
绝大多数 RAG 系统把检索当作不会出错的环节,无论拿到的文档是否真正切题,都会径直送入生成器。
"CRAG 提出了标准 RAG 从未追问的问题:如果检索器出错了,该怎么办?"
"不加甄别地引入检索文档,无论其是否相关,都会主动误导生成器,让 RAG 的表现甚至不如不做检索。
CRAG 详解
CRAG 引入了一个轻量级检索评估器,对给定查询所检索到的文档集合给出三种置信度判定之一。
得分达到 UPPER_TH 及以上时判定为"正确":至少有一篇文档具有足够相关性,进入知识精炼流程,将文档拆解为句子级片段,过滤掉无关内容,再将保留下来的部分重组为干净的知识(k_in)。得分在 LOWER_TH 以下则判定为"错误":所有本地文档均不相关,全部丢弃,查询被改写后转入网络搜索,以搜索结果作为外部知识(k_ex)。两个阈值之间的区域称为"模糊",质量不确定,同时使用 k_in 与 k_ex 作为上下文,在两个来源之间对冲风险。
模糊路径是论文中细节最丰富的部分,也是工程实现中最容易被跳过的部分。当评估器拿不准时,同时采信两个来源是最稳妥的策略,但这并不等同于"无条件双源并用"——触发条件明确限定在置信度真正偏低的场景。
分解-再重组算法
即便一篇文档被判定为"正确",其中仍可能夹带大量无关内容。以保险政策文件为例:某一页直接描述理赔程序,其余许多页却充斥着行政样板文字与其他险种的条款定义。CRAG 针对这一问题设计了句子级精炼算法:
- 分解:将每篇检索文档拆分为独立的句子(片段)。
- 过滤:对每个片段评估其与具体查询的相关性,丢弃低于阈值的片段。
- 重组:将保留下来的片段按原始顺序拼接为连贯的上下文字符串。
经过这道处理,送入生成器的上下文不仅体积更小,信息密度也更高——即便文档整体上是相关的,其中的无关句子也不会对生成过程构成干扰。
在原论文中,片段级别的评分由经过微调的 T5 模型完成。本文的代码实现中,片段评分与其他所有评估任务共用同一个 LLM,以少量评分精度的损失换取更简洁的运维结构和更少的模型依赖。
架构图
下图直接取自 CRAG 论文,看图是了解整个系统设计最直接的方式。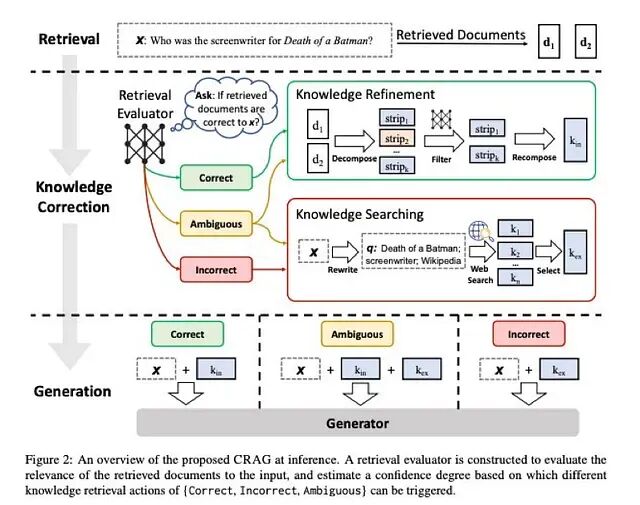
推理阶段的 CRAG 框架。对检索到的文档 d₁ 和 d₂ 进行评估,所得置信度触发三种知识检索动作之一,随后上下文才会被送入生成器。
逐步解读架构图
- 顶行(检索):输入问题 x,检索器返回文档 d₁ 和 d₂,这是未经过滤的原始结果。
- 中间左侧(检索评估器):评估器判断"检索到的文档对于 x 是否正确",给出置信度得分,分流至正确(绿色)、模糊(橙色)或错误(红色)路径。
- 中间右侧,知识精炼(绿色框):正确路径下,d₁ 和 d₂ 被分解为 strip₁、strip₂……strip_ₙ;过滤器剔除无关片段(图中以 ✗ 表示),保留部分重组为 k_in(内部知识)。
- 中间右侧,知识搜索(红色框):错误路径下,x 被改写为搜索查询 q(例如"Death of a Batman; screenwriter; Wikipedia"),网络搜索返回 k₁……k_ₙ,筛选后得到 k_ex(外部知识)。
- 底行(生成):生成器接收 x 与对应知识,正确路径为 x + k_in,模糊路径为 x + k_in + k_ex,错误路径为 x + k_ex。原始未过滤的 d₁/d₂ 绝不会直接到达生成器。
生成器位于质量关卡的下游。送达它的知识,必然经过评估、过滤或外部来源的验证。上下文污染在正确实现的 CRAG 系统中,从架构层面便无从发生。
实现
构建 CRAG:逐节点解析
本文实现遵循论文中的架构:七个节点,一个条件分支,无循环。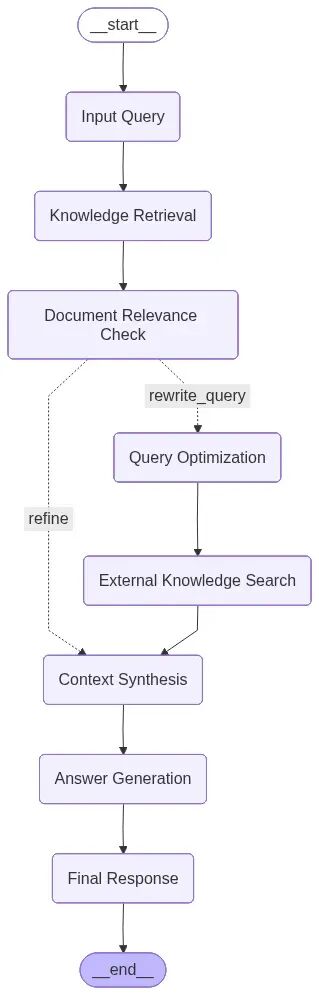
已编译的 CRAG LangGraph 图直接由 app.get_graph().draw_mermaid_png() 生成。文档相关性检查节点是唯一的条件分支点,两条路径在上下文综合节点汇合,随后进入答案生成。
状态模式(State Schema)
LangGraph 需要一个 TypedDict 作为所有节点之间的共享内存,每个节点从中读取状态并返回部分更新。
class State(TypedDict):
question: str # 原始用户问题,始终不修改
docs: List[Document] # 原始检索的 top-k 块
good_docs: List[Document]# 通过评估器的块
verdict: str # CORRECT | INCORRECT
reason: str # 评估器的推理过程(用于日志记录)
strips: List[str] # 句子级别的分解片段
kept_strips: List[str] # 通过相关性过滤的片段
refined_context: str # 送入生成器的最终组合上下文
web_query: str # 改写后用于 Google 搜索的查询
web_docs: List[Document] # Google Custom Search 的返回结果
answer: str # 最终生成的答案
节点:知识检索
接收用户问题,查询 FAISS 向量存储,返回前 4 个块。
# 数据摄入(在启动时运行一次)
chunks = RecursiveCharacterTextSplitter(
chunk_size=900, chunk_overlap=150
).split_documents(docs)
retriever = FAISS.from_documents(chunks, embeddings)
.as_retriever(search_kwargs={'k': 4})
def retrieve_node(state: State):
docs = retriever.invoke(state['question'])
return {'docs': docs}
节点:文档相关性检查
这是整个架构的核心节点。每篇检索文档都会获得一个连续置信度得分(0.0–1.0),得分超过 UPPER_TH(0.7)的文档进入 good_docs。若 good_docs 非空,则 verdict = CORRECT;否则 verdict = INCORRECT,流程升级至网络搜索。
UPPER_TH = 0.7 # 论文推荐的"正确"阈值
LOWER_TH = 0.3 # 低于此值 = 错误(中间值 = 模糊)
class DocEvalScore(BaseModel):
score: float # 0.0–1.0 置信度
reason: str # 简短说明(记录用于调试)
# system prompt 中的评分标准:
# 1.0 → 用具体细节直接回答查询
# 0.7-0.9 → 中度相关,有用的相关信息
# 0.4-0.6 → 轻微相关
# 0.0-0.3 → 不相关,与查询无关联
def eval_each_doc_node(state: State):
good_docs = []
for i, doc in enumerate(state['docs'], start=1):
decision = doc_eval_llm.invoke(
doc_eval_prompt.format_messages(
question=state['question'], doc=doc.page_content
)
)
if decision.score >= UPPER_TH:
good_docs.append(doc)
verdict = 'CORRECT' if good_docs else 'INCORRECT'
return {'good_docs': good_docs, 'verdict': verdict}
为什么采用连续得分而非直接分类?阈值由此变为一个可调的配置项,调整判定标准无需动提示词。在保险这类高精度场景中,把 UPPER_TH 从 0.7 提到 0.85 只需改一个常量,策略与机制分离是这里更重要的设计原则。
节点:查询优化
仅在 INCORRECT 路径下激活,将用户的自然语言问题改写为关键词密集的网络搜索查询。改写逻辑具备明确的领域意识:展开缩写、补充专业术语、剥离口语化措辞。
class WebQuery(BaseModel):
query: str
# 提示词中内置的改写示例:
# 'How does CI claims work?'
# → 'critical illness insurance claim settlement process requirements'
# 'What are the benefits of life insurance?'
# → 'life insurance policy benefits coverage sum assured'
def rewrite_query_node(state: State):
decision = rewrite_llm.invoke(
rewrite_prompt.format_messages(question=state['question'])
)
return {'web_query': decision.query}
节点:外部知识搜索
调用 Google Custom Search API,将每条摘要片段封装为 LangChain Document。统一的 Document 接口让下游的上下文综合节点得以用相同逻辑处理本地文档与网络来源——两条路径在此完全对称。
def web_search_node(state: State):
params = {
'key': os.getenv('GOOGLE_API_KEY'),
'cx': os.getenv('GOOGLE_CSE_ID'),
'q': state['web_query']
}
r = requests.get('https://www.googleapis.com/customsearch/v1',
params=params)
web_docs = [
Document(page_content=item['snippet'])
for item in r.json().get('items', [])
]
return {'web_docs': web_docs}
节点:上下文综合
为生成器组装最终上下文。逻辑简单,影响深远。
def refine(state: State):
# CORRECT 路径:使用本地评估通过的 good_docs
# INCORRECT 路径:使用 web_docs(此时 good_docs 为空)
# 完整 CRAG:模糊路径将同时使用两者
docs = state['good_docs'] or state['web_docs']
context = '\n\n'.join([d.page_content for d in docs])
return {'refined_context': context}
一个真实查询示例
测试查询:"SecureLife 重疾险的理赔结算流程是什么?"
[输入查询 → 知识检索] 通过 FAISS 从保险语料库中检索出 4 个块。
[文档相关性检查]
- 文档 1 → 0.92(重疾险理赔程序——直接相关)
- 文档 2 → 0.78(理赔材料要求——相关)
- 文档 3 → 0.41(一般健康保险概述——轻微相关)
- 文档 4 → 0.18(车险免责条款——不相关)
裁定:CORRECT。4 篇文档中有 2 篇通过,直接路由至上下文综合。
[上下文综合] 仅由文档 1 和文档 2 组装上下文,车险与通用健康险内容被丢弃,生成器收到的是 2 个聚焦的相关块。
[答案生成 → 最终回复] 生成结果列出所需材料(病历报告、诊断证明、主治医生证明)、结算时间线(完整材料提交后 90 天内)以及两阶段审批流程。
没有文档过滤时,生成器会收到车险免责条款块(文档 4,得分 0.18)作为上下文。行为稳定的模型可能将其忽略,但压力下的模型往往会尝试从中提取信息,最终输出一个将重疾险与车险理赔程序混为一谈的错误答案。CRAG 在架构层面堵死了这条路。
本文代码:https://github.com/bhavyameghnani/Corrective-RAG-Self-Reflective-RAG
by Bhavya Meghnani