
传统统计方法在时间序列分析中既简洁又有力,但面对大规模时间序列集合时,扩展性往往不尽如人意。现实中的趋势变化往往微弱、带有噪声、数量也不止一个,靠肉眼判断既不可靠也不现实。一旦需要处理数十乃至数百条时间序列,人工识别就更不可行了。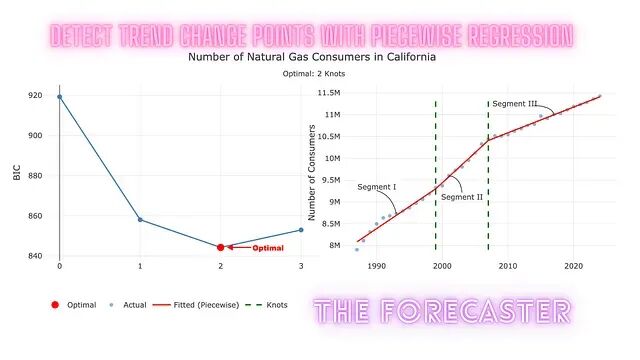
Figure 1: Identify the optimal number of knots and their positions using grid search
解决思路是用程序来定位变化点。估计趋势变化点的手段有很多,本文聚焦于网格搜索策略与分段回归的结合,自动确定变化点的数量和位置。
完整代码有 R 和 Python 两个版本,Streamlit 应用也可在线体验。
使用网格搜索寻找变化点
网格搜索是一种系统化的优化技术,原理并不复杂:在预定义的离散候选参数集上逐一评估模型,按照指定准则挑出表现最好的那组配置。
在分段回归中,待搜索的参数就是节点(knot)的数量和位置,每个节点对应一个候选变化点。整体流程如下:
- 定义参数
- 定义代价函数
- 对每组网格组合拟合分段回归
- 对结果评分
- 选择达到最优结果的网格组合
为减少过拟合、增强稳定性,还需要设置节点之间的最小距离约束,避免变化点在时间轴上挤得太近。
定义代价函数
比较不同变化点数量的模型之前,需要有一套统一的评价标准。代价函数(也叫损失函数或目标函数)就是干这个的:它接收一组模型参数,输出一个标量,反映模型误差或拟合质量。机器学习和统计建模中的训练与模型选择,本质上都是在寻找令代价函数取极值的参数组合。
回归问题中,代价函数度量的是预测值与观测值之间的偏差。常见选择包括:均方误差(MSE)度量平方残差的均值;平均绝对误差(MAE)度量绝对残差的均值;负对数似然(NLL)度量观测数据在给定模型下出现的概率。
这些指标只关注拟合优度,不考虑模型复杂度。变化点越多的分段回归模型几乎总能把误差压得更低,哪怕它只是在拟合噪声。
应对方法是引入惩罚代价函数,在拟合质量和模型复杂度之间取得平衡。AIC(赤池信息准则)和 BIC(贝叶斯信息准则)是两个典型代表,均以负对数似然为基础,再加上一个与估计参数数量相关的惩罚项。
AIC:
AIC=-2log(L) +2k
BIC:
BIC=-2log(L)+klog(n)*
其中:
- L = 最大化似然值
- k = 估计参数的数量
- n = 观测值的数量
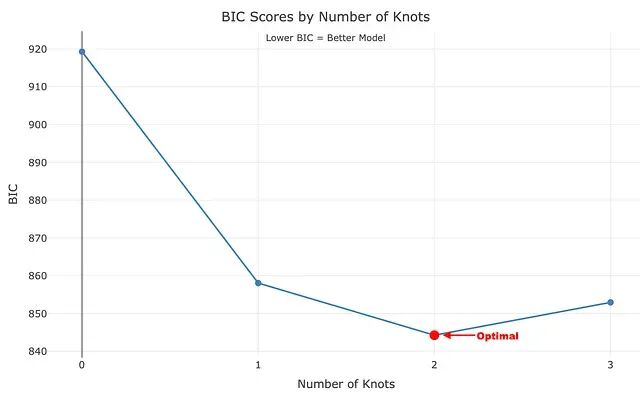
Figure 2: Example for finding the optimal number of knots using the BIC score
惩罚项的存在抑制了不必要的复杂度,有助于在网格搜索中筛选出真正有意义的变化点数目。BIC 的惩罚力度比 AIC 更重,选出的变化点数量往往更少——也就更保守。
网格搜索工作流程
基础概念铺设完毕,下面定义网格搜索的具体流程。一个典型的变化点检测网格搜索包含四个环节:
- 准备数据并定义搜索空间
- 为给定的节点配置拟合分段回归模型
- 使用惩罚代价函数评估每个配置
- 选择最优的节点数量及其位置
函数输入是时间序列与搜索空间参数,输出是最优节点集合。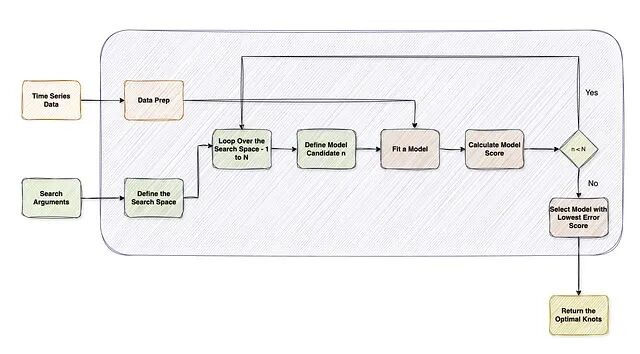
Figure 3: A general grid search function workflow
网格搜索胜在直白、易于实现,但计算开销会随候选变化点数量的增长而快速膨胀。引入搜索空间约束可以缓解这个问题:减少待评估的配置数,同时也起到防止过拟合的作用。
具体的约束手段有三条:一是排除序列头尾一定比例的观测值,保证每个分段都有足够数据支撑趋势估计;二是强制每个分段包含不少于某个阈值的观测值,稳定斜率估计,避免模型在短而嘈杂的片段上过拟合;三是限定节点数量的上限,控制搜索范围。
设置这些参数时需要综合考虑观测值数量、序列频率以及业务逻辑。
注意,这里用不含节点的简单趋势模型作为网格搜索结果的基准。
网格搜索实现
回到前一篇教程的示例——加利福尼亚州天然气消费者数量,看一下网格搜索函数在 R 中的实现。Python 版本可在对应 notebook 中获取。
加载所需的库:
library(dplyr)
library(tsibble)
library(plotly)
引入一组辅助函数,其中包括网格搜索函数 piecewise_regression:
fun_path <- "https://raw.githubusercontent.com/RamiKrispin/the-forecaster/refs/heads/main/functions.R"
source(fun_path)
加载序列并整理格式:
path <- "https://raw.githubusercontent.com/RamiKrispin/the-forecaster/refs/heads/main/data/ca_natural_gas_consumers.csv"
ts <- read.csv(path) |>
arrange(index) |>
filter(index > 1986) |>
as_tsibble(index = "index")
ts |> head()
序列为年度数据,index 列是时间戳,y 列是数值:
# A tsibble: 6 x 2 [1Y]
index y
<int> <int>
1 1987 7904858
2 1988 8113034
3 1989 8313776
4 1990 8497848
5 1991 8634774
6 1992 8680613
绘制序列:
p <- plot_ly(data = ts) |>
add_lines(x = ~ index,
y = ~ y, name = "Actual") |>
layout(
title = "Number of Natural Gas Consumers in California",
yaxis = list(title = "Number of Consumers"),
xaxis = list(title = "Source: US energy information administration"),
legend = list(x = legend_x, y = legend_y)
)
p
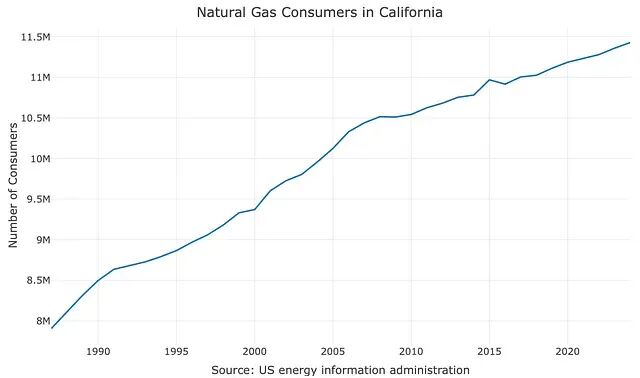
Figure 4: Yearly number of natural gas consumers in California. The series is trending up without seasonality patterns
用 piecewise_regression 函数识别最优节点数量及位置:
grid <- piecewise_regression(
data = ts,
time_col = "index",
value_col = "y",
max_knots = 4,
min_segment_length = 8,
edge_buffer = 0.05,
grid_resolution = 20
)
搜索空间由以下参数定义:
max_knots- 最大节点数量min_segment_length- 两个节点之间的最小观测值数量edge_buffer- 从序列头尾排除的观测值比例grid_resolution- 每个节点数量对应的最大搜索组合数
这里把 max_knots 设为 4,搜索空间中节点数量的范围就是 0–4。函数会根据约束条件生成候选配置,并裁剪掉不满足条件的组合。
运行结果如下:
Testing 0 knot(s)...
Best BIC: 919.28 | RSS: 1.006639e+12 | Tested 1 configurations
Testing 1 knot(s)...
Best BIC: 858.05 | RSS: 182625404855 | Tested 18 configurations
Testing 2 knot(s)...
Best BIC: 844.26 | RSS: 115452860424 | Tested 25 configurations
Testing 3 knot(s)...
Best BIC: 852.94 | RSS: 131838198802 | Tested 5 configurations
Testing 4 knot(s)...
Optimal model: 2 knot(s) with BIC = 844.26
Warning message:
In generate_candidates(k, min_idx, max_idx, min_segment_length) :
Cannot fit 4 knots with min segment length 8
输出按节点数量分组列出了测试过的模型数,最终确定最优节点数为 2。函数还抛出了一条警告:受搜索空间约束限制,观测值不足以容纳 4 个节点,因此跳过了对应的拟合。这一行为符合预期——说明约束条件正在起作用。
下面的动画展示了搜索空间中所有配置的拟合过程: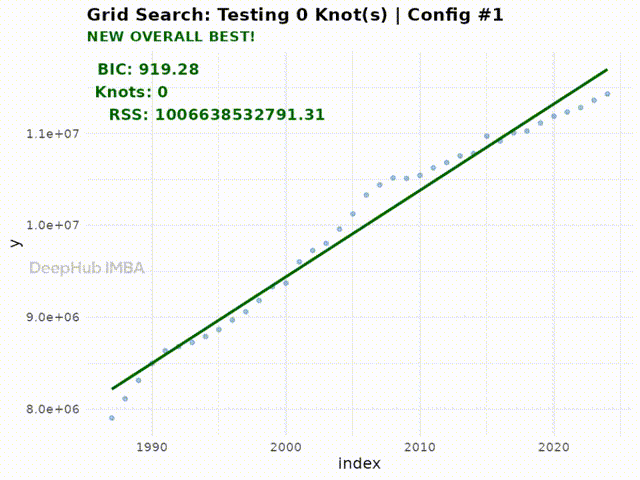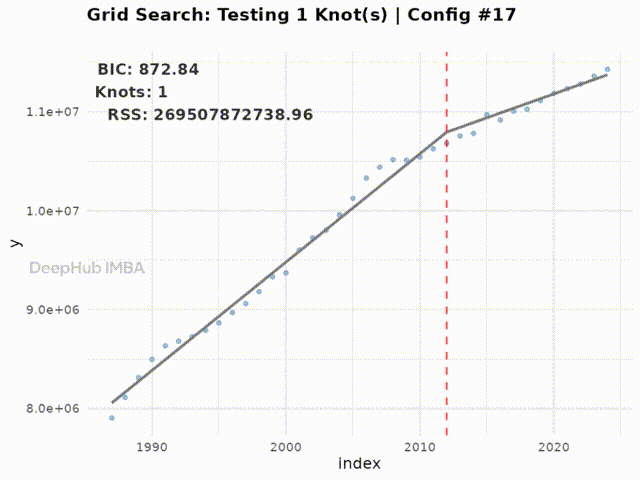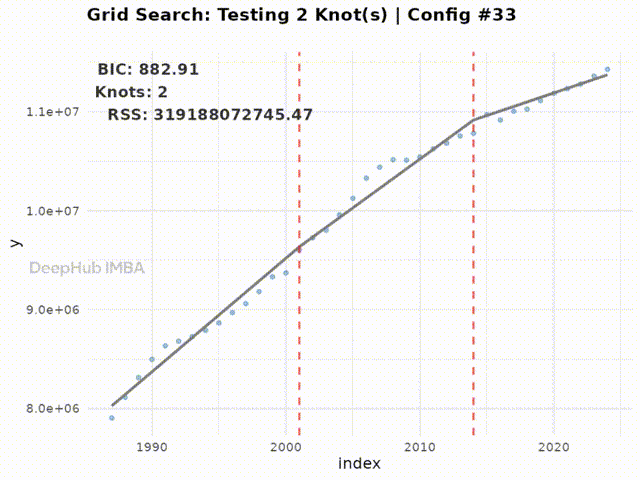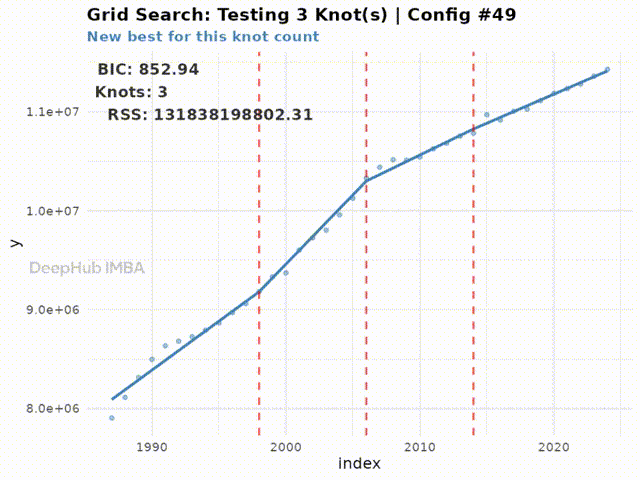
Figure 5: Animation of the grid search process
函数输出中包含搜索过程和最优结果的详细信息。最优节点数:
grid$optimal_knots
[1] 2
节点位置:
grid$knot_dates
[1] 1999 2007
最后,用
plot_knots
函数加上注释,把最优节点叠加到原始序列上进行可视化: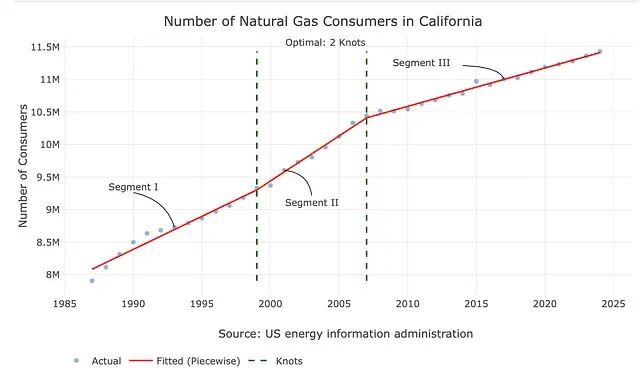
Figure 6: The optimal number of knots and their positions based on the grid search results
局限性
网格搜索配合分段回归,对于识别趋势变化点的数量和位置是一种切实可行的方案。它最适合的场景是相对"干净"的时间序列,主导信号就是底层趋势——本文的示例正是如此。
现实中的时间序列往往不这么纯粹。季节性、突发水平偏移、异常值都可能干扰甚至扭曲趋势成分。在这些效应存在的情况下,网格搜索可能定位到虚假的变化点,也可能遗漏真正有意义的趋势断裂。
一种可行的预处理策略是先做分解(如 STL),将趋势成分分离出来,再在提取到的趋势上执行网格搜索,而非直接在原始序列上操作。
对于结构复杂或噪声较大的序列,能够联合建模趋势与季节性的变化点检测方法可能更为适用。
总结
本文展示了如何将变化点检测转化为一个优化问题:通过网格搜索遍历候选节点配置,用惩罚似然准则(BIC)选出最优模型,配合分段回归完成趋势变化点的自动检测。
分段回归是建模趋势变化的可解释框架;网格搜索虽然朴素,但在估计变化点位置上行之有效;BIC 等惩罚准则在拟合优度与模型复杂度之间做出了取舍,抑制了过拟合倾向;搜索空间约束——边缘缓冲区、最小分段长度、最大节点数——进一步稳定了模型并降低了计算开销。
网格搜索在计算效率上确实算不上最优解,但它的透明度是一大优势,作为基线方法和实际工程中的可用方案都没有问题。面对更复杂的场景,可以在此框架基础上引入高级优化策略或贝叶斯变化点检测方法。下一篇教程将讨论如何把这套方法应用到更复杂的实际场景中。
本文代码:
https://github.com/RamiKrispin/the-forecaster/
by Rami Krispin