【强化学习】Q-Learning算法详解以及Python实现【80行代码】
强化学习在文章正式开始前,请不要被强化学习的tag给吓到了,这也是我之前所遇到的一个困扰。觉得这个东西看上去很高级,需要一个完整的时间段,做详细的学习。相反,强化学习的很多算法是很符合直观思维的。 因此,强化学习的算法思想反而会是相当直观的。另外,需要强调的是,这个算法在很多地方都有很详细的阐述了。
强化学习入门笔记
我们先回忆一下童年,来看看超级玛丽这款游戏在这款游戏里面的,我们需要控制超级玛丽进行左右行走、跳、攻击等动作,来躲避或攻击小动物、吃金币以及各种类型的增益道具。最终,获得的金币数量的多少以及通关代表我们玩游戏玩的好不好。那么,如果我们希望让机器来玩这个游戏呢?怎么能让机器在合适的时候做出合适的动作?
PyTorch强化学习实战(1)——强化学习环境配置与PyTorch基础
工欲善其事,必先利其器。为了更专注于学习强化学习的思想,而不必关注其底层的计算细节,我们首先搭建相关强化学习环境,包括 PyTorch 和 Gym,其中 PyTorch 是我们将要使用的主要深度学习框架,Gym 则提供了用于各种强化学习模拟和任务的环境。除此之外,本文还介绍了一些 PyTorch 的

5篇关于将强化学习与马尔可夫决策过程结合使用的论文推荐
低光图像增强、离线强化学习、基于深度强化学习的二元分类决策森林的构建方法等最新的研究成果
强化学习—— 离散与连续动作空间(随机策略梯度与确定策略梯度)
强化学习—— 离散与连续动作空间(随机策略梯度与确定策略梯度)1. 动作空间1.1 离散动作空间1.2 连续动作空间1. 动作空间1.1 离散动作空间比如:{left,right,up}\{left,right,up\}{left,right,up}DQN可以用于离散的动作空间(策略网络)1.2
强化学习(四)—— Actor-Critic
强化学习(四)—— Actor-Critic1. 网络结构2. 网络结构2. 策略网络的更新-策略梯度3. 价值网络的更新-时序差分(TD)4. 网络训练流程3. 案例1. 网络结构状态价值函数:Vπ(st)=∑aQπ(st,a)⋅π(a∣st)V_\pi(s_t)=\sum_aQ_\pi(s_t

5篇关于强化学习在金融领域中应用的论文推荐
近年来机器学习在各个金融领域各个方面均有应用,其实金融领域的场景是很适合强化学习应用
强化学习 | 策略梯度 | Natural PG | TRPO | PPO
递进学习策略梯度:从 Gradient、Policy Gradient (REINFORCE、Q Actor-Critic、Advantage Actor-Critic ) 至 Natural Policy Gradient、TRPO、PPO 。逻辑清晰,含大量手写笔记,注释了黎曼流形、Hessia
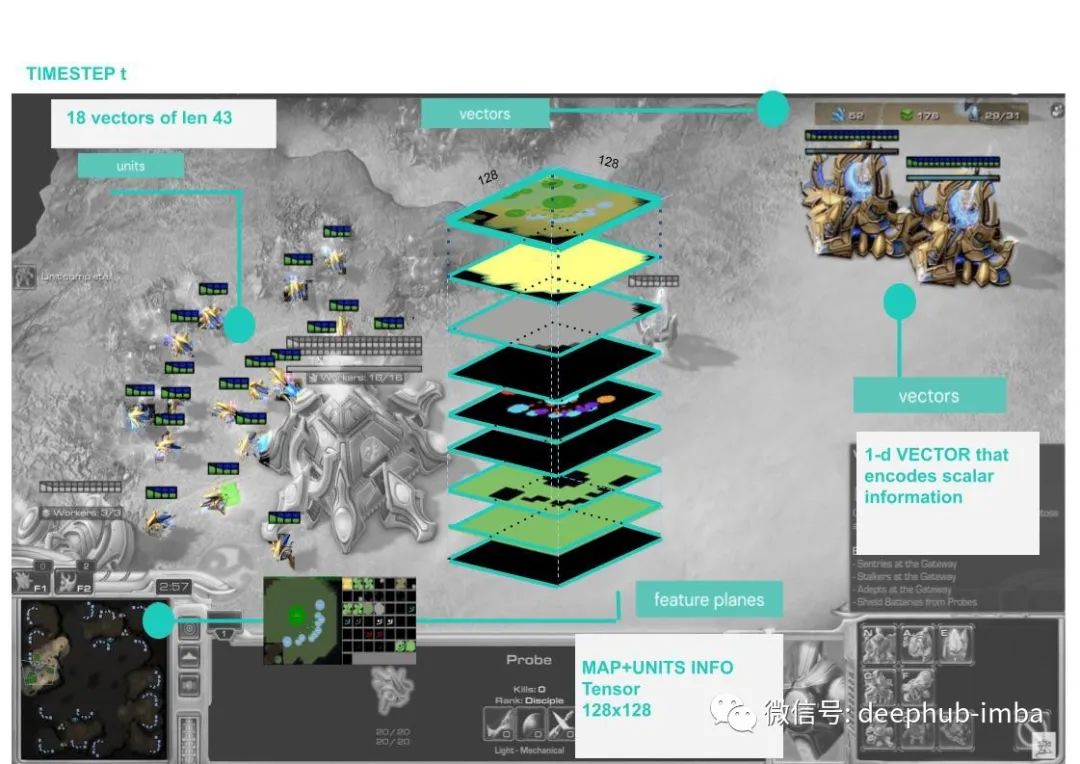
论文推荐:StarCraft II Unplugged 离线强化学习
在本文中,我们将介绍 StarCarft II Unplugged 论文 [1],本论文可以将AlphaStar进行了扩展或者说更好的补充解释,绝对值得详细阅读。
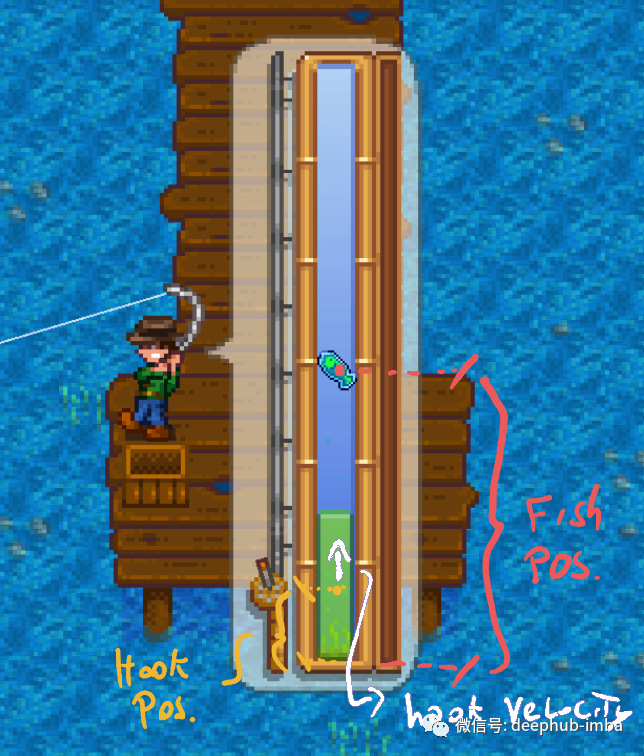
通过强化学习和官方API制作《星露谷物语》的自动钓鱼mod
使用官方 Stardew Valley 的 modding API 用 C# 编写一个自动钓鱼的mod

AlphaZero如何学习国际象棋的?
DeepMind 和 Google Brain 研究人员以及前世界国际象棋冠军Vladimir Kramnik通过概念探索、行为分析和对其激活的检查,探索了人类知识是如何获得的,以及国际象棋概念如何在 AlphaZero 神经网络中表示。
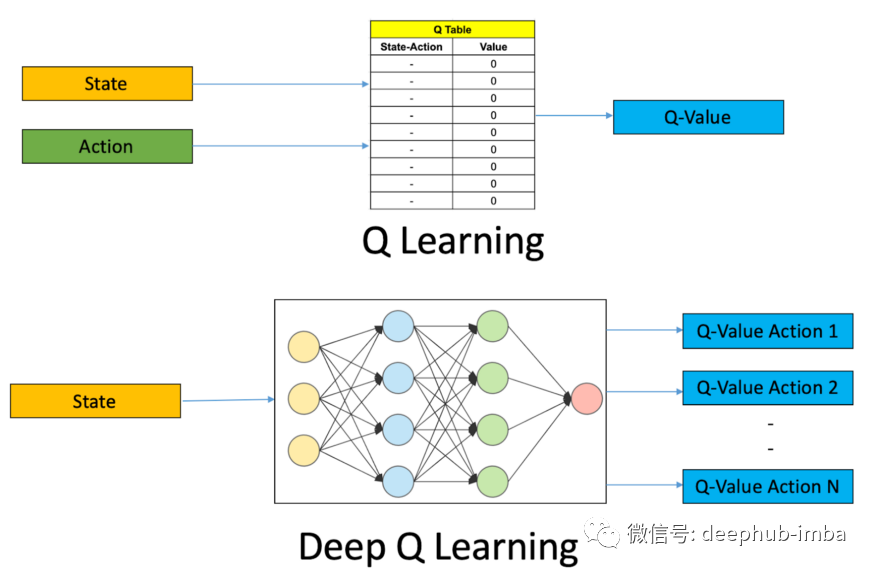
开启深度强化学习之路:Deep Q-Networks简介和代码示例
Deep Q-Learning 算法是深度强化学习的核心概念之一。神经网络将输入状态映射到(动作,Q 值)对。在本篇文章中将通过游戏的示例来介绍 Deep Q-Networks 的整个概念



