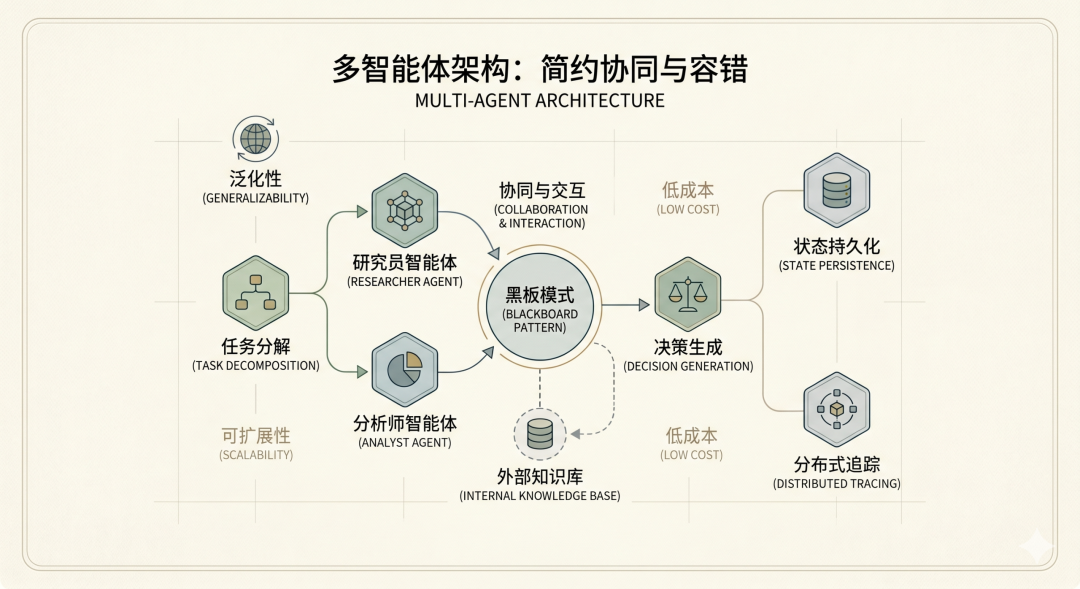
告别脆弱的单体应用,用多智能体网络构建稳定的生产力工具
本文深度解析了 AI 应用从单体大模型向多智能体(Multi-Agent)架构演进的技术趋势与工程实践。面对复杂业务,多智能体系统凭借角色分工与优雅降级展现出极强的泛化性
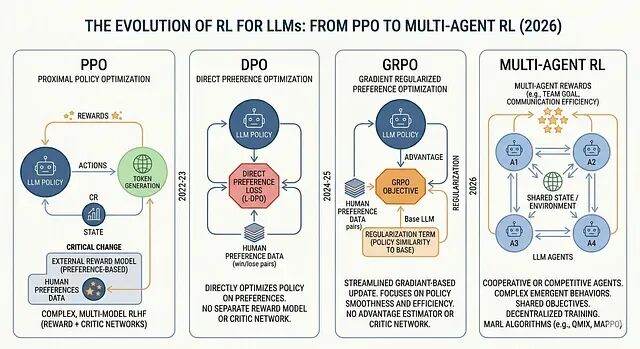
2026 年面向 LLM 的 RL方法总结:从 PPO 到 DPO 到 GRPO,再到多智能体 RL
本文是对当前格局的一次梳理。会用一点篇幅讲历史,更多篇幅留给 PPO、DPO、GRPO 和 MARL——它们是什么、各自适合什么场景、实际中会在哪里坏掉,以及今天的开源技术栈大概长什么样。
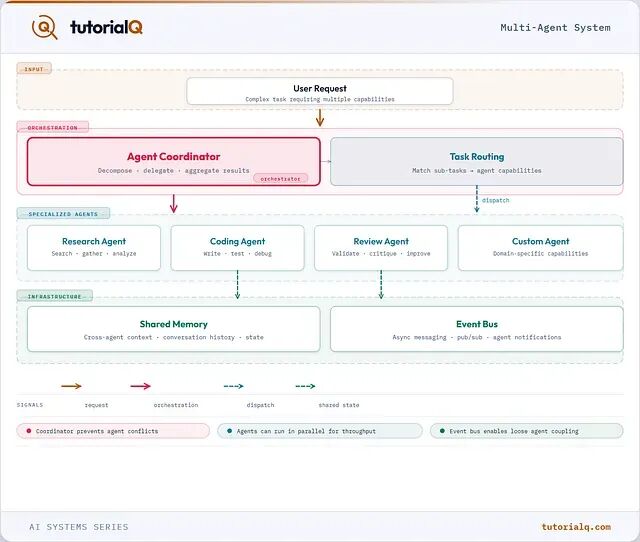
多智能体系统的核心设计:从任务分解到依赖图驱动的编排循环
多智能体系统将复杂任务分配给各自拥有独立角色、工具和评估标准的专门智能体。
软件工程原则在多智能体系统中的应用:分层与解耦
本文的出发点是想验证一件事:智能体系统到底能不能像其他严肃软件一样做架构。

多智能体强化学习(MARL)核心概念与算法概览
单智能体 RL 适合系统只有一个"大脑"的情况,而MARL 则出现在世界有多个"大脑"的时候。
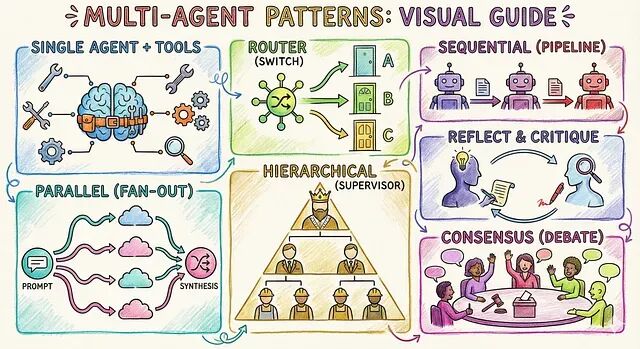
别再往一个智能体里塞功能了:6种多智能体模式技术解析与选型指南
这篇文章整理了 6 种经过验证的多智能体架构模式,可以有效的帮你解决问题。
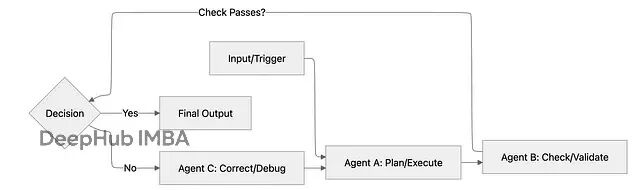
多智能体系统设计:5种编排模式解决复杂AI任务
我们这里分析5种主流的智能体编排模式,每种都有其适用场景和技术特点。
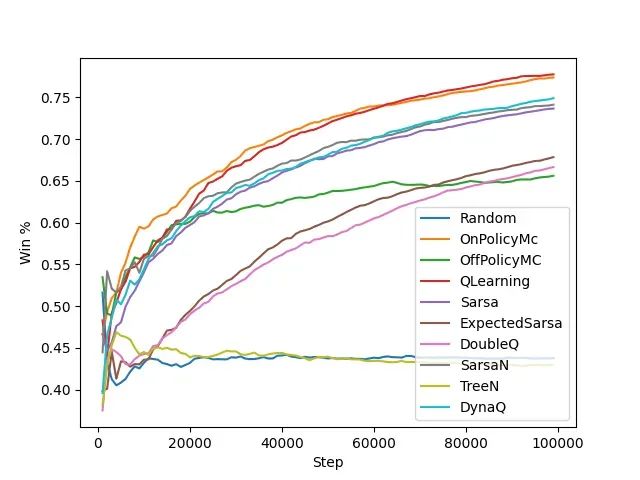
强化学习算法基准测试:6种算法在多智能体环境中的表现实测
本文构建了多智能体强化学习的系统性评估框架,选择井字棋和连珠四子这两个具有代表性的双人博弈游戏作为基准测试环境。通过引入模型动物园策略和自我对战机制,研究探索了各种表格方法在动态对抗环境中的学习能力和收敛特性。



