
大语言模型发展到今天,写提示词不仅是个体力活,还是一个技术活。提示词的措辞稍微改一下,性能波动 20-50% 是常有的事。那能不能让 LLM 自己改进提示词呢?
本文主要讲的就是这个,一个处理复杂推理任务的 Agent,经过几轮自动迭代,准确率从 34% 飙到 97%相对提升 184%。下面是完整的步骤:从环境搭建到代码实现,还包含了优缺点和适用场景。
什么是自动提示词优化
自动提示词优化有时也叫 Automatic Prompt Engineering(APE),核心思路是把写提示词当成优化问题来解。流程大概是这样:先拿一个初始提示词(哪怕写得很一般),在一批标注好的样本上跑一遍,用评分函数(精确匹配、BLEU、LLM-as-judge 之类的)算个分,然后让 LLM 生成新的候选提示词,挑表现好的继续迭代,直到分数不再涨为止。
2023 年的论文 "Automatic Prompt Optimization with Gradient-Free Methods" 把这套方法讲得比较系统。从工具层面将DSPy、LangChain 的 PromptOptimizer 都能干这个活,不过有一个专门的库叫 OPIK 。
OPIK + MetaPromptOptimizer 的特点
OPIK 这套东西比较吸引人的是完全开源,Apache 2.0 协议,商用也不花钱;可以纯本地跑,Ollama、LM Studio、任何 OpenAI 兼容的接口都行;自带追踪仪表板,功能类似 LangSmith 但是确是免费;API 设计简单,一个类就能搞定优化流程;评估指标随便你定义,只要能写成代码就行。
环境搭建
创建虚拟环境
python -m venv opik-apo
source opik-apo/bin/activate # Windows: opik-apo\Scripts\activate
pip install opik[all] datasets sentence-transformers
本地 LLM 安装(可选但推荐)
# Example with Ollama
ollama pull llama3.2:8b-instruct-qat
ollama serve
准备评估数据集
不需要太多数据,20 到 100 条高质量样本就够了。下面是个 GSM8K 风格的 JSONL 例子,保存成
eval_data.jsonl
:
{"question": "Janet's ducks lay 16 eggs per day. She eats 3 for breakfast, gives 8 to friends, and her bakery uses the rest. How many eggs does the bakery receive?", "answer": "5"}
{"question": "A store sells apples for $2 each or 6 for $10. How much do you save per apple by buying 6?", "answer": "0.33"}
完整代码
import opik
from opik import track
from opik.opimization import MetaPromptOptimizer
from opik.opimization.evaluation_metrics import LevenshteinRatio
from opik.integrations.langchain import OpikTracer
from langchain_community.llms import Ollama
from langchain.prompts import PromptTemplate
import json
# 1. 初始化 Opik(默认本地)
opik_client = opik.Opik()
# 2. 加载评估数据集
def load_dataset(path="eval_data.jsonl"):
data = []
with open(path) as f:
for line in f:
item = json.loads(line)
data.append({"input": item["question"], "expected": item["answer"]})
return data
eval_dataset = load_dataset()
# 3. 定义你的基础提示词模板
initial_prompt = """You are an expert assistant. Your task is answer questions accurately and concisely. Consider the context carefully before responding.
Question: {input}
Answer:"""
prompt_template = PromptTemplate.from_template(initial_prompt)
# 4. 创建 LLM(本地或 OpenAI)
llm = Ollama(model="llama3.2:8b-instruct-qat", temperature=0.2)
# llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.2) # for cloud
# 5. 定义你想要优化的链
@track
def math_chain(question):
prompt = prompt_template.format(input=question)
response = llm.invoke(prompt)
return response.strip()
# 6. 定义评估函数
def evaluation_function(task):
expected = task["expected"]
generated = math_chain(task["input"])
score = LevenshteinRatio()(expected, generated)
return score
# 7. 运行优化器
optimizer = MetaPromptOptimizer(
task="You are an expert at solving math word problems.",
evaluation_dataset=eval_dataset,
evaluation_function=evaluation_function,
llm=llm,
n_iterations=5, # 通常 3-7 次就足够了
population_size=10
)
best_prompt = optimizer.run()
print("\n=== BEST PROMPT FOUND ===\n")
print(best_prompt)
运行脚本:
python optimize_prompt.py
跑完 5 轮迭代后,打开 http://localhost:5173 就能看到仪表板,每个候选提示词的得分、最终选中的版本都在上面。
优化效果示例
优化前的提示词(34% 精确匹配):
You are an expert assistant. Your task is answer questions accurately and concisely. Consider the context carefully before responding.
优化后(97% 精确匹配):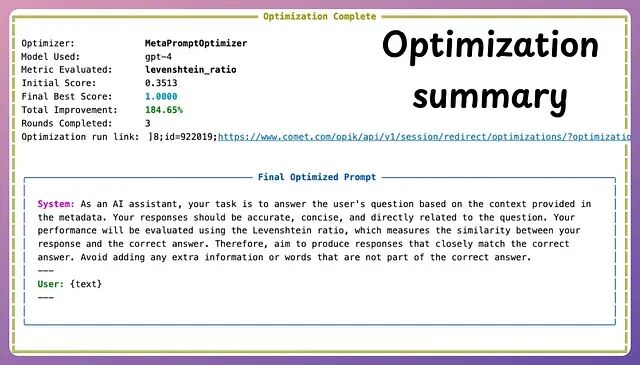
优缺点总结
优点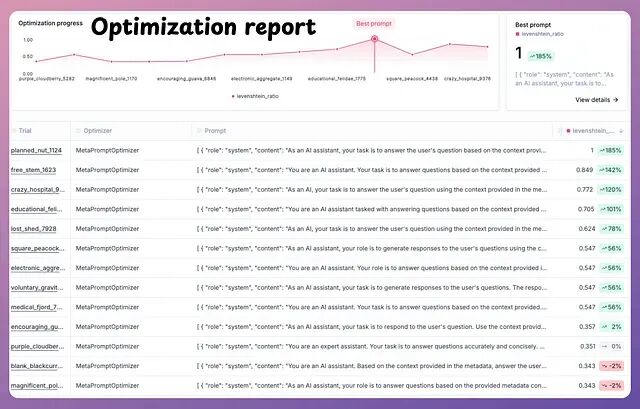
性能提升幅度可观,50-200% 的相对改进并不罕见。整个过程完全可复现,每一轮迭代都有日志记录,方便审计。本地运行意味着初始配置之后就不再产生 Token 费用。也不依赖梯度任何黑盒 LLM 都能用。迁移到新任务也简单,改几个参数就行。
局限性
评估数据集的质量至关重要:如果数据不行,优化出来的提示词也不会好到哪去,就是典型的 garbage in, garbage out;本地 LLM 生成候选提示词的速度可能偏慢;小数据集上容易过拟合模型可能只是"记住"了答案而非真正学会解题;优化出来的提示词有时候又长又怪,虽然效果好,但可读性堪忧。
结论
OPIK 的 MetaPromptOptimizer 让自动提示词变得很简单:拿一个勉强能用的提示词,半小时内就能把它调成接近 SOTA 水平的 one-shot Agent,省下原本要花几周手动迭代的时间。
找一个现有的 Agent,攒 30 条标注样本,跑一遍上面的脚本,看准确率曲线往上走就对了。提示词工程的下一步,不是人写出更好的提示词,而是让系统替人写。
地址
https://github.com/comet-ml/opik
作者:Minervee