
和 AI 对话超过 20 轮之后,看着它慢慢开始胡说八道,如果有过这种经历,那么你就应该看看这篇论文
跟 AI 聊天机器人对话时,用户输入的每一个字都会被保存,模型给出的每一条回复同样会被保存。所有历史内容在下一轮对话中被回传给模型,再下一轮,再下一轮,像河底的沉积物越堆越高。
每一个聊天机器人、每一个 AI Agent、每一个多轮对话系统都按这个方式运行。看起来理所当然,模型不存自己的回复,怎么"记住"之前说了什么?
重大发现有时源于一个不起眼的问题。而直到最近才有人问出来:如果存储 AI 自己的回复,反而在拖累它的表现呢?
MIT 在 2026 年 2 月发表了一篇论文来回答这个问题。标题刻意低调——"Do LLMs Benefit From Their Own Words?"——但结论一点都不低调。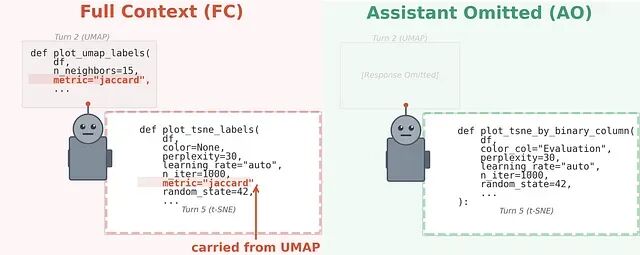
测试一个没人质疑过的假设
实验设计很简单,正因如此结果才格外有意思。
研究人员从 WildChat 和 ShareLM 中抽取了真实的、杂乱的、来自实际使用场景的对话——不是精心构造的合成 benchmark,而是真实用户和 AI 系统聊真实话题的记录。他们在四个模型上用两种方式分别跑了一遍:Qwen3–4B、DeepSeek-R1–8B、GPT-OSS-20B 和 GPT-5.2。
# 条件 A - 标准方式(今天每个聊天机器人都在做的事)
context = [user_1, assistant_1, user_2, assistant_2, …]
# 条件 B - 省略助手回复(没人尝试过的做法)
context = [user_1, user_2, user_3, …]
# 去掉所有之前的 AI 回复。只保留人类的消息。
# 然后比较质量。就这样。这就是整个实验。
简单,大胆。结果呢?
Removing prior assistant responses does not affect response quality on a large fraction of turns. Omitting assistant-side history can reduce cumulative context lengths by up to 10×.
上下文长度缩减约 10 倍,回复质量几乎不变。多轮提示中 36.4% 完全自包含,根本不需要任何历史记录;约 70% 的对话轮次要么不需要历史,要么仅凭用户消息就能重建上下文。
上下文污染的机制
典型的聊天过程:提一个问题,AI 回复,再追问。
但底层实际发生的事情更可能跟我们的理解不太一样:模型在处理追问时,看到的并不只是新的提问,而是新提问加上它之前给出的每一条回复的全文,包括其中所有的错误、幻觉、措辞偏差,以及几轮前引入的错误假设。
所以模型没有任何特殊标记来区分"这是我自己之前的输出"和"这是可信的外部信息"。它读取自己过去回复的方式,和读取 ground truth 完全一样。第二轮里自信说错的东西,第三轮会在上面继续往下搭,第四轮、第五轮照搬不误——每一轮都进一步偏离事实,同时愈发笃定。
论文给这种现象起了个名字。当模型过度依赖先前的回复,锁定早期的错误、幻觉或文体惯性并将其向后续轮次传播时,称为 context pollution——上下文污染。早期的偏差经由反馈循环不断放大。
MIT 团队选的这个术语很准确。长对话中观察到的质量滑坡并非随机的系统疲劳。
模型自己的声音才是污染源。
从 prompt 中删掉 AI 过去的回复,省下的并不只是算力和 Token 空间,更关键的是切断了模型饮用自己毒水的通路。
大多数对话并不需要想象中那么多历史
去掉 AI 的回复还能拿到质量相当的答案,为什么?论文给出的解释很直观,听完会觉得奇怪为什么没有人更早意识到。
多数对话轮次在本质上是自给自足的,真实多轮对话中 36.4% 的提示完全独立,跟之前的交互没有任何关联。另外约三分之一虽然引用了先前的助手回复,但其中并不包含任何可供模型利用的新信号。
两部分加起来,约 70% 的典型对话中,AI 存储的历史要么是无关噪声,要么更糟——失真的来源。一轮一轮忠实地把模型自己的话回传,大多数时候毫无帮助,有时候反而在拖后腿。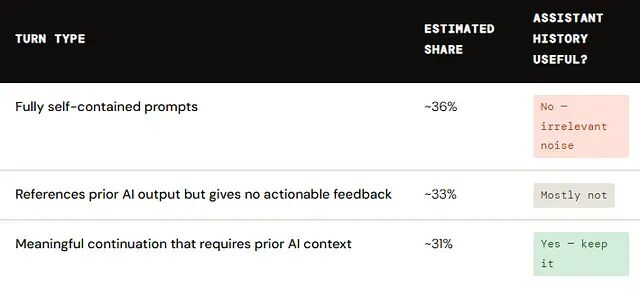
不是"一律删除",而是选择性过滤
别带着"论文让永远删掉所有对话历史"的印象离开。它没有这么说。
研究人员明确指出了一个限定条件。不同模型的表现并不一致:对于开源推理模型——DeepSeek-R1–8B 和 GPT-OSS-20B——有没有助手历史记录,回复质量基本持平;而 GPT-5.2 作为能力更强的闭源模型,移除助手历史确实导致了一定的质量下降。能力更强的模型似乎能从自身先前的上下文中提取更多有用信号,也更擅长利用这些上下文而不被带偏。
论文的主张不是全面省略,是选择性过滤。研究团队为此训练了一个分类器,逐轮判断保留 AI 之前的输出对当前回复究竟有益还是有害。在这种自适应省略策略下,回复质量和上下文缩减同时得到改善。明智的做法不是最大化上下文,而是只保留必要的上下文。
对现有每一个 AI Agent 的影响
AI Agent——那些部署来写代码、浏览网页、管理文件、在循环中回答客户问题的系统——运行起来动辄几十轮甚至上百轮。
每个 Agent 框架都存储完整轨迹:工具调用、中间推理步骤、每一条回复。上下文随对话长度线性增长,触及上限后,Cursor、Claude Code 这类系统开始压缩和裁剪,只为维持运转。这些手段本质上是搭建在一个有缺陷的假设之上的工程补丁。
这项研究指出默认策略应该翻转。问题不该是"什么时候修剪?"而该是"为什么要存储这些?"没有具体且合理的理由,就不要保留助手的回复。这是一种根本不同的设计哲学,会实质性地改变系统的构建方式。
过去数年,行业一直在追逐更长的上下文窗口——128K Token、1M Token,竞赛的主题始终是"装进更多内容"。没有人停下来问过:塞进去的大部分内容是否真的在发挥作用。
模型自己的话,可能是上下文窗口中价值最低的部分;在上下文污染发生时,反而是危害最大的部分。
其他论文中已有端倪
多轮 AI 对话比看起来更脆弱,这不是第一次出现信号。
微软 2025 年发表的研究得出了一组互补的结论:LLM 在多轮欠定义对话中的任务表现平均只有约 65%,比单轮场景下 90% 的表现低了 25 个百分点。论文将这种现象命名为 "lost in conversation"——模型一旦在早期走错方向,不会自我纠正,而是螺旋式恶化。
Chroma 同年发表的研究识别出一个相关现象,称之为 "context rot":随着输入长度增长,模型表现变得越来越不可靠,即便在简单的检索任务上也如此。测试覆盖了十八个不同模型,包括 GPT-4.1、Claude 4 和 Gemini 2.5。所有模型在长输入下都出现了退化——不是平滑的衰减,而是不规则的波动。
另一项关于 "context branching" 的独立研究发现,当上下文在多轮对话中逐渐被污染时,开发者经常遇到"看似合理但实际错误的解决方案",在探索性编程中尤为普遍——早期的错误假设持续累积,且无法在不重新开始对话的情况下回退。
Chroma Research (2025) · "Context Rot: How Increasing Input Tokens Impacts LLM Performance"
Laban et al. (2025) · "LLMs Get Lost In Multi-Turn Conversation" · Microsoft Research
总结
对于日常依赖 AI 工具的使用者——无论是编码助手还是研究型 Agent——这篇论文要求重新审视工作习惯。长对话直觉上让人觉得模型会"更聪明",因为上下文更多。事实恰好相反:对话进行了二十轮的模型很少比一个全新会话更准确,多数时候只是深陷在自己累积的错误里。点击"新建对话"不是在丢失上下文,有时只是在清除毒素。
对于系统构建者,默认的架构——将每一轮对话堆叠到窗口塞满——不仅浪费算力、增加延迟,还在通过自我强化的错误循环主动拉低输出质量。Agent 设计的下一个前沿不在于更好的压缩算法,而在于动态的、选择性的省略。
抛开 10x 的效率增益和架构层面的争论,这项发现还有一层更深的意味。过去几年行业构建了能对话的系统,然后强迫这些系统无休止地听自己说话,默认把自我引用等同于记忆。
证据表明两者并不等价。支撑所有多轮 AI 系统的基础假设多年来未经审视,而在构建下一个十年的 Agent 架构时,一个令人不安的结论浮出水面:有时候,AI 能做的最明智的事,是忘掉它刚才说了什么。
论文
https://arxiv.org/pdf/2602.24287
by Ship X/ TechX