
推荐系统不是单一算法而是一条流水线,每个阶段在不同约束下解决不同的问题。多数入门实现把所有事情塞进一步:算相似度。但生产级系统需要做关注点分离,分别管控质量、速度和行为。
本文梳理一条可以实际构建并持续扩展的端到端推荐 Pipeline。
动手写代码前,先回答三个问题:Item是什么(电影、商品、帖子),用户行为是什么(点击、观看、购买),衡量成功的指标是什么(CTR、观看时长、留存率)。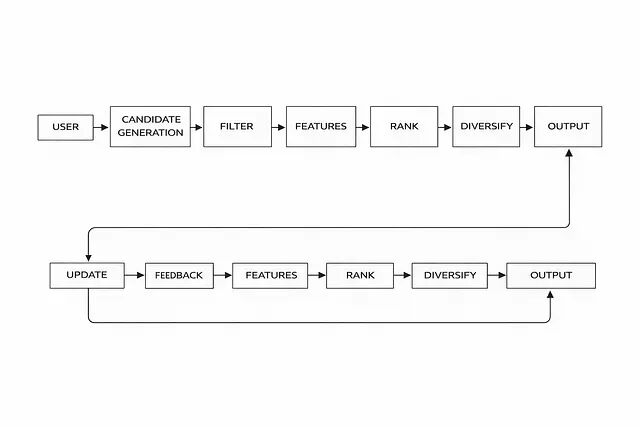
定义不清楚,后续所有优化方向都可能跑偏。
数据层(实际用到的数据)
需要两类数据。Item数据:元数据(类型、标签、描述)、时间戳(发布、更新)、热度指标(浏览量、评分)。用户数据:交互历史(点击、观看、跳过)及对应的时间戳。
最小数据结构如下:
items = {
"id": 1,
"genre": ["action", "sci-fi"],
"popularity": 0.8,
"timestamp": 2024
}
user = {
"history": [1, 5, 9],
"recent": [5, 9]
}
候选生成(缩小搜索空间)
对全量数据做排序在工程上不可行,所以第一步是把候选集从数千缩减到几百。
常用手段包括基于内容的过滤、关键词匹配、向量相似度检索:
candidates=get_similar_items(user["recent"])
要求很简单——快、覆盖广,不要求精确。
过滤层(剔除不合适的选项)
排序之前,先去掉明显不该出现的结果:已经看过的、过时的内容、无效条目。
candidates = [
i for i in candidates
if i not in user["history"]
]
单独做好过滤这一步,系统整体质量就能有明显改善。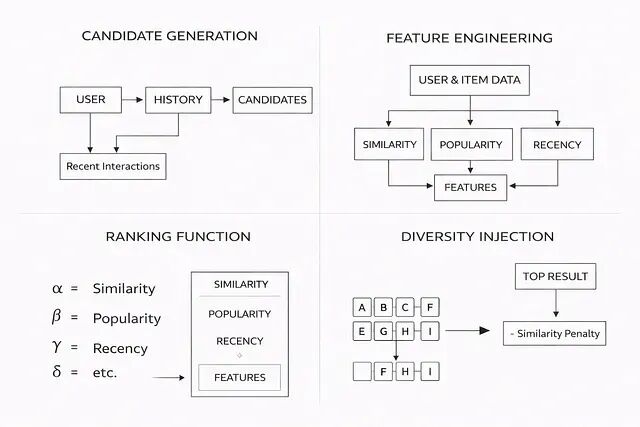
特征工程(准备信号)
每个候选项需要计算多维信号:相似度分数、热度分数、新鲜度分数、用户偏好匹配度:
def compute_features(user, item):
return {
"similarity": sim(user, item),
"popularity": item["popularity"],
"recency": 1 / (current_year - item["timestamp"] + 1)
}
排序层(核心决策引擎)
多维信号需要组合成一个最终分数:
score= (
0.5*similarity+
0.3*popularity+
0.2*recency
)
权重不是固定值。它取决于item目标、用户行为模式以及 A/B 实验的结论,需要持续调整。
多样性注入(避免重复)
跳过这一环节,推荐结果会迅速坍缩到单一类别。
所以可以先选出得分最高的物品,之后每选一个新物品,对其与已选集合的相似度施加惩罚:
adjusted_score = score - λ * similarity_with_selected
最终选择(Top-N 输出)
选出排序后的前 N 个结果:
final = sorted(candidates, key=lambda x: x["score"], reverse=True)[:10]
这就是最终呈现给用户的推荐列表。
反馈收集
没有反馈,系统就没有迭代的依据。需要追踪的核心事件:点击、跳过、停留时长。
feedback = {
"clicked": [item_id],
"skipped": [item_id]
}
更新机制(使系统具备自适应能力)
反馈数据用来调整用户画像和特征权重:
if item in feedback["clicked"]:
increase_weight("similarity")
if item in feedback["skipped"]:
decrease_weight("similarity")
完整 Pipeline 流程
用户 → 候选生成 → 过滤 → 特征 → 排序 → 多样化 → 输出 → 反馈 → 更新
每个模块相互独立,可以单独替换和优化。
总结
推荐系统的核心不在于找到相似的物品,而在于在约束条件下选出合适的物品。
一个系统如果能做到有效过滤、基于多维信号排序、根据反馈持续调整,它就不再只是一个练手项目——而是一个可以在生产环境中运行的系统。