
LangGraph 设计的一个核心是:多智能体工作流本质上是图结构,而非线性链。早期 LLM 应用普遍采用"提示 → LLM → 响应"的线性模式,但这种架构难以应对真实智能体系统的复杂性。比如生产环境中的多智能体协作需要分支(基于数据选择不同执行路径)、循环(支持重试与迭代优化)、汇合(多个智能体向共享状态写入数据),以及条件路由(根据执行结果动态决定后续流程)。
LangGraph 如何表示工作流
LangGraph 里每个工作流都是一个 StateGraph——本质上是有向图。节点就是智能体,或者说处理状态的函数;边是智能体之间的转换;状态则是在整个图中流动的共享数据结构。
from langgraph.graph import StateGraph, END
from typing import TypedDict
# Define your state schema
class IncidentState(TypedDict):
incident_id: str
current_metrics: dict
proposed_solution: dict
issue_resolved: bool
retry_count: int
# Create the graph
workflow = StateGraph(IncidentState)
# Add agent nodes
workflow.add_node("diagnose", diagnose_agent)
workflow.add_node("plan_fix", planning_agent)
workflow.add_node("execute_fix", worker_agent)
workflow.add_node("verify", verification_agent)
# Define transitions
workflow.add_edge("diagnose", "plan_fix")
workflow.add_edge("plan_fix", "execute_fix")
workflow.add_edge("execute_fix", "verify")
# Conditional: retry or exit
workflow.add_conditional_edges(
"verify",
lambda state: "resolved" if state["issue_resolved"] else "retry",
{
"resolved": END,
"retry": "diagnose" # Loop back
}
)
workflow.set_entry_point("diagnose")
这样做的好处非常明显:图本身就可以当作开发文档文档,一眼能看懂流程;加减节点不用动协调逻辑;状态有类型约束;循环有内置的终止条件,不会跑成死循环。
节点、边、状态三者各司其职。节点封装具体的逻辑操作,只管做事;边定义节点间怎么交互、谁先谁后;状态承载共享上下文,让节点可以保持无状态。这种职责分离让系统好理解、好调试、好扩展,节点还能跨工作流复用。
运行时到底发生了什么
图定义是声明式的,但真正让编排变得有意义的是运行时行为。
工作流启动后,LangGraph 用状态机来管理执行。首先从入口节点的初始状态开始,然后调用智能体函数并传入当前状态。智能体返回的是增量更新而不是整个状态的替换,LangGraph 拿到更新后原子性地合并到当前状态,接着根据图定义决定下一个节点,同时创建检查点把当前状态和执行位置持久化下来。这个过程一直重复,直到走到 END 节点或者达到最大迭代次数。
有一点很关键:智能体永远不会直接改共享状态。它们拿到的是只读副本,算完之后返回更新,实际的状态修改由 LangGraph 来做,可以保证了原子性和一致性。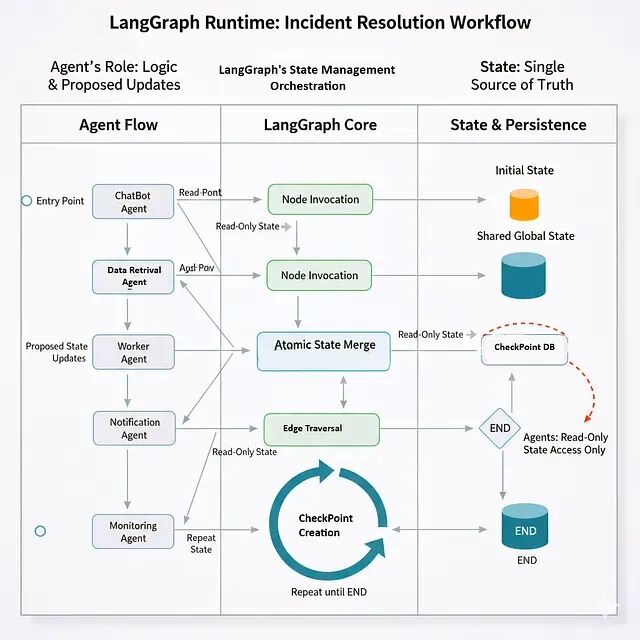
边遍历机制
边定义了哪些转换是允许的,但具体什么时候转换由运行时决定。
静态边没什么花样:
workflow.add_edge("diagnose", "plan_fix")
diagnose 节点跑完、检查点创建好之后,LangGraph 立刻拿更新后的状态去调 plan_fix。
条件边就灵活多了:
workflow.add_conditional_edges(
"verify",
route_function,
{"retry": "diagnose", "resolved": END}
)
verify 完成后,LangGraph 调用 route_function(state) 来判断下一步走哪条边。函数返回 retry 就回到 diagnose,返回 resolved 就结束。
任何节点在执行前它的所有前置节点必须已经完成并创建了检查点,这就避免了 Pub/Sub 系统里常见的那种"前面还没跑完后面就开始了"的问题。
状态管理的特殊之处
LangGraph 的状态跟传统系统不太一样。
它不是存在 Redis 或数据库里让智能体直接访问的共享内存。LangGraph 在内部维护状态,给智能体的是受控访问。对智能体来说状态是不可变的——拿到的是快照,不能直接改,只能返回想要的变更。
多个智能体并行跑的时候(通过并行边),LangGraph 收集所有更新,用 reducer 原子性地一起应用。读-修改-写的竞态条件就这么解决了。
每个检查点还会创建一个状态版本。想看执行历史中任意时刻的状态?直接查检查点就行,这就是所谓的时间旅行调试。
检查点持久化
检查点不只是日志,它们是恢复点。
每个检查点记录完整的状态快照、当前在图中的位置(刚执行完哪个节点)、还有元数据(时间戳、创建检查点的节点、执行路径)。
创建时机有三个:每个节点成功完成后、条件边评估前、以及工作流暂停时(比如等人工审批)。
这样如果节点执行到一半崩了,可以从最后一个检查点重试就行;长时间运行的工作流可以暂停再恢复,进度不会丢;调试的时候能从任意检查点开始重放。
一个完整的运行时示例
假设用户发起请求:"修复服务延迟问题"。
T0: Workflow starts
- Initial state: {incident_id: "INC-123", retry_count: 0}
- Entry point: "diagnose"
T1: "diagnose" node executes
- Receives: {incident_id: "INC-123", retry_count: 0}
- Agent calls Data Agent, fetches metrics
- Returns: {current_metrics: {cpu: 95, latency: 500ms}}
- LangGraph merges: state now has metrics
- Checkpoint created
T2: Static edge triggers: "diagnose" → "plan_fix"
- "plan_fix" node executes
- Receives merged state (incident_id + retry_count + current_metrics)
- Agent calls Knowledge Agent for runbook
- Returns: {proposed_solution: "restart_service"}
- LangGraph merges
- Checkpoint created
T3: Static edge triggers: "plan_fix" → "execute_fix"
- "execute_fix" node executes
- Calls Worker Agent
- Returns: {action_status: "completed"}
- Checkpoint created
T4: Static edge triggers: "execute_fix" → "verify"
- "verify" node executes
- Calls Data Agent again
- Returns: {current_metrics: {cpu: 90, latency: 480ms}, issue_resolved: false}
- Checkpoint created
T5: Conditional edge evaluation
- LangGraph calls route function with current state
- route_function checks: state["issue_resolved"] == false and retry_count < 3
- Returns: "retry"
- LangGraph increments retry_count
- Routes back to "diagnose" (cycle)
T6: "diagnose" executes again (retry [#1](#1))
- Process repeats with updated state...
状态在节点间累积——指标、方案、操作结果都在里面。每个节点都能看到之前所有节点产出的完整信息。重试逻辑是图结构强制的,不是写在智能体代码里。出了故障检查点可以让程序随时恢复运行。
用 LangGraph 的话,智能体只管返回自己的更新。协调、状态合并、路由、持久化,运行时全包了。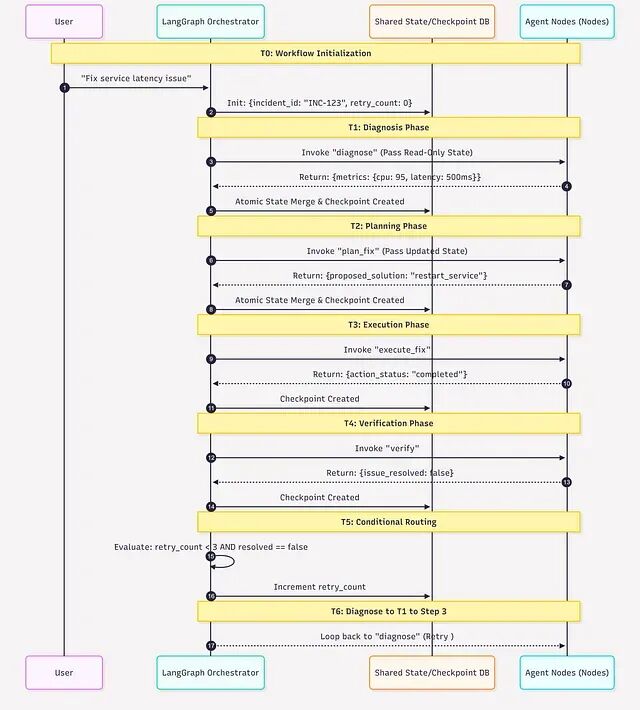
关键架构模式
传统多智能体系统喜欢累积对话历史:
# Common pattern - append-only log
messages= [
{"role": "user", "content": "Service X is slow"},
{"role": "data", "content": "CPU at 95%"},
{"role": "knowledge", "content": "Try restarting"},
{"role": "action", "content": "Restarted service"},
...
]
这东西会无限增长,智能体每次都得在历史里翻来翻去找有用的数据。
LangGraph 换了个思路,状态就是当前世界的快照:
classState(TypedDict):
# Current values, not history
incident_id: str
current_cpu: float
recommended_action: str
action_status: str
retry_count: int
智能体读当前值、更新当前值。历史通过检查点单独维护,调试用得着,但工作状态保持精简。访问状态 O(1),不用解析历史;数据所有权清晰,一眼看出哪个字段归谁管;推理也简单,当前状态是啥就是啥。
Reducer 解决并行协调
多个智能体要往同一个状态字段写数据怎么办?LangGraph 提供 reducer——专门合并并发更新的函数。
传统 A2A 模型里,智能体得自己搞协调:抢锁、读-修改-写、重试、冲突检测。这套东西各团队实现得五花八门,一旦出现部分故障就容易出问题。Reducer 把冲突解决挪到编排层,智能体级别的协调逻辑直接省掉。
比如说下面的例子,三个监控智能体并行检查不同的服务副本:
fromtypingimportAnnotated
fromoperatorimportadd
classState(TypedDict):
# Reducer: combine all health check results
health_checks: Annotated[list, add]
三个 Data Agent 各自返回健康检查结果,reducer(这里就是列表的 add 操作)自动把三份结果合成一个列表。没有智能体需要知道其他智能体的存在,不用抢锁,不用协调更新。
没有 reducer 的话,需要手动加锁防覆盖、写协调逻辑合并结果、还得担心更新丢失。有了 reducer,编排层自动处理。
检查点用于调试和恢复
每次节点执行都会创建检查点,状态和执行位置的快照会持久化到 Postgres、Redis 或文件系统。
生产环境出故障了?可以检查检查点的内容,看看每个智能体观察到了什么、做了什么决定。这相当于给智能体工作流装了黑匣子,决策链条一清二楚。
服务器中途崩了也可以从最后一个检查点恢复,不用从头来。对那些要调用昂贵 API 或者收集大量数据的长时间任务来说,这太重要了。
而且工作流可以暂停几小时甚至几天,状态通过检查点保持现有状态,从暂停的地方精确恢复,上下文完整保留。
修改工作流的灵活性
LangGraph的另外一个卖点是工作流改起来容易。
假设初始工作流是 Diagnose → Fix → Verify,现在要加个需求:"修复之前先查一下 Jira 有没有已知问题"。
代码改动就这么点:
# Add the new agent
workflow.add_node("check_jira", jira_agent)
# Rewire the flow
workflow.add_edge("diagnose", "check_jira") # New path
workflow.add_conditional_edges(
"check_jira",
lambda state: "known_issue" if state["jira_ticket"] else "unknown",
{
"known_issue": "apply_known_fix", # New path
"unknown": "plan_fix" # Original path
}
)
单个智能体的实现不用动,状态协调逻辑不用动,检查点处理不用动,错误恢复不用动。
如果换成换成 Pub/Sub 呢?事件路由逻辑要改,完成跟踪要改(现在是 4 个智能体不是 3 个了),状态模式协调要改,所有集成点都得重新测。
再看重试逻辑的修改。原来是最多重试 3 次:
# Before
workflow.add_conditional_edges(
"verify",
lambda state: "retry" if state["retry_count"] < 3 else "end",
{"retry": "diagnose", "end": END}
)
新需求:"只有临时性错误(网络问题)才重试,永久性错误(配置问题)不重试"。改条件函数就行:
# After - just change the condition function
def should_retry(state):
if state["issue_resolved"]:
return "success"
if state["error_type"] == "config":
return "escalate" # Don't retry config errors
if state["retry_count"] >= 3:
return "max_retries"
return "retry"
workflow.add_conditional_edges(
"verify",
should_retry,
{
"success": END,
"retry": "diagnose",
"escalate": "human_review",
"max_retries": "alert_team"
}
)
业务逻辑在工作流结构里一目了然,改起来也顺手。
LangGraph 支持的典型模式
生成的方案不够好,可以直接加个循环:
workflow.add_node("generate_solution", llm_agent)
workflow.add_node("validate_solution", validation_agent)
workflow.add_node("refine_solution", refinement_agent)
workflow.add_conditional_edges(
"validate_solution",
lambdastate: "valid"ifstate["solution_quality"] >0.8else"refine",
{
"valid": "execute_fix",
"refine": "refine_solution"
}
)
workflow.add_edge("refine_solution", "generate_solution") # Loop back
方案不断迭代,直到质量达标。
并行信息收集时需要同时从多个来源拉数据:
fromlanggraph.graphimportSTART
# Parallel nodes
workflow.add_node("fetch_metrics", data_agent)
workflow.add_node("fetch_logs", elasticsearch_agent)
workflow.add_node("fetch_config", knowledge_agent)
# All start in parallel
workflow.add_edge(START, "fetch_metrics")
workflow.add_edge(START, "fetch_logs")
workflow.add_edge(START, "fetch_config")
# All must complete before analysis
workflow.add_node("analyze", analysis_agent)
workflow.add_edge("fetch_metrics", "analyze")
workflow.add_edge("fetch_logs", "analyze")
workflow.add_edge("fetch_config", "analyze")
LangGraph 保证 analyze 节点在三个数据源都拿完之后才开始跑。
高风险操作需要人来进行确认:
workflow.add_node("propose_fix", planning_agent)
workflow.add_node("await_approval", approval_gate)
workflow.add_node("execute_fix", action_agent)
workflow.add_edge("propose_fix", "await_approval")
# Workflow pauses at await_approval
# State is persisted
# When human approves, workflow resumes
workflow.add_conditional_edges(
"await_approval",
lambdastate: "approved"ifstate["human_approved"] else"rejected",
{
"approved": "execute_fix",
"rejected": "propose_alternative"
}
)
这个确认过程可以等几小时甚至几天,不消耗任何的资源。
什么场景适合 LangGraph
复杂工作流(5 个以上智能体、有条件逻辑、有循环)、业务逻辑经常变、需要事后调试分析、有人工审批或质量门控、长时间任务需要崩溃恢复——这些场景 LangGraph 很合适。
简单的线性流程(A → B → C,没分支)、智能体完全独立不需要协调、对延迟极度敏感(编排开销要控制在 10ms 以内)、或者团队有深厚的分布式系统功底想自己搞状态机——这些场景替代方案也挺好。
总结
编排框架在复杂系统中的价值已经被反复验证:Kubernetes 之于容器、Airflow 之于数据管道、Temporal 之于通用工作流。LangGraph 将同样的理念带入多智能体 AI 领域,提供了 LLM 感知的编排能力。
其核心价值在于:图结构让工作流易于修改和扩展,检查点机制保障了可调试性和故障恢复,reducer 和原子状态更新解决了并行协调难题。开发者可以专注于智能体逻辑本身,而非协调管道的实现细节。
对于正在构建多智能体系统的团队,LangGraph 提供了一条从实验原型到生产系统的可行路径。
作者:ravikiran veldanda