
多智能体系统是 2026 年主流构建方式,Claude 的智能体团队功能、OpenAI 的 Swarm 框架、LangGraph 的编排层以及 CrewAI都指向同一个结论:复杂任务需要协调配合的专家,而非一个万能通才。
为什么单个智能体会失效
一个智能体包揽一切,就像一人创业公司——小规模时凑合,规模上去就垮了。
反复遭遇的失效模式有三种。
上下文窗口污染:当一个智能体挂载十种不同工具时,每份工具 schema、每条 API 响应、每个中间结果都在抢占上下文空间。执行到十步任务的第七步 ,第二步里的关键信息早已被挤出或稀释。
角色混乱:被指示"调研、分析、编写代码、起草摘要"的智能体,往往会在这些角色之间相互干扰:调研没完成就开始写代码,代码没编译就开始起草摘要。系统提示词逐渐变成一堆互相抵触的指令。
故障扩散:单个智能体在第三步出错,第四步到第十步全部受污染,没有隔离机制、没有检查点、没有独立验证。
给每个智能体分配单一职责、少量工具和清晰的系统接口,可以同时解决上述三个问题。
三种行之有效的编排模式
构建了几套多智能体系统之后,几乎所有架构都可以归结为以下三种模式,或它们的混合体。
Supervisor 模式
一个中央 supervisor 智能体接收任务,将其分解为子任务,分配给各专家智能体,收集结果后综合输出最终答案。只有 supervisor 能看到全局。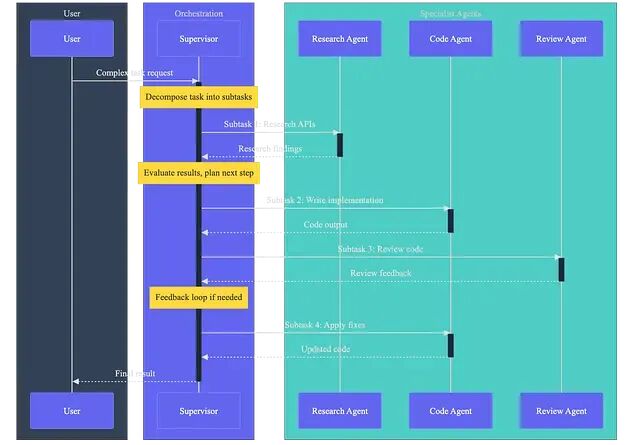
这是最常见的模式,也是优先考虑的起点。Claude 的智能体团队功能本质上就是该模式的产品化实现:定义专家智能体,编排器负责在它们之间路由工作。
supervisor 通常运行在能力较强的模型上(Claude Opus 4.6、GPT-5.3),专家智能体则可以选用更便宜、更快的模型(Claude Sonnet 4.5、Gemini flash),毕竟它们的任务范围窄得多。
supervisor = Agent(
model="claude-opus-4.6",
system_prompt="You are a project coordinator. Decompose tasks and delegate to specialists.",
available_agents=["researcher", "coder", "reviewer"]
)
researcher = Agent(
model="claude-sonnet-4.5",
system_prompt="You research technical topics. Return structured findings.",
tools=[web_search, doc_lookup, arxiv_search]
)
适用场景:子任务边界清晰的复杂任务,例如客户支持、内容生成流水线、代码审查工作流。
需要警惕的是,supervisor 本身容易成为瓶颈。任务分解一旦出错,下游每个智能体都会拿到错误的指令。
Pipeline 模式
各智能体串联成线性链路,每个节点接收上游输出,完成自身的转换处理后传递给下游。
pipeline = [
Agent(name="extractor", task="Extract key entities from raw text"),
Agent(name="enricher", task="Enrich entities with database lookups"),
Agent(name="analyzer", task="Analyze patterns across enriched entities"),
Agent(name="reporter", task="Generate human-readable report"),
]
result = input_data
for agent in pipeline:
result = agent.run(result)
适用场景:ETL 式工作流、文档处理,以及任何第 N 阶段输出即为第 N+1 阶段输入的任务。
需要警惕的是,错误传播。第一阶段的失误会级联穿透整条链路,各阶段之间必须设置验证门控。
Swarm 模式
没有中央协调者。各智能体点对点通信,根据当前状态动态移交工作:OpenAI 的 Swarm 框架普及了这一思路。
核心机制是 handoff:某个智能体判断自身已不再适合处理当前状态,便将控制权连同对话上下文一起转交给另一个智能体。
def triage_agent_instructions(context):
return """You handle initial customer contact.
If the issue is billing, hand off to billing_agent.
If the issue is technical, hand off to tech_agent.
If you can resolve it directly, do so."""
triage = Agent(
name="triage",
instructions=triage_agent_instructions,
handoffs=[billing_agent, tech_agent]
)
适用场景:对话走向难以预测的面向用户系统,以及分类路由场景。
需要警惕的是:无限 handoff 循环,智能体 A 认为应由 B 处理,B 又认为应由 A 处理。所以需要设置最大 handoff 深度。
智能体间通信
多智能体系统里最难的部分不是构建单个智能体,而是让它们有效地协作。
结构化消息传递是不可妥协的前提。智能体之间不能交换自由文本,必须为每个角色的输入输出定义明确的 schema。
class AgentMessage:
sender: str
receiver: str
task_id: str
payload: dict # 结构化数据
confidence: float # 智能体对自身输出的置信度
requires_review: bool # 人工介入标志
系统中每条消息都携带
confidence
字段。研究智能体返回的结论置信度若低于 0.7,supervisor 不会盲目将其转发给代码智能体,所以要么以更精确的查询重试,要么升级给人工处理。
共享状态与消息传递是第一个绕不开的架构决策。共享状态(所有智能体读写同一个数据库或内存存储)更简单,代价是耦合;消息传递(只通过显式消息通信)更干净,代价是冗长。
实践中倾向于混合方案:用一个共享的任务上下文对象供各方读取,控制流则走显式消息。可以把它想象成一块共享白板,智能体在上面张贴各自的工作产出,再通过点对点消息协调后续动作。
task_context = {
"task_id": "support-4521",
"customer": {"id": "C-1234", "tier": "enterprise"},
"research_findings": None, # 由研究智能体填充
"proposed_solution": None, # 由解决方案智能体填充
"review_status": None, # 由审查智能体填充
}
不会崩溃的任务分解
supervisor 的分解质量决定了整个系统的天花板。单个智能体再优秀,喂给它的子任务如果划分得一团糟,结果也好不了。
按能力分解,而非按步骤数分解。任务看起来复杂,不代表要拆成十个子任务。应当沿着不同智能体各自擅长的边界来切割:研究智能体、代码智能体、审查智能体是自然的划分;"步骤 1-3 的智能体"和"步骤 4-6 的智能体"不是。
每个子任务应当能够独立验证。研究智能体返回一份 API 端点列表,在将其传给代码智能体之前,就能验证这份列表是否存在、格式是否正确,不必等到后续步骤才发现问题。
在每个子任务里明确退出条件。不要只告诉智能体"调研账单 API",而要说:"调研账单 API,并返回:(a) 端点 URL,(b) 认证方式,© 速率限制,(d) 相关错误码。如有任何字段缺失,返回 INCOMPLETE。"
subtask = {
"agent": "researcher",
"objective": "Find the billing API documentation",
"required_outputs": ["endpoint_url", "auth_method", "rate_limits", "error_codes"],
"exit_criteria": "All four fields populated with verified data",
"max_retries": 2,
"timeout_seconds": 30
}
跨链路的错误处理
单智能体的错误处理思路清晰:重试、回退或失败。多智能体场景要难得多,故障会级联、叠加,有时还隐而不发。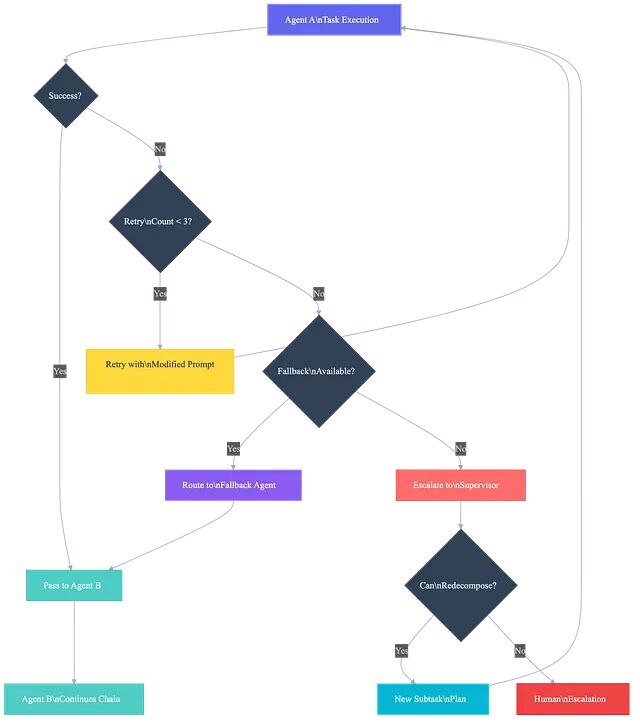
第一层是智能体级别的重试,用于处理短暂性故障,API 超时、速率限制、工具响应格式异常。在向上级报告失败之前,以指数退避策略最多重试三次。
第二层是 supervisor 级别的重新路由。智能体重试耗尽后,supervisor 可以重新分解子任务、切换到其他智能体,或者简化请求。代码智能体曾在一项复杂的重构任务上连续失败,supervisor 将其拆成三个较小的代码变更后顺序派发,三项均顺利完成。
第三层是人工升级。有些故障需要人工判断,系统要知道何时停手。简单的启发式规则:若 supervisor 已尝试三种不同的分解策略且均告失败,则生成一张包含完整尝试上下文的结构化升级工单。
class EscalationPolicy:
max_agent_retries: int = 3
max_redecompositions: int = 2
confidence_threshold: float = 0.6
def should_escalate(self, attempts, confidence):
return (attempts >= self.max_redecompositions
or confidence < self.confidence_threshold)
还有一种隐性风险:部分成功。研究智能体返回了五个所需数据点中的四个,代码智能体基于不完整的数据写出了可运行的代码,审查智能体因代码能够编译而放行。一切看起来正常,直到上线后那个缺失的字段引发故障。验证完整性,不只是验证正确性。
生产部署与监控
在生产环境运行多智能体系统,所需的可观测性能力远超大多数团队的预期。
Tracing 不可或缺
每次智能体调用、每条消息传递、每次工具调用都需要留存 trace。分布式 tracing 配合贯穿整个执行过程的关联 ID,是最基础的保障。
trace= {
"trace_id": "ma-2026-02-25-a8f3",
"total_agents_invoked": 4,
"total_llm_calls": 12,
"total_tool_calls": 8,
"total_tokens": 47_200,
"total_cost_usd": 0.34,
"total_latency_ms": 18_400,
"outcome": "success"
}
没有这些在四个智能体和十二次 LLM 调用里定位一个故障,无异于读一本缺了好几章的悬疑小说。
按智能体监控成本
多智能体架构会成倍放大调用成本。一次 supervisor 调用加三次专家调用,意味着至少四次 LLM 请求。按每个智能体、每种任务类型追踪成本,并在单次任务费用超过阈值时触发告警。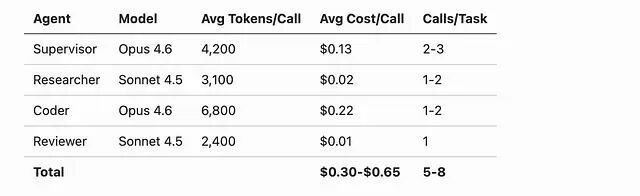
核心优化点是只对真正需要强推理的角色(supervisor、代码智能体)使用高端模型,任务范围更窄的智能体(研究智能体、审查智能体)换用成本更低的模型。仅此一项,成本下降了 40%。
延迟预算
多智能体调用默认串行执行。每个智能体耗时三秒,四个智能体的链路就是十二秒——对面向用户的场景来说不可接受。
两种缓解手段:并行化独立子任务(supervisor 同时派发调研任务与代码框架生成任务),以及流式返回中间结果(在代码智能体仍在工作时,先将研究结论呈现给用户)。
总结
- 按能力拆分,而非按复杂度拆分。一个智能体配十种工具,不如三个智能体各配三种工具。职责单一的智能体更可靠、成本更低、也更易于调试。
- 从 supervisor 模式起步。可预测性和可调试性最好。只有当场景明确需要时,再考虑 Swarm 或 Pipeline。
- 结构化通信不可妥协。定义消息 schema,包含置信度分数,每次 handoff 时验证完整性。
- 将成本预算设为单智能体的 3-5 倍。多智能体系统能力更强,成本也更高,通过对专家智能体选用更便宜的模型来部分抵消。
- 全程留存 Trace。看不见的东西无法调试,跨智能体的分布式 tracing 是最值得投入的运营基础设施。
多智能体系统不是银弹。额外的复杂性、更高的成本、新增的故障模式,这些代都是现实中的问题。但当单个智能体确实力的确无法解决,任务需要多种能力、独立验证或动态路由,精心编排的智能体团队是目前见过的最可靠的解法。
by Prakash Sharma