
ChatGPT 能写代码,但要它研究问题、编写实现、审查自身代码中的 bug、编写测试、修复失败的用例并撰写文档,并且在一次交互内做完全部环节,可靠性远远不够。Cognition(Devin)、Factory AI、Microsoft(AutoGen)这种框架可以构建多智能体系统,让多个专门的 AI 智能体像人类工程团队一样分工协作。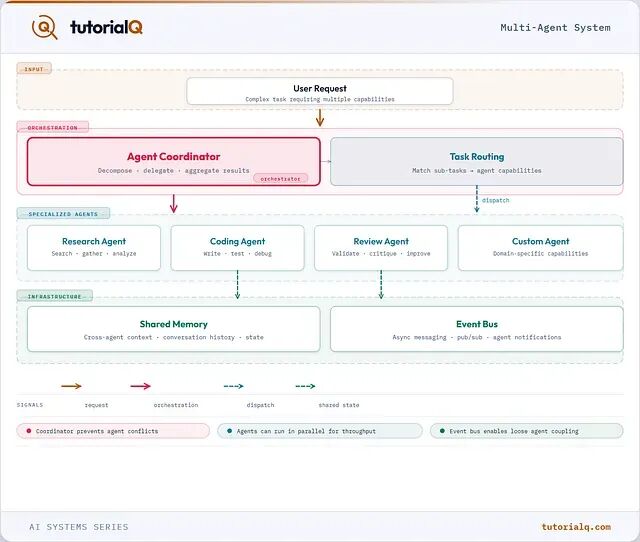
TL;DR:多智能体系统将复杂任务分配给各自拥有独立角色、工具和评估标准的专门智能体。编排层——即智能体之间如何协调——对系统整体效果的影响远大于单个智能体的质量。建议从两个智能体起步,加入交叉验证,在模式验证有效之后再考虑扩展。
复杂任务会让单个智能体不堪重负。当同一个智能体试图同时扮演研究者、编码者、审查者和测试者角色,专注力必然分散,上下文窗口被无关信息污染,推理质量下滑,错误层层叠加。每种角色对专业知识、上下文信息和评估标准的要求截然不同。
多智能体系统模拟的正是人类团队的运作方式:角色专门化、交接有序、彼此交叉检查。
多智能体系统如何工作
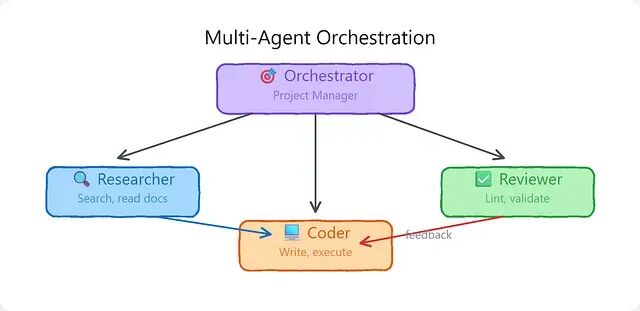
智能体角色化
每个智能体针对特定角色做了优化,拥有专属的系统提示词、工具集和评估标准:
agents = {
"researcher": Agent(
role="Research and gather information",
tools=["web_search", "document_reader"],
model="gpt-4o",
),
"coder": Agent(
role="Write and debug code",
tools=["code_executor", "file_writer"],
model="gpt-4o",
),
"reviewer": Agent(
role="Review code for bugs and improvements",
tools=["code_reader", "linter"],
model="gpt-4o",
),
}
专门化智能体的表现持续优于通用智能体,这样上下文中噪音更少,提示词聚焦在单一能力上。
编排层
编排器——通常也是一个智能体——承担协调职责,核心工作包括四项:任务分解,即把复杂任务拆分为输入输出明确的子任务;依赖图构建,判断哪些子任务可以并行、哪些必须串行;路由分发,将子任务匹配给合适的专门智能体;冲突裁决,当智能体之间出现分歧时做出裁定或升级处理。
一个真实的编排器循环如下:
async def orchestrate(task: str, agents: dict, max_rounds: int = 10):
"""核心编排循环 — 分解、委派、验证、重复。"""
plan = await agents["planner"].run(
f"Break this into subtasks with dependencies: {task}"
)
# plan = [{"id": 1, "agent": "researcher", "input": "...", "depends_on": []},
# {"id": 2, "agent": "coder", "input": "...", "depends_on": [1]}, ...]
results = {} # task_id -> output
for round in range(max_rounds):
# 找到所有依赖都已满足的任务
ready = [t for t in plan if t["id"] not in results
and all(d in results for d in t["depends_on"])]
if not ready:
break # 所有任务完成
# 并行运行独立任务
parallel_results = await asyncio.gather(*[
agents[t["agent"]].run(
t["input"],
context={did: results[did] for did in t["depends_on"]}
)
for t in ready
])
for task_spec, result in zip(ready, parallel_results):
# 在接受之前验证输出
validation = await agents["reviewer"].run(
f"Validate this output for task '{task_spec['input']}': {result}"
)
if validation.approved:
results[task_spec["id"]] = result
else:
# 带反馈重新运行 — 智能体会收到审查者的批评意见
plan.append({
"id": task_spec["id"],
"agent": task_spec["agent"],
"input": f"{task_spec['input']}\nFeedback: {validation.reason}",
"depends_on": task_spec["depends_on"],
})
return results
编排器本身不做具体工作,它管理的是依赖图和验证循环。注意看验证未通过时发生了什么:任务带着审查反馈重新入队,形成自我纠正的闭环。计划 → 执行 → 验证 → 重试——这一模式是所有在生产环境中稳定运行的多智能体系统的共同骨架。
通信协议
智能体之间需要结构化的信息交换方式。协议的选择直接影响三件事:智能体之间的耦合程度、故障调试的难度,以及系统在 3-4 个智能体之后还能否继续扩展。
常见的协议有四种——消息传递(延迟中等、耦合松散,适合异步和事件驱动的工作流);共享内存(延迟低、耦合紧密,适合快速迭代的小型团队);黑板模式(延迟中等、耦合适中,适合知识积累型场景);函数调用(延迟低、耦合紧密,适合直接委派)。
生产环境中用得最多的是消息传递。每个智能体发送遵循固定 schema 的结构化消息:
@dataclass
class AgentMessage:
sender: str # "researcher"
recipient: str # "coder" or "orchestrator"
msg_type: str # "result", "error", "clarification_needed"
content: dict # 实际的有效载荷
parent_task_id: str # 链接回编排器的计划
timestamp: float
# 研究者将发现发送给编排器
msg = AgentMessage(
sender="researcher",
recipient="orchestrator",
msg_type="result",
content={
"findings": "Redis supports sorted sets for leaderboards...",
"confidence": 0.92,
"sources": ["redis.io/docs/data-types/sorted-sets/"],
},
parent_task_id="task-001",
timestamp=time.time(),
)
共享内存(也叫"草稿本")更适合紧密迭代的场景——把它想象成一个共享的 Google Doc,智能体可以实时看到彼此的工作。AutoGen 和 CrewAI 都支持这种模式。代价是隐式耦合:任何智能体随时都能修改共享状态,出了问题很难追溯。
黑板架构则是一种混合方案:中央知识存储供智能体读写,但谁能更新哪个部分有明确的结构化规则。MetaGPT 的 SOP 驱动方法就是这个思路——研究者写入"研究"区域,编码者从中读取后写入"代码"区域,审查者同时读取两个区域。
共识与验证
交叉验证是多智能体系统中最有价值的模式之一:让多个智能体相互检查彼此的输出。具体形式有三种:辩论,即两个智能体就对立立场展开论证,由裁判智能体裁决;投票,即多个智能体独立求解同一问题,取多数答案;层级审查,即高级智能体对初级智能体的输出进行审批。
相比单个智能体独立工作,交叉验证对错误率的抑制效果非常明显。
状态管理
跨多个智能体追踪整体状态是运维层面最棘手的挑战。需要弄清楚哪个智能体在什么时间做了什么、为什么这样做,还要处理智能体之间产出相互矛盾或某个智能体半途失败的情况。
下面是一个实用的状态管理器实现,覆盖了并发控制、冲突检测和回滚这三个核心问题:
class AgentStateManager:
def __init__(self):
self.state = {} # 当前共享状态
self.history = [] # 所有更改的仅追加日志
self.locks = {} # 按键的写入安全锁
async def update(self, agent_id: str, key: str, value: any):
"""使用乐观锁写入共享状态。"""
async with self.locks.setdefault(key, asyncio.Lock()):
old_value = self.state.get(key)
self.history.append({
"agent": agent_id,
"key": key,
"old": old_value,
"new": value,
"timestamp": time.time(),
})
self.state[key] = value
def rollback_agent(self, agent_id: str):
"""撤销特定智能体的所有更改(按逆序)。"""
agent_changes = [h for h in self.history if h["agent"] == agent_id]
for change in reversed(agent_changes):
self.state[change["key"]] = change["old"]
self.history.remove(change)
def get_agent_contributions(self, agent_id: str) -> list:
"""审计追踪:该智能体更改了什么以及何时更改的?"""
return [h for h in self.history if h["agent"] == agent_id]
状态管理做得好不好,取决于三件事。第一,历史记录必须是仅追加的——任何覆写操作都要留日志。出了问题(迟早会出)历史日志是回溯"哪个智能体产出了错误结果、它当时看到的状态是什么"的唯一手段。第二,回滚必须按智能体粒度执行。审查者驳回了编码者的输出,需要撤销编码者的状态变更而不影响研究者已有的贡献——历史记录中逐条追踪
agent_id
就是为此而设。第三,Token 预算必须有追踪和硬性上限。多智能体系统消耗 API 额度的速度惊人,一个失控的研究者智能体以每次 $0.01 的成本做无限网络搜索,跑 500 轮迭代下来费用相当可观。
何时使用多智能体系统
多智能体系统引入的复杂性是实实在在的。适用场景有几种:任务确实需要多种截然不同的能力;单个智能体的上下文窗口装不下所有必要信息;交叉验证能切实改善输出质量;子任务之间存在并行化空间。
单个智能体就能处理好的任务,没有必要多此一举。正确的做法是从一个智能体起步,定位它的失败点,只针对那些具体的职责做拆分。
生产环境中的 5 个隐藏陷阱
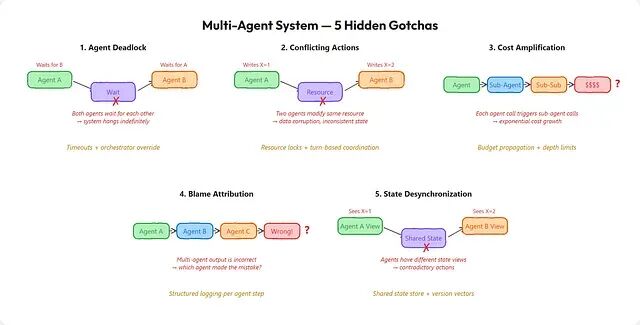
多智能体系统是新前沿,同时也是一个故障放大器——单智能体的每种失败模式都会乘以智能体数量。Andrew Ng 说过,智能体工作流是"AI 领域最重要的趋势";但从运维角度看,它们也是最复杂的。
1、智能体死锁
研究者智能体调用编码者:"根据我的研究实现方案。"编码者回调研究者:"实现之前需要更多细节。"两者陷入无限期互相等待,每条"等待"消息都在消耗 Token。这就是分布式系统中经典的死锁问题——区别在于每次 LLM 调用的成本不低于 0.01。两个 GPT-4 智能体之间持续 2 小时的死锁循环,Token 浪费约 50。
修复方法:对所有智能体间调用设置超时(30-60 秒)。编排器监控调用图并检测循环依赖。超时后由编排器强制解决——提供默认响应或升级给人类。关键原则:不允许智能体之间双边直接通信,所有交互都经由编排器路由。
2、冲突操作
研究者智能体编辑
report.md
添加研究发现,编码者同一时刻在编辑同一文件添加代码示例。双方都不知道对方的改动。最后写入的那个获胜导致另一个智能体的工作悄然丢失。本质上是经典的并发写入问题,但多了一层复杂性:智能体无法像人一样检测和解决合并冲突。
修复方法:引入资源级锁,同一时间只有一个智能体能持有某个文件的写锁,锁表由编排器管理。另一种思路是基于轮次的架构——智能体按固定顺序依次执行(研究 → 编码 → 审查),工件像接力赛一样逐环传递。共享资源适合用仅追加语义:智能体只向共享草稿本中追加内容,不编辑彼此已有的输出。
3、成本放大
编排器将一个任务路由到 3 个专家智能体,每个智能体发起 4 次工具调用(每次调用携带完整对话上下文),每次工具调用又触发一个子智能体做验证。一个用户请求的调用量:3 × 4 × 1 = 12 次 LLM 调用。按每次 5,000 个 Token 计算,单个请求消耗 60,000 个 Token。乘以日活 10,000 用户,数字就很吓人了。成本增长的方式不是随智能体数量线性递增,而是随委派深度乘法式膨胀。
修复方法:预算传播机制——编排器为每个请求分配 Token 总预算,每个智能体获得一个份额并必须在额度内运行。设置委派深度上限(建议不超过 2 层)。缓存工具调用结果以避免重复请求触发新的 LLM 调用。常规子任务用更低成本的模型处理(如 GPT-5-mini 做验证,GPT-5 做推理)。
4、 责任归属
多智能体系统产出了一份根因分析有误的 bug 报告。流程回溯:研究者采集日志 → 分析者锁定了错误的组件 → 编码者针对错误组件提出修复方案 → 审查者批准通过。错出在哪一环?如果没有结构化的按智能体日志,调试意味着逐条阅读 4 个智能体之间 50 多轮 LLM 交互记录。
修复方法:每个智能体的输入、推理过程、工具调用和输出都应记录为结构化事件,共享同一个
trace_id。采用 OpenTelemetry 风格的 span 模型:每个智能体调用是一个 span,span 之间存在父子关系。配合追踪查看器(Langfuse、Arize Phoenix 或 LangSmith)展示完整决策树。输出有误时,从最终结果沿决策树反向追溯,定位第一个偏离正轨的智能体。
5、状态不同步
智能体 A 在 10:00:01 读取配置文件;智能体 B 在 10:00:02 修改了配置文件;智能体 A 在 10:00:03 基于旧配置做出决策。A 的决策从它"看到"的信息来判断逻辑上没有问题,但依据的是过期状态所以结果是相互矛盾的操作:A 按功能 X 已禁用的方式行动,B 按功能 X 已启用的方式行动。
修复方法:共享状态存储配合版本向量。每个智能体在执行操作前读取最新的状态版本号;如果版本号在上次读取之后发生了变化,必须重新读取并重新规划。使用黑板模式——所有智能体对同一个中央状态存储做读写,附加乐观并发控制。编排器在真正执行操作前,验证智能体的行为与当前状态是否一致。
常见设计阶段错误
以上陷阱出现在智能体运行时的交互过程中。而接下来要说的几类错误发生得更早——在架构设计阶段,一行智能体调用代码都还没写的时候。它们决定了系统最终能否扩展,还是在自身的复杂性下坍塌。
使用太多智能体
团队还没验证 2 个智能体是否优于 1 个,就设计出了 6 个智能体的编排管道。每多一个智能体就多一份延迟(串行 LLM 调用)、多一份开销(更多 Token),调试时需要追踪的交互也多一层。正确做法是从单个智能体开始,仅在有数据(不是直觉)证明任务分解确实改善了输出质量之后才加入第二个,而且要先跑评估套件验证。
缺乏共享上下文管理
智能体 A 研究一个主题,产出了研究结论。智能体 B 随后开始编码——但因为不存在共享工作区,B 看不到 A 的发现,只能重新研究同一主题,Token 和时间都白白浪费。解决方案并不复杂:设计一个所有智能体都能读写的共享草稿本或上下文存储,让每个智能体的产出对其余智能体即时可见。
缺少失控成本的熔断机制
一个多智能体管道处理用户请求时,智能体 B 因推理循环调用了智能体 C 47 次。单次请求的总成本:$8。如果没有每请求成本上限,问题只会在月底账单上才暴露。应当设置硬性支出限额——按请求(
max_tokens_per_request
)、按用户(
daily_budget_per_user
)和按管道运行分别设定。达到上限时立即终止管道,返回降级响应。
只做单智能体评估,不做端到端评估
每个智能体各自通过了评估:研究者 90% 的概率找到相关信息,编码者 85% 的概率产出可运行代码,审查者捕获 80% 的缺陷。看起来都不错。但端到端的管道质量是 90% × 85% × 80% = 61.2%。各环节质量不会累加,而是乘法式衰减。所以必须建立端到端评估体系,以人类标注结果为基线衡量最终输出质量。
紧耦合的智能体接口
智能体 A 的输出格式做了一处小改动——多加了一个字段。智能体 B 解析失败,整条管道崩溃。应对办法是将智能体接口设计为显式契约(JSON Schema 或 Protocol Buffers),做版本控制,在 CI 中测试向后兼容性。智能体之间应该能独立部署——像微服务,而不是单体应用中的紧耦合模块。
多智能体框架选择
- LangGraph — 架构:基于图的工作流 | 核心优势:状态机的灵活性 | 成熟度:高
- AutoGen — 架构:对话式 | 核心优势:多轮智能体对话 | 成熟度:高
- CrewAI — 架构:基于角色的团队 | 核心优势:心智模型简单 | 成熟度:中
- MetaGPT — 架构:软件团队模拟 | 核心优势:SOP 驱动的协调 | 成熟度:中
- Swarm (OpenAI) — 架构:轻量级交接 | 核心优势:编排开销最小 | 成熟度:实验性/教育性
总结
多智能体系统的本质是把人类团队的分工逻辑移植到 AI 系统中——角色专门化、交接有序、产出交叉校验。单个智能体在复杂任务上的表现瓶颈并非模型能力不足,而是上下文窗口的承载极限和多角色切换带来的推理质量衰减。分拆角色、引入编排层,是目前最务实的应对路径。
编排层的设计水平对最终效果的影响远大于每个智能体本身的能力。依赖图调度、验证-重试循环、通信协议选型——这些架构决策在第一行代码之前就已经锁定了系统上限。落地阶段最棘手的工程问题集中在五个方向:死锁检测与超时、并发写入冲突、成本的乘法式膨胀、故障归因,以及跨智能体的状态一致性。每一个都需要在设计初期就考虑对策,事后补救的代价极高。
落地建议很直接:从两个角色明确的智能体起步,用评估数据(而非直觉)证明拆分带来了质量提升,再逐步扩展。交叉验证机制(辩论、投票、层级审查)值得优先引入——微软研究院的实验数据表明,多智能体讨论在推理基准测试上对准确率有可量化的改善。成本监控必须从第一天就到位,不加控制的多智能体管道可能让 LLM 支出翻 3-5 倍。
by Mahi Mullapudi