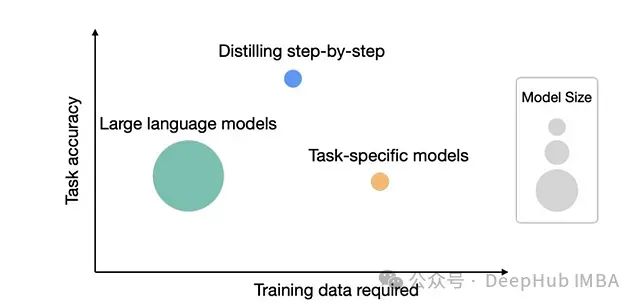
知识蒸馏方法探究:Google Distilling Step-by-Step 论文深度分析
Google Research 团队发表的论文《Distilling Step-by-Step!》提出了一种创新的知识蒸馏方法,不仅能有效减小模型规模,还能使学生模型在某些任务上超越其教师模型。
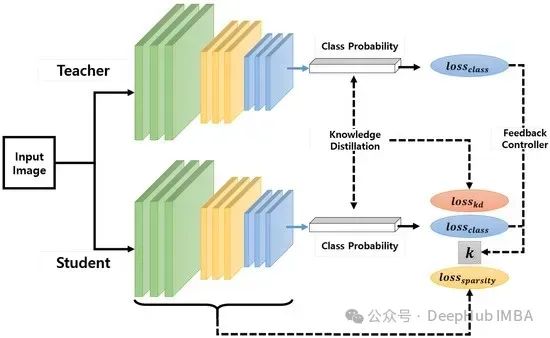
知识蒸馏技术原理详解:从软标签到模型压缩的实现机制
**知识蒸馏**是一种通过性能与模型规模的权衡来实现模型压缩的技术。其核心思想是将较大规模模型(称为教师模型)中的知识迁移到规模较小的模型(称为学生模型)中。本文将深入探讨知识迁移的具体实现机制。

分布匹配蒸馏:扩散模型的单步生成优化方法研究
分布匹配蒸馏(Distribution Matching Distillation,DMD)通过将多步扩散过程精简为单步生成器来解决这一问题。该方法结合分布匹配损失函数和对抗生成网络损失,实现从噪声图像到真实图像的高效映射,为快速图像生成应用提供了新的技术路径。
大模型蒸馏:高效AI的秘诀
模型蒸馏是一种模型压缩技术,它借鉴了教育领域中的“知识传递”概念,将一个大型且复杂的模型(教师模型)的知识“传授”给一个小型且简单的模型(学生模型)。这种方法不仅减少了模型的计算和存储需求,而且使得模型更加易于部署,尤其适合资源受限的环境。
知识蒸馏Matching logits与RocketQAv2
很多时候你与其说直接用一个数据集去训练一个模型,你还不如用这个数据集先训练一个大a模型比a模型要大的模型。再让大a模型去教会a模型去做,有可能效果就更好。就是因为大a模型这个teacher model可以生成soft label相比于原始数据的hard label,可以包含更多的信息量,从而就天然的
yolov8知识蒸馏代码详解:支持logit和feature-based蒸馏
特别地,在COCO数据集上对MAP中的RetinaNet检测器(resnet50主干)获得了3.4%的性能提升,在Cityscapes数据集上, 针对mIoU指标,PSPNET(resnet-18 backbone)获得5.81%的性能提升。大部分的KD方法都是通过algin学生网络和教师网络的归一

使用PyTorch进行知识蒸馏的代码示例
在本文中,我们将探索知识蒸馏的概念,以及如何在PyTorch中实现它。

使用DistilBERT 蒸馏类 BERT 模型的代码实现
在本篇文章中我们将使用DistilBERT 蒸馏类 BERT 模型,并给出完整的代码实现。
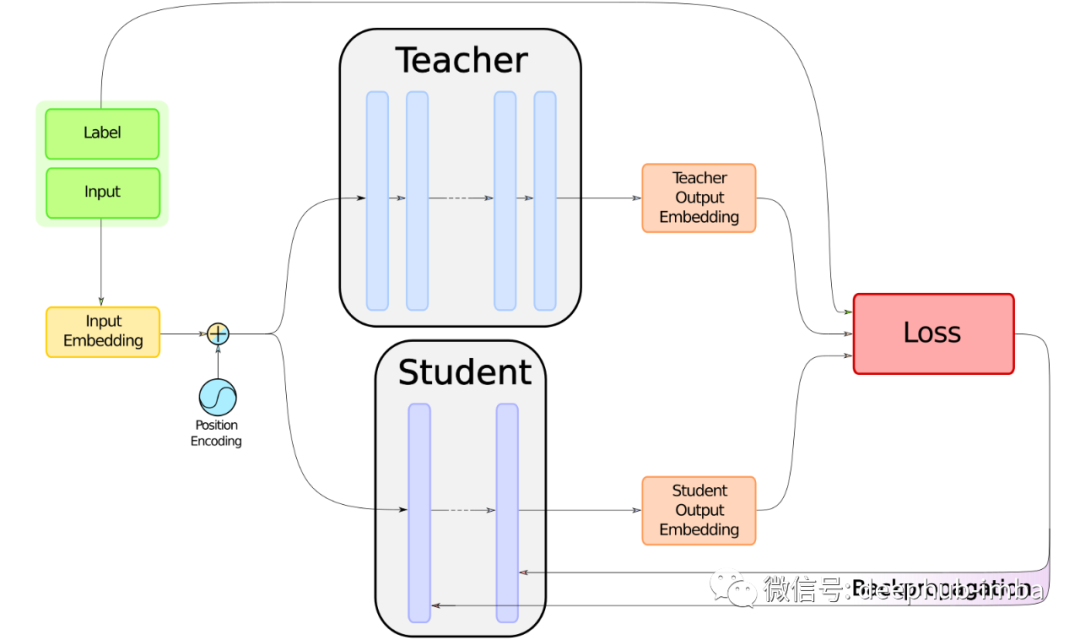
BERT 模型的知识蒸馏: DistilBERT 方法的理论和机制研究
在本文中,我们将探讨 DistilBERT [1] 方法背后的机制,该方法可用于提取任何类似 BERT 的模型。



