
要理解向量搜索先要弄清楚为什么需要向量数据库,关系型数据库处理结构化数据得心应手。所谓结构化数据就是那些具有固定列的表格数据,比如说:姓名、年龄、薪资、日期。这类数据精确匹配查询很简单:"Age > 25"或"Name = Subham"就能拿到想要的结果。
但现实中大量数据是非结构化的:电子邮件、短信、社交媒体帖子、音频录音、手写笔记、会议记录。SQL 数据库虽然能存储这些文本和音频却无法理解其中的语义。搜索"car"时,关键词匹配会漏掉写着"automobile"的内容。
Embeddings
机器学习模型可以将非结构化内容转换为 embedding:一组数字构成的向量,用来表征文本的语义。
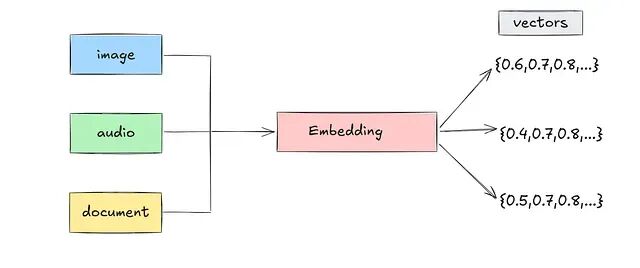
存储和检索这些向量就是向量数据库的职责,它主要做两件事:高效存储向量,以及快速执行最近邻搜索(语义搜索)。
简单概括:关系型数据库擅长精确的结构化查询;向量数据库擅长对非结构化数据做相似性检索。
向量相似性搜索
向量相似性搜索算法有多种,本文介绍以下四种:余弦相似度搜索、Flat Index、倒排文件索引(IVF)、HNSW(层次化可导航小世界)。
余弦相似度衡量的是两个向量在方向上的接近程度。
取值范围在 -1 到 +1 之间。夹角越小,余弦值越大,相似度越高。方向相同的两个向量夹角为 0,余弦相似度等于 1;互相垂直时夹角为 90 度,余弦相似度为 0;方向完全相反则夹角 180 度,余弦相似度为 -1。
用一个数值例子来说明。取两个句子:
- S1:"I like backend."
- S2:"I like frontend"
这里用 one-hot 编码做简化演示。实际场景中,Word2Vec 或 BERT 等模型生成的向量更稠密,语义捕捉能力也更强。
唯一词汇 = [I, like, backend, frontend]
对 S1 和 S2 编码:
- S1 → [1, 1, 1, 0]
- S2 → [1, 1, 0, 1]
点积计算:
(1×1)+(1×1)+(1×0)+(0×1)=2
模长计算: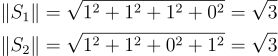
相似度得分: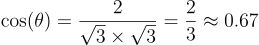
结果是中等相似度,既不算高也不算低。
Flat Index(暴力搜索)
Flat Index 是最直接的一种向量搜索方式:拿查询向量逐一比对数据集中的每个向量,计算余弦相似度,排序后返回前 K 个结果。没有任何近似或优化手段,因而召回率达到 100%。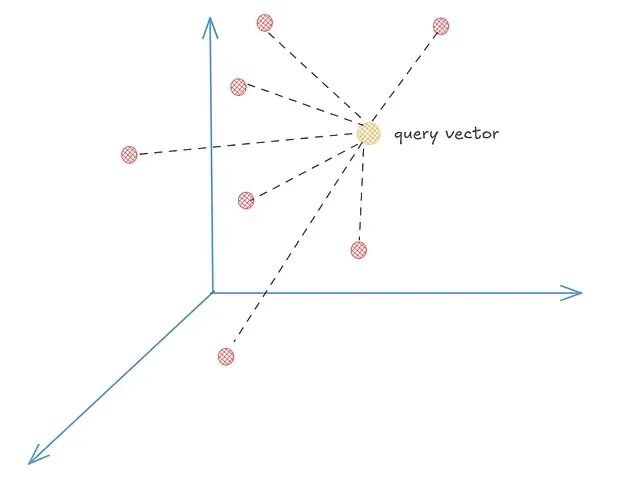
具体流程:
- 取查询向量
- 初始化空的结果列表
- 遍历数据集中每一个向量
- 对每个向量计算与查询向量的余弦相似度
- 将
(vector, similarity score)存入结果 - 按相似度从高到低排序
- 返回前 K 个最相似的向量
精度最高,但是代价也最高。假如数据集中有 100 万个向量,每次查询都要计算 100 万次距离,速度根本不可接受,所以就出现了倒排文件索引。
倒排文件索引(IVF)
IVF 的核心思路是把整个向量空间切分成若干簇,查询时只在最相关的几个簇里搜索,而不是扫描全部数据。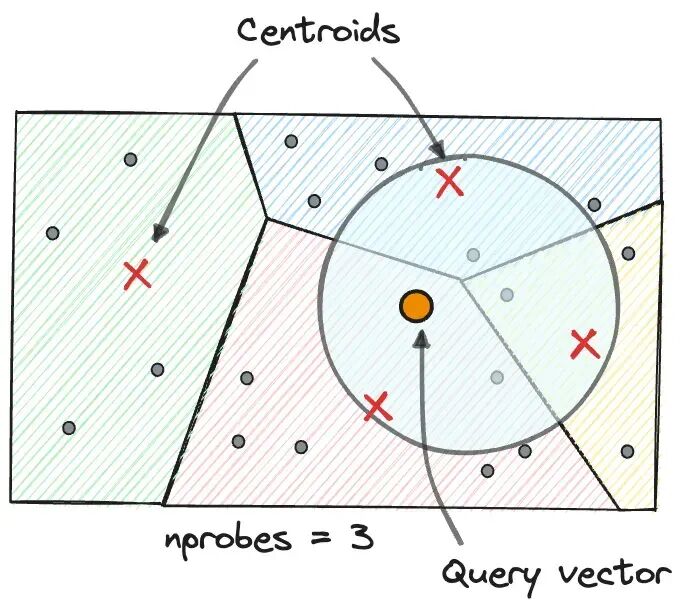
算法分四个阶段:
第一步,聚类。假设有 100 万个向量,用 k-means 将它们划分为 100 个簇,每个簇对应一个质心向量。
第二步,构建倒排列表。每个簇维护一份属于该簇的向量列表:
C1 → [v1, v2, v3, …]C2 → [v200, v201, …]
第三步,定位最近的簇。给定查询向量 Q,计算 Q 到全部 100 个质心的距离,选出距离最近的若干个簇。选几个簇由 nprobe 参数控制,假设取 5。
Q vs C1Q vs C2…Q vs C100
第四步,在选定簇内搜索。每个簇包含约 1 万个向量,5 个簇加起来只需检索 5 万个向量,相比原来的 100 万缩减了 20 倍。
这就是 IVF 的权衡:用少量的召回率损失换取数量级的速度提升。
层次化可导航小世界(HNSW)
理解 HNSW 之前,需要先掌握两个基础概念:跳表和可导航小世界。
跳表(Skip List)
跳表是一种概率性数据结构,搜索、插入、删除的时间复杂度均为 O(log n)。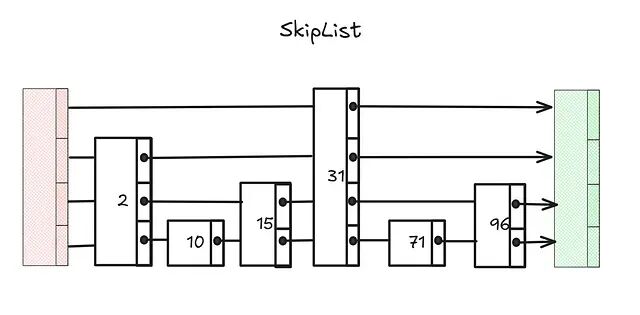
它的原理并不复杂:在普通有序链表之上叠加多层快捷指针。搜索时从最高层出发以大步幅向右跳跃;当下一个节点的值超过目标时下降一层继续搜索,每下降一层搜索范围就缩小一截。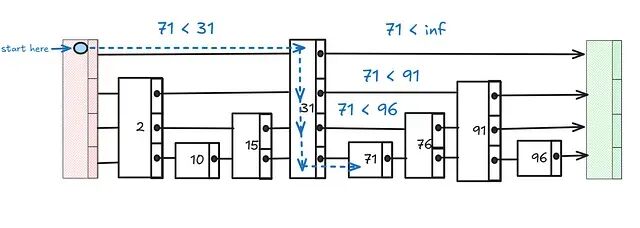
以在有序链表中查找 71 为例,规则如下:若 71 等于当前 key,搜索完成;若 71 小于右侧下一个 key,下降一层;若 71 大于或等于右侧下一个 key,向右移动。
普通链表要逐个遍历节点才能定位目标。跳表借助高层索引跨越大量节点,访问路径上的节点数量大幅减少。
可导航小世界(NSW)
NSW 是一种基于图的搜索方法:从某个节点出发,每一步都移动到距离查询点更近的邻居,利用图中的局部捷径快速逼近目标。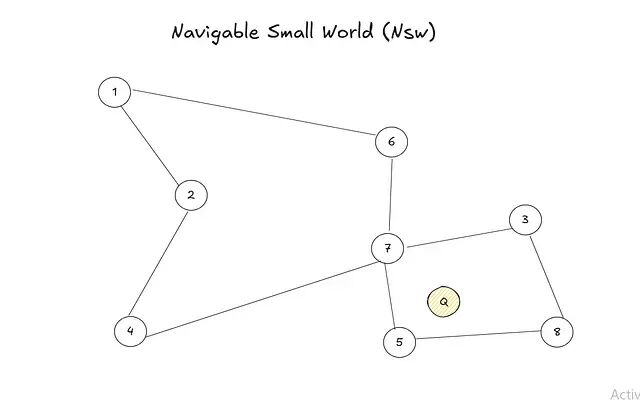
过程:随机选择一个入口点。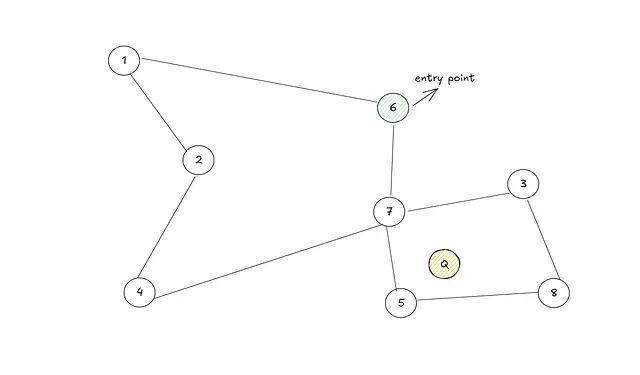
计算入口点所有邻居到查询节点的距离,移动到距离最近的那个邻居。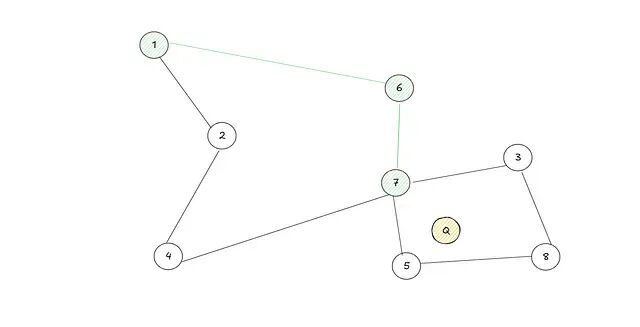
重复以上操作,直到当前节点就是距离查询节点最近的位置。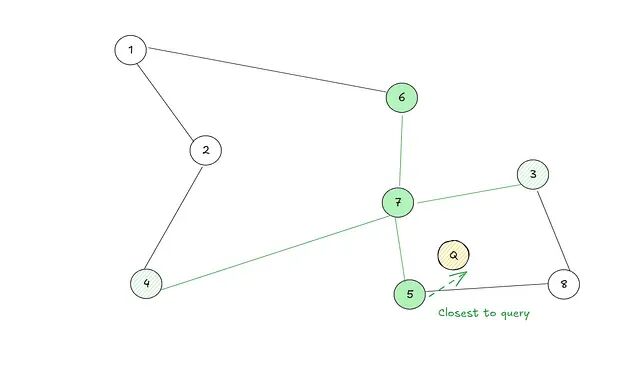
但是NSW 有一个固有缺陷,提前停止问题。搜索可能陷入局部最优:当前节点的所有邻居都不比它离目标更近,搜索于是终止,但全局范围内明明存在更优的节点。这种情况下返回的是次优结果。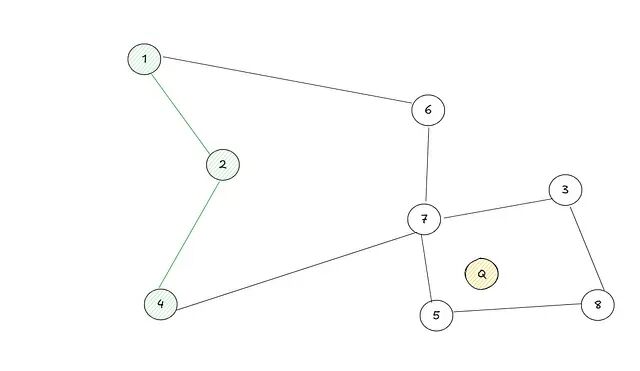
图中 2 是次优解,实际上存在更接近目标的节点
层次化可导航小世界(HNSW)
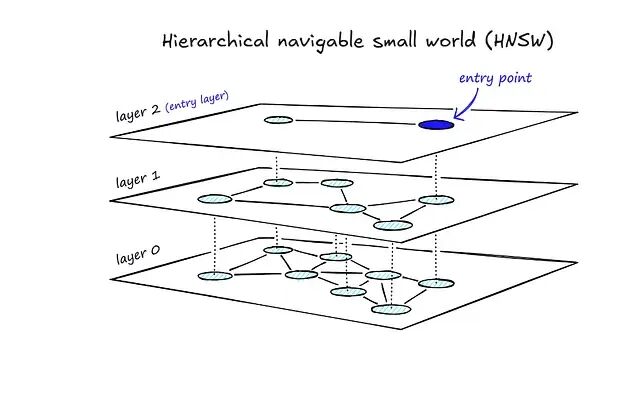
HNSW 把跳表的层次结构和 NSW 的贪心搜索结合在一起。顶层节点稀疏,底层节点稠密——跳表的分层思想;每一层内部通过邻居间的贪心遍历逐步逼近目标——NSW 的搜索策略。
HNSW 算法
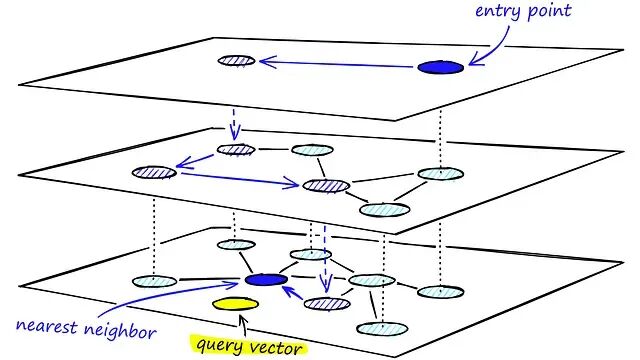
- 从顶层的入口点开始
- 查看当前节点的所有邻居
- 移动到距离查询最近的邻居
- 重复直到没有更近的邻居(局部最小值)
- 下降一层,以当前位置作为新的起点
- 重复直到第 0 层
- 在第 0 层,使用 ef(搜索宽度)扩展搜索以收集候选项
- 从候选项中返回 top-k 结果
整个过程先在高层用少量节点做粗粒度定位,逐层细化搜索范围,到最底层展开精细搜索。高层的大跨度跳转避免了 NSW 中的局部最优陷阱,底层的密集连接保证了最终结果的质量。
总结
三种索引结构各有适用场景。Flat Index 不做任何近似,逐一比对全部向量,精度无损但速度随数据量线性增长,只适合小规模数据集或对召回率有极端要求的场景。IVF 通过 k-means 聚类将向量空间划分为多个分区,查询时仅扫描少数几个簇,用可控的精度损失换来了检索速度的数量级提升;HNSW 则走了一条完全不同的路线——构建多层图结构,高层稀疏连接用于快速定位大致区域,底层密集连接用于精细搜索,兼顾了检索速度和召回质量。
实际工程中,数据规模在几万以下可以直接用 Flat Index;百万级别的数据 IVF 是一个性价比很高的选择;对延迟和召回率都有严格要求的在线服务,HNSW 通常是首选方案。多数向量数据库(Milvus、Qdrant、Weaviate 等)都同时支持这几种索引类型,根据业务需求切换即可。
by Subham Nayak