
FAISS 在实验阶段确实好用,速度快、上手容易,notebook 里跑起来很顺手。但把它搬到生产环境还是有很多问题:
首先是元数据的问题,FAISS 索引只认向量,如果想按日期或其他条件筛选还需要自己另外搞一套查找系统。
其次它本质上是个库而不是服务,让如果想对外提供接口还得自己用 Flask 或 FastAPI 包一层。
最后最麻烦的是持久化,pod 一旦挂掉索引就没了,除非提前手动存盘。
Qdrant 的出现解决了这些痛点,它更像是个真正的数据库,提供开箱即用的 API、数据重启后依然在、原生支持元数据过滤。更关键的是混合搜索(Dense + Sparse)和量化这些高级功能都是内置的。
MS MARCO Passages 数据集
数据集地址:
MS MARCO 官方页面:https://microsoft.github.io/msmarco/
这次用的是 MS MARCO Passage Ranking 数据集,信息检索领域的标准测试集。
数据是从网页抓取的约880万条短文本段落,选它的原因很简单:段落短(平均50词),不用处理复杂的文本分块,可以把精力放在迁移工程本身。
实际测试时用了10万条数据的子集,这样速度会很快
嵌入模型用的是 sentence-transformers/all-MiniLM-L6-v2,输出384维的稠密向量。
SentenceTransformers 模型地址:https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
FAISS 阶段的初始配置
生成嵌入向量
加载原始数据,批量生成嵌入向量。这里关键的一步是把结果存成 .npy 文件,避免后续重复计算。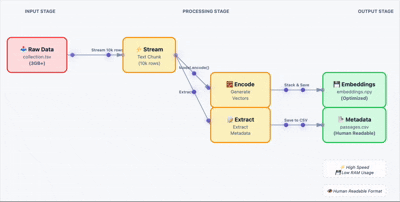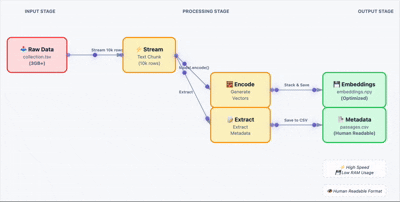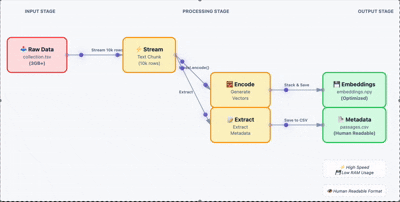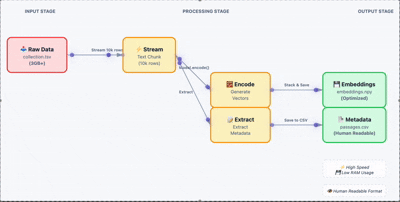
import pandas as pd
from sentence_transformers import SentenceTransformer
import numpy as np
import os
import csv
DATA_PATH = '../data'
TSV_FILE = f'{DATA_PATH}/collection.tsv'
SAMPLE_SIZE = 100000
MODEL_ID = 'all-MiniLM-L6-v2'
def prepare_data():
print(f"Loading Model '{MODEL_ID}'...")
model = SentenceTransformer(MODEL_ID)
print(f"Reading first {SAMPLE_SIZE} lines from {TSV_FILE}...")
ids = []
passages = []
# Efficiently read line-by-line without loading entire 8GB file to RAM
try:
with open(TSV_FILE, 'r', encoding='utf8') as f:
reader = csv.reader(f, delimiter='\t')
for i, row in enumerate(reader):
if i >= SAMPLE_SIZE:
break
# MS MARCO format is: [pid, text]
if len(row) >= 2:
ids.append(int(row[0]))
passages.append(row[1])
except FileNotFoundError:
print(f"Error: Could not find {TSV_FILE}")
return
print(f"Loaded {len(passages)} passages.")
# Save text metadata (for Qdrant payload)
print("Saving metadata to CSV...")
df = pd.DataFrame({'id': ids, 'text': passages})
df.to_csv(f'{DATA_PATH}/passages.csv', index=False)
# Generate Embeddings
print("Encoding Embeddings (this may take a moment)...")
embeddings = model.encode(passages, show_progress_bar=True)
# Save binary files (for FAISS and Qdrant)
print("5. Saving numpy arrays...")
np.save(f'{DATA_PATH}/embeddings.npy', embeddings)
np.save(f'{DATA_PATH}/ids.npy', np.array(ids))
print(f"Success! Saved {embeddings.shape} embeddings to {DATA_PATH}")
if __name__ == "__main__":
os.makedirs(DATA_PATH, exist_ok=True)
prepare_data()
构建索引
用 IndexFlatL2 做精确搜索,对于百万级别的数据量来说足够了。
import faiss
import numpy as np
import os
DATA_PATH = '../data'
INDEX_OUTPUT_PATH = './my_index.faiss'
def build_index():
print("Loading embeddings...")
# Load the vectors
if not os.path.exists(f'{DATA_PATH}/embeddings.npy'):
print(f"Error: {DATA_PATH}/embeddings.npy not found.")
return
embeddings = np.load(f'{DATA_PATH}/embeddings.npy')
d = embeddings.shape[1] # Dimension (should be 384 for MiniLM)
print(f"Building Index (Dimension={d})...")
# We use IndexFlatL2 for exact search (Simple & Accurate for <1M vectors).
index = faiss.IndexFlatL2(d)
index.add(embeddings)
print(f"Saving index to {INDEX_OUTPUT_PATH}..")
faiss.write_index(index, INDEX_OUTPUT_PATH)
print(f"Success! Index contains {index.ntotal} vectors.")
if __name__ == "__main__":
os.makedirs(os.path.dirname(INDEX_OUTPUT_PATH), exist_ok=True)
build_index()
语义搜索测试
随便跑一个查询就能看出问题了。返回的是 [42, 105] 这种 ID,如果想拿到实际文本还得写一堆代码去 CSV 里查,这种割裂感是迁移的主要原因。
import faiss
import numpy as np
import pandas as pd
from sentence_transformers import SentenceTransformer
INDEX_PATH = './my_index.faiss'
DATA_PATH = '../data'
MODEL_NAME = 'all-MiniLM-L6-v2'
def search_faiss():
print("Loading Index and Metadata...")
index = faiss.read_index(INDEX_PATH)
# LIMITATION: We must manually load the CSV to get text back.
# FAISS only stores vectors, not the text itself.
df = pd.read_csv(f'{DATA_PATH}/passages.csv')
model = SentenceTransformer(MODEL_NAME)
# userquery
query_text = "What is the capital of France?"
print(f"\nQuery: '{query_text}'")
# Encode and Search
query_vector = model.encode([query_text])
D, I = index.search(query_vector, k=3) # Search for top 3 results
print("\n--- Results ---")
for rank, idx in enumerate(I[0]):
# LIMITATION: If we wanted to filter by "text_length > 50",
# we would have to fetch ALL results first, then filter in Python.
# FAISS cannot filter during search.
text = df.iloc[idx]['text'] # Manual lookup
score = D[0][rank]
print(f"[{rank+1}] ID: {idx} | Score: {score:.4f}")
print(f" Text: {text[:100]}...")
if __name__ == "__main__":
search_faiss()
迁移步骤
从 FAISS 导出向量
前面步骤已经有 embeddings.npy 了,直接加载 numpy 数组就行,省去了导出环节。
本地启动 Qdrant 很简单:
docker run -p6333:6333 qdrant/qdrant
Collection 配置文档:https://qdrant.tech/documentation/concepts/collections/
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance, HnswConfigDiff
QDRANT_URL = "http://localhost:6333"
COLLECTION_NAME = "ms_marco_passages"
def create_collection():
client = QdrantClient(url=QDRANT_URL)
print(f"Creating collection '{COLLECTION_NAME}'...")
client.recreate_collection(
collection_name=COLLECTION_NAME,
vectors_config=VectorParams(
size=384,# Dimension (MiniLM)- we should follow the existing dimension from FAISS
distance=Distance.COSINE
),
hnsw_config=HnswConfigDiff(
m=16, # Links per node (default is 16)
ef_construct=100 # Search depth during build (default is 100)
)
)
print(f"Collection '{COLLECTION_NAME}' created with HNSW config.")
if __name__ == "__main__":
create_collection()
批量上传数据
Qdrant Python 客户端文档:https://qdrant.tech/documentation/clients/python/
import pandas as pd
import numpy as np
from qdrant_client import QdrantClient
from qdrant_client.models import PointStruct
QDRANT_URL = "http://localhost:6333"
COLLECTION_NAME = "ms_marco_passages"
DATA_PATH = '../data'
BATCH_SIZE = 500
def upload_data():
client = QdrantClient(url=QDRANT_URL)
print("Loading local data...")
embeddings = np.load(f'{DATA_PATH}/embeddings.npy')
df_meta = pd.read_csv(f'{DATA_PATH}/passages.csv')
total = len(df_meta)
print(f"Starting upload of {total} vectors...")
points_batch = []
for i, row in df_meta.iterrows():
# Metadata to attach
payload = {
"passage_id": int(row['id']),
"text": row['text'],
"text_length": len(str(row['text'])),
"dataset_source": "msmarco_passages"
}
points_batch.append(PointStruct(
id=int(row['id']),
vector=embeddings[i].tolist(),
payload=payload
))
# Upload batch
if len(points_batch) >= BATCH_SIZE or i == total - 1:
client.upsert(
collection_name=COLLECTION_NAME,
points=points_batch
)
points_batch = []
if i % 1000 == 0:
print(f" Processed {i}/{total}...")
print("Upload Complete.")
if __name__ == "__main__":
upload_data()
验证迁移结果
from qdrant_client import QdrantClient
from qdrant_client.models import Filter, FieldCondition, Range, MatchValue
from sentence_transformers import SentenceTransformer
QDRANT_URL = "http://localhost:6333"
COLLECTION_NAME = "ms_marco_passages"
MODEL_NAME = 'all-MiniLM-L6-v2'
def validate_migration():
client = QdrantClient(url=QDRANT_URL)
model = SentenceTransformer(MODEL_NAME)
# Verify total count
count_result = client.count(COLLECTION_NAME)
print(f"Total Vectors in Qdrant: {count_result.count}")
# Query example
query_text = "What is a GPU?"
print(f"\n--- Query: '{query_text}' ---")
query_vector = model.encode(query_text).tolist()
# Filter Definition
print("Applying filters (Length < 200 AND Source == msmarco)...")
search_filter = Filter(
must=[
FieldCondition(
key="text_length",
range=Range(lt=200) # can be changed as per the requirement
),
FieldCondition(
key="dataset_source",
match=MatchValue(value="msmarco_passages")
)
]
)
results = client.query_points(
collection_name=COLLECTION_NAME,
query=query_vector,
query_filter=search_filter,
limit=3
).points
for hit in results:
print(f"\nID: {hit.id} (Score: {hit.score:.3f})")
print(f"Text: {hit.payload['text']}")
print(f"Metadata: {hit.payload}")
if __name__ == "__main__":
validate_migration()
性能对比
针对10个常见查询做了对比测试。
FAISS(本地 CPU):约 0.5ms,纯数学计算的速度
Qdrant(Docker):约 3ms,包含了网络传输的开销
对 Web 服务来说3ms 的延迟完全可以接受,何况换来的是一堆新功能。
import time
import faiss
import numpy as np
from qdrant_client import QdrantClient
from sentence_transformers import SentenceTransformer
FAISS_INDEX_PATH = './faiss_index/my_index.faiss'
QDRANT_URL = "http://localhost:6333"
COLLECTION_NAME = "ms_marco_passages"
MODEL_NAME = 'all-MiniLM-L6-v2'
QUERIES = [
"What is a GPU?",
"Who is the president of France?",
"How to bake a cake?",
"Symptoms of the flu",
"Python programming language",
"Best places to visit in Italy",
"Define quantum mechanics",
"History of the Roman Empire",
"What is machine learning?",
"Healthy breakfast ideas"
]
def run_comparison():
print("---Loading Resources ---")
# Load Model
model = SentenceTransformer(MODEL_NAME)
# Load FAISS (The "Old Way")
print("Loading FAISS index...")
faiss_index = faiss.read_index(FAISS_INDEX_PATH)
# Connect to Qdrant (The "New Way")
print("Connecting to Qdrant...")
client = QdrantClient(url=QDRANT_URL)
print(f"\n---Running Race ({len(QUERIES)} queries) ---")
print(f"{'Query':<30} | {'FAISS (ms)':<10} | {'Qdrant (ms)':<10}")
print("-" * 60)
faiss_times = []
qdrant_times = []
for query_text in QUERIES:
# Encode once
query_vector = model.encode(query_text).tolist()
# --- MEASURE FAISS ---
start_f = time.perf_counter()
# FAISS expects a numpy array of shape (1, d)
faiss_input = np.array([query_vector], dtype='float32')
_, _ = faiss_index.search(faiss_input, k=3)
end_f = time.perf_counter()
faiss_ms = (end_f - start_f) * 1000
faiss_times.append(faiss_ms)
# --- MEASURE QDRANT ---
start_q = time.perf_counter()
_ = client.query_points(
collection_name=COLLECTION_NAME,
query=query_vector,
limit=3
)
end_q = time.perf_counter()
qdrant_ms = (end_q - start_q) * 1000
qdrant_times.append(qdrant_ms)
print(f"{query_text[:30]:<30} | {faiss_ms:>10.2f} | {qdrant_ms:>10.2f}")
print("-" * 60)
print(f"{'AVERAGE':<30} | {np.mean(faiss_times):>10.2f} | {np.mean(qdrant_times):>10.2f}")
if __name__ == "__main__":
run_comparison()
测试结果: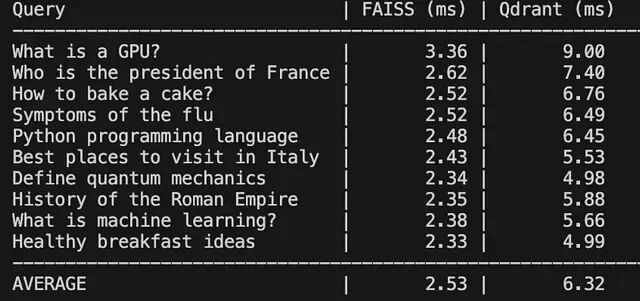
最大的差异不在速度,在于省心。
用 FAISS 时有次跑了个索引脚本处理大批数据,耗时40分钟,占了12GB内存。快完成时 SSH 连接突然断了,进程被杀,因为 FAISS 只是个跑在内存里的库一切都白费了。
换成 Qdrant 就不一样了:它像真正的数据库,数据推送后会持久化保存,即便突然断开 docker 连接重启后数据还在。
用过 FAISS 就知道为了把向量 ID 映射回文本,还需要额外维护一个 CSV 文件。迁移到 Qdrant 后这些查找逻辑都删掉了,文本和向量存在一起,直接查询 API 就能拿到完整结果,不再需要管理各种文件,就是在用一个微服务。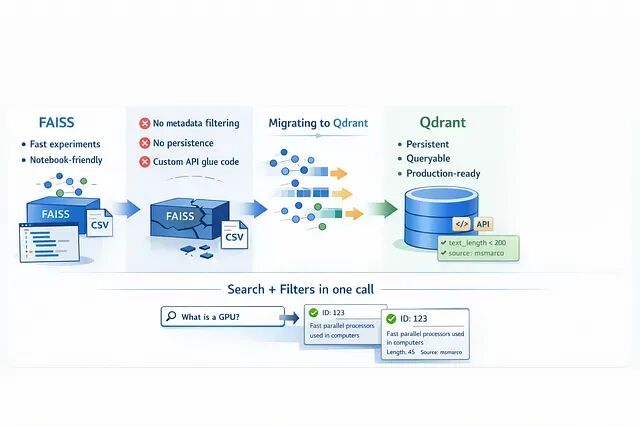
迁移总结
这次迁移断断续续做了一周但收获很大。最爽的不是写 Qdrant 脚本,是删掉旧代码——提交的 PR 几乎全是红色删除行。CSV 加载工具、手动 ID 映射、各种"代码"全删了,代码量减少了30%,可读性明显提升。
只用 FAISS 时,搜索有时像在碰运气——语义上相似但事实错误的结果时常出现。迁移到 Qdrant拿到的不只是数据库,更是对系统的掌控力。稠密向量配合关键词过滤(混合搜索),终于能回答"显示 GPU 相关的技术文档,但只要官方手册里的"这种精确查询,这在之前根本做不到。
信心的变化最明显,以前不敢加载完整的880万数据怕内存撑不住。现在架构解耦了可以把全部数据推给 Qdrant,它会在磁盘上处理存储和索引,应用层保持轻量。终于有了个在生产环境和 notebook 里都能跑得一样好的系统。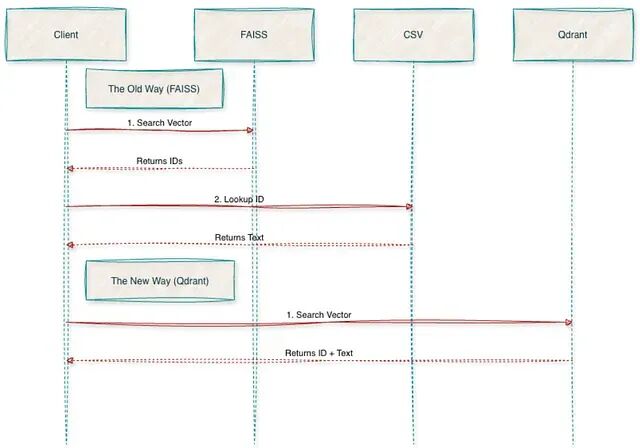
总结
FAISS 适合离线研究和快速实验,但要在生产环境跑起来Qdrant 提供了必需的基础设施。如果还在用额外的 CSV 文件来理解向量含义该考虑迁移了。
作者:Sai Bhargav Rallapalli