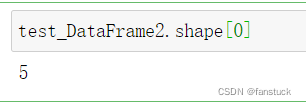
shape[0]可以快速查看行数:
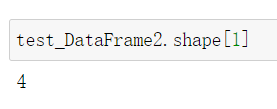
shape[1]则看列数:
dtypes则可以看每一列数据类型:

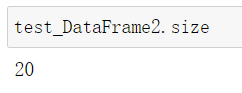
df.size则可以看到总共有多少数据:
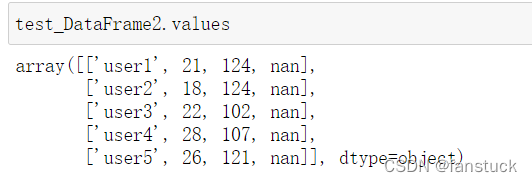
同样通过index和columns可以获取列和行索引列表,values获取值:

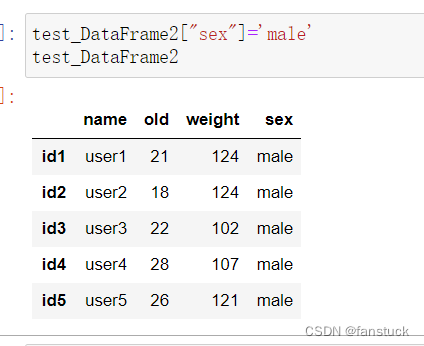
列可以通过赋值来修改:
下一章写DataFrame的行列和多表操作。
参阅:
pandas小记:pandas数据结构和基本操作_-柚子皮-的博客-CSDN博客_pandaspandas小记:pandas数据规整化-缺失、冗余、替换_-柚子皮-的博客-CSDN博客
版权归原作者 fanstuck 所有, 如有侵权,请联系我们删除。