
在这篇文章中,你将了解自编码器是如何工作的,以及为什么它们被用于医学图像去噪。
正确理解图像信息在医学等领域是至关重要的。去噪可以集中在清理旧的扫描图像上,或者有助于癌症生物学中的特征选择。噪音的存在可能会混淆疾病的识别和分析,从而导致不必要的死亡。因此,医学图像去噪是一项必不可少的预处理技术。
所谓的自编码器技术已被证明是非常有用的图像去噪。
自编码器由编码器模型和解码器模型两个相互连接的人工神经网络组成。自动编码器的目标是找到一种将输入图像编码为压缩格式(也称为潜在空间)的方法,使解码后的图像版本尽可能接近输入图像。
Autoencoders如何工作
该网络提供了原始图像x,以及它们的噪声版本x~。该网络试图重构其输出x ',使其尽可能接近原始图像x。通过这样做,它学会了如何去噪图像。
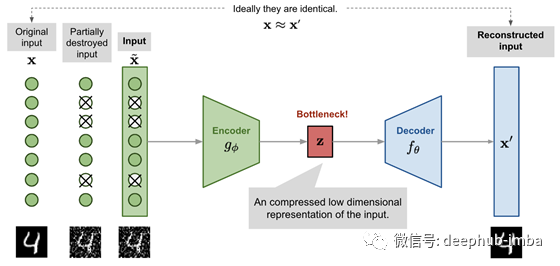
如图所示,编码器模型将输入转换为一个小而密集的表示。解码器模型可以看作是一个生成模型,它能够生成特定的特征。
编码器和解码器网络通常作为一个整体进行训练。损失函数判断网络创建的输出x '与原始输入x的差别。
通过这样做,编码器学会了在有限的潜在空间中保留尽可能多的相关信息,并巧妙地丢弃不相关的部分,如噪声。解码器学习采取压缩潜在信息,并重建它成为一个完全无错误的输入。
如何实现自动编码器
让我们实现一个自动编码器去噪手写数字。输入是一个28x28的灰度图像,构建一个784个元素的向量。
编码器网络是一个由64个神经元组成的稠密层。因此,潜在空间将有维数64。该层中的每个神经元上都附加了一个ReLu激活函数,根据每个神经元的输入是否与自编码器的预测相关,决定该神经元是否应该被激活。激活函数还有助于将每个神经元的输出规整为1到0之间的范围。
解码器网络是由784个神经元组成的单一致密层,对应28x28灰度化输出图像。sigmoid激活函数用于比较编码器输入和解码器输出。
采用二元交叉熵作为损失函数,Adadelta作为最小化损失函数的优化器。
import keras
from keras.layers import Input, Dense
from keras.models import Model
from keras.datasets import mnist
import numpy as np
# input layer
input_img = Input(shape=(784,))
# autoencoder
encoding_dim = 32
encoded = Dense(encoding_dim, activation='relu')(input_img)
encoded_input = Input(shape=(encoding_dim,))
decoded = Dense(784, activation='sigmoid')(encoded)
autoencoder = Model(input_img, decoded)
decoder_layer = autoencoder.layers[-1]
decoder = Model(encoded_input, decoder_layer(encoded_input))
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
MNIST数据集是一个著名的手写数字数据库,广泛用于机器学习领域的训练和测试。我们在这里使用它产生合成噪声数字应用高斯噪声矩阵和剪切图像之间的0和1。
import matplotlib.pyplot as plt
import random
%matplotlib inline
# get MNIST images, clean and with noise
def get_mnist(noise_factor=0.5):
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
return x_train, x_test, x_train_noisy, x_test_noisy, y_train, y_test
x_train, x_test, x_train_noisy, x_test_noisy, y_train, y_test = get_mnist()
# plot n random digits
# use labels to specify which digits to plot
def plot_mnist(x, y, n=10, randomly=False, labels=[]):
plt.figure(figsize=(20, 2))
if len(labels)>0:
x = x[np.isin(y, labels)]
for i in range(1,n,1):
ax = plt.subplot(1, n, i)
if randomly:
j = random.randint(0,x.shape[0])
else:
j = i
plt.imshow(x[j].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
plot_mnist(x_test_noisy, y_test, randomly=True)

你还能认出数字,但有些几乎认不出来。因此,我们想使用我们的自动编码器学习恢复原始数字。我们通过拟合超过100个epoch的自编码器,同时使用噪声数字作为输入,原始去噪数字作为目标。
因此,自编码器将最小化噪声和干净图像之间的差异。通过这样做,它将学会如何从任何看不见的手写数字中去除噪声,产生了类似的噪声。
# flatten the 28x28 images into vectors of size 784.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
x_train_noisy = x_train_noisy.reshape((len(x_train_noisy), np.prod(x_train_noisy.shape[1:])))
x_test_noisy = x_test_noisy.reshape((len(x_test_noisy), np.prod(x_test_noisy.shape[1:])))
#training
history = autoencoder.fit(x_train_noisy, x_train,
epochs=100,
batch_size=128,
shuffle=True,
validation_data=(x_test_noisy, x_test))
# plot training performance
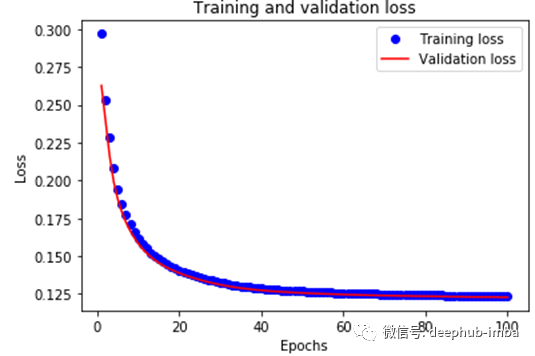
def plot_training_loss(history):
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plot_training_loss(history)
如何用自编码器去噪
现在我们可以使用经过训练的自动编码器来清除不可见的噪声输入图像,并将它们与被清除的图像进行对比。
# plot de-noised images
def plot_mnist_predict(x_test, x_test_noisy, autoencoder, y_test, labels=[]):
if len(labels)>0:
x_test = x_test[np.isin(y_test, labels)]
x_test_noisy = x_test_noisy[np.isin(y_test, labels)]
decoded_imgs = autoencoder.predict(x_test)
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test_noisy[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
return decoded_imgs, x_test
decoded_imgs_test, x_test_new = plot_mnist_predict(x_test, x_test_noisy, autoencoder, y_test)

总的来说,噪音被很好地消除了。人工输入图像上的白点已经从清洗后的图像中消失。这些数字可以被视觉识别。例如,有噪声的数字' 4 '根本不可读,现在,我们可以读取它的清洁版本。去噪对信息质量有不利影响。重建的数字有点模糊。解码器添加了一些原始图像中没有的特征,例如下面的第8位和第9位数字几乎无法识别。
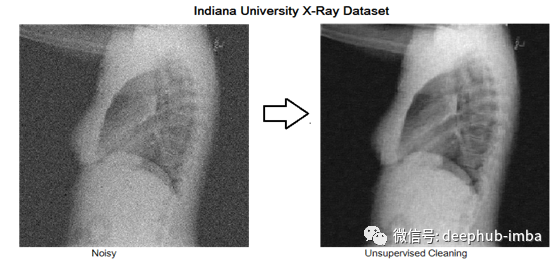
在本文中,我描述了一种图像去噪技术,并提供了如何使用Python构建自动编码器的实用指南。放射科医生通常使用自动编码器去噪MRI、US、x射线或皮肤病变图像。这些自动编码器是在大型数据集上训练的,比如印第安纳大学的胸部x射线数据库,其中包含7470张胸部x射线图像。去噪自动编码器可以通过卷积层来增强,以产生更有效的结果。
作者:Michel Kana, Ph.D
原文地址:https://towardsdatascience.com/autoencoder-for-denoising-images-7d63a0831bfd
deephub翻译组