
选择正确的损失函数对于训练机器学习模型非常重要。不同的损失函数适用于不同类型的问题。本文将总结一些常见的损失函数,并附有易于理解的解释、用法和示例
均方误差损失(MSE)
loss_fn = nn.MSELoss()py
均方误差(Mean Squared Error,简称 MSE)损失是在监督学习中,特别是在回归问题中经常使用的一种损失函数。它计算了预测值与真实值之间差异的平方的平均值,用于衡量模型预测的准确性。
MSE 损失的数学表达式定义如下:
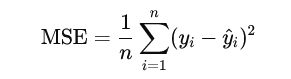
由于误差被平方,因此较大的误差会受到更重的惩罚。这有助于模型在训练过程中减少较大的预测误差。MSE 损失函数在整个定义域上连续可微,这一特性使得使用基于梯度的优化算法(如梯度下降法)求解时更加高效。
MSE 的计算公式简单,实现起来容易,计算效率高。
平均绝对误差损失(MAE)
loss_fn = nn.L1Loss()
平均绝对误差(Mean Absolute Error,简称 MAE)损失是在统计学和机器学习中常用于回归问题的另一种损失函数。MAE 损失计算了预测值与真实值之间差异的绝对值的平均,提供了一个对模型预测偏差的直观度量。与MSE相比,它对大误差的敏感性较低。
MAE 损失的数学表达式定义如下:
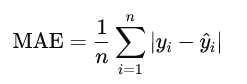
与 MSE 相比,MAE 对异常值或离群点的影响较小。这是因为它不对误差进行平方,因此较大的误差不会对总体损失产生过大的影响。MAE 直接反映了平均每个样本预测误差的绝对量,易于理解和解释。
MAE 在误差为零的点不可微,这可能使得基于梯度的优化方法在找到最优解时遇到困难。
Huber损失(平滑L1损失)
loss_fn = nn.SmoothL1Loss()
Huber Loss,又被称为 Smooth L1 Loss,是一种在回归任务中常用的损失函数,它是平方误差损失(squared loss)和绝对误差损失(absolute loss)的结合。这种损失函数主要用于减少异常值(outliers)在训练模型时的影响,从而提高模型的鲁棒性。
Huber Loss 函数通过一个参数 δ\deltaδ(delta)来定义,该参数决定了损失函数从平方误差向绝对误差转变的点。具体的数学表达式为:
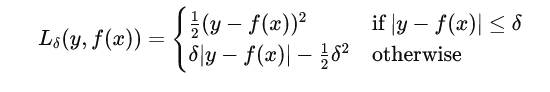
Huber Loss 通常用于回归问题,尤其是当数据中可能包含异常值时。它在金融、气象预测、机器人导航等领域找到了广泛的应用,这些领域中的预测任务常常需要对异常值具有较高的容忍度。
交叉熵损失(Cross-Entropy Loss)
loss_fn = nn.CrossEntropyLoss()
交叉熵损失(Cross-Entropy Loss),在机器学习领域,尤其是分类问题中,扮演了重要的角色。它主要用于衡量两个概率分布之间的差异,通常用于评估模型预测的概率分布与实际标签的概率分布之间的距离。
对于二分类问题,交叉熵损失可以定义为:
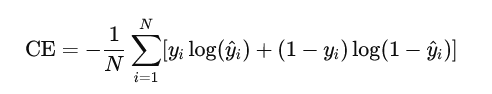
交叉熵损失直接对模型输出的概率进行优化,使模型学习产生接近真实标签的概率分布。当模型的预测错误且置信度高时,交叉熵损失会给予更大的惩罚,反之则减少惩罚,这种特性使得训练过程更加高效。在实现时,通常会结合 softmax 函数和对数函数的数值稳定技术,以避免计算中的下溢或上溢问题。
交叉熵损失广泛应用于各种分类任务,如图像识别、文本分类和医学诊断等。它特别适合于处理输出为概率分布的场景,能够有效地推动模型在预测准确性和概率校准方面的性能。
二元交叉熵损失 (BCE)
loss_fn = nn.BCELoss()
二元交叉熵损失(Binary Cross-Entropy Loss,简称 BCE)是交叉熵损失在二分类问题中的特定形式,它用于衡量模型预测的概率与实际标签之间的差异。BCE 损失在处理只有两个类别(通常标记为0和1)的分类任务时非常常见和有效。
二元交叉熵损失的公式定义如下: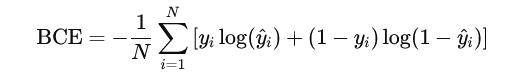
BCE 损失直接优化模型输出的概率,使其尽可能接近实际的标签。这种优化帮助提升模型在概率预测的准确性。当预测的概率与实际标签差距较大时,损失会显著增加,从而使模型快速学习调整这些预测。这种特性使得模型在训练初期能快速改进其错误预测。实现时,为了避免计算中的数值问题(如对数函数的输入为0),通常结合使用sigmoid 函数。
BCE 损失广泛用于各种需要进行二分类的机器学习任务中,包括医疗影像分析、邮件垃圾分类、在线广告点击预测等。在这些场景中,预测是否属于某一类别(是或否)是核心任务。
在使用 BCE 损失时,标签值必须严格为0或1,因为对数函数在计算时要求输入必须位于(0,1)区间内。
二元交叉熵损失加对数损失
loss_fn = nn.BCEWithLogitsLoss()
二元交叉熵损失加对数(Binary Cross-Entropy with Logits Loss,通常简称为 BCE with Logits Loss)是一种结合了二元交叉熵损失和逻辑斯蒂(sigmoid)激活函数的损失函数。这种损失函数常用于二分类问题中,尤其是当模型的输出还未通过sigmoid函数转换为概率时。
这个损失函数直接在一个步骤中处理了模型的原始输出(也称为logits)和真实标签之间的交叉熵,避免了先将logits转换为概率再计算损失的复杂度。其公式如下:
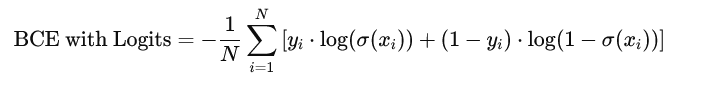
这个损失函数通过结合sigmoid激活和对数损失计算来改进数值稳定性,减少计算中可能出现的数值问题(如对数函数输入接近0或1时的数值不稳定)。直接在一个公式中处理logits,避免了单独使用sigmoid函数和交叉熵损失可能引入的额外计算开销。适用于任何需要输出概率预测的二分类模型,尤其是在深度学习中,这种损失函数被广泛用于训练二分类神经网络。
与BCE Loss类似,使用BCE with Logits Loss时,标签yi需要严格为0或1
Kullback-Leibler Divergence Loss (KLDivLoss)
loss_fn = nn.KLDivLoss()
Kullback-Leibler Divergence(简称 KL 散度或 KL Divergence),在机器学习中通常用作损失函数,称为 KLDiv Loss。它是用来衡量两个概率分布之间差异的一种方法。在许多机器学习任务中,特别是在涉及概率分布、生成模型或信息理论的领域,KL 散度都有着重要的应用。
KL 散度用于测量两个概率分布 P 和 Q 之间的不相似性。对于离散概率分布,其表达式为:
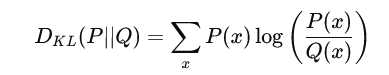
对于连续概率分布,则表达为:
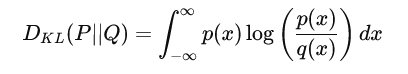
KL 散度是非对称的,在概率模型中,KL 散度可以用来衡量模型预测分布与真实分布之间的差异,常用于生成模型(如变分自编码器)的训练。KL 散度从信息论的角度解释为由于知道真实分布 P而不是预测分布 Q而获得的信息增益。
在机器学习中,特别是在生成模型如 GANs 和 VAEs 中,KL 散度用来确保生成的分布尽可能接近真实数据分布。在语言模型中,通过最小化模型分布与实际数据分布之间的 KL 散度,来优化模型。在文档分类或聚类中,使用 KL 散度来度量文档之间的相似性。
相较于其他损失函数,如交叉熵,KL 散度在计算上可能更复杂,特别是在处理连续分布时。
负对数似然损失(Negative Log-Likelihood Loss)
loss_fn = nn.NLLLoss()
负对数似然损失(Negative Log-Likelihood Loss,简称 NLLLoss)是机器学习中一种常见的损失函数,尤其是在分类问题中与softmax函数结合使用时效果显著。它用于衡量模型输出概率分布与真实标签之间的匹配程度。
在分类任务中,NLLLoss 直接作用于模型的预测概率和真实标签。通常,该损失函数与 softmax 层一起使用,softmax 层用于将模型输出转化为概率分布。NLLLoss 的计算公式如下:
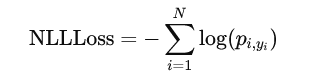
NLLLoss 通过最大化真实标签的预测概率来优化模型,有效地推动模型输出与目标标签的一致性。虽然 NLLLoss 常与分类任务关联,但它同样适用于任何涉及概率预测的场景,包括某些类型的回归任务。与交叉熵损失相比,当模型输出已是有效的概率分布时,使用 NLLLoss 可以省略将 logits 转化为概率的步骤,从而提高计算效率。
在多类分类问题中,NLLLoss 结合 softmax 层,常用于神经网络中,如图像分类、文本分类等。在使用 NLLLoss 之前,必须确保模型的输出是有效的概率值,即所有输出概率之和为1,且每个概率值都在0到1之间。
Hinge Loss
def hinge_loss(outputs, targets):
return torch.mean(torch.clamp(1 - outputs * targets, min=0))
Hinge Loss(铰链损失)是机器学习中常用于分类任务的一种损失函数,尤其是在支持向量机(SVM)中应用广泛。它旨在创建一个边界,该边界不仅能正确分类所有训练数据,而且能最大化边界与数据点之间的间隔。
在二分类问题中,Hinge Loss 的表达式通常定义为:
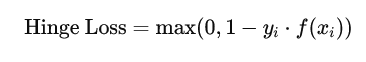
对于多类分类问题(多类SVM),Hinge Loss 可以扩展为:
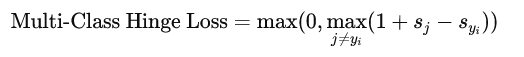
Hinge Loss 试图确保正确分类的同时,最大化最近的类别边界,这有助于提高模型的泛化能力。例如Hinge Loss 是训练SVM的标准损失函数,广泛用于各种二分类和多分类问题。在训练SVM时,Hinge Loss 倾向于产生稀疏的模型解,这是因为只有那些在边界上或分类错误的样本才会对损失函数有贡献。
Hinge Loss 是一个非光滑函数,这使得优化过程较为复杂,通常需要使用次梯度方法或其他专门的优化算法。由于 Hinge Loss 的非光滑特性,选择合适的优化算法(如SMO、次梯度下降)对于实现有效训练至关重要。
在使用 Hinge Loss 时,标签 yi必须是 +1 和 −1,这与一些其他损失函数使用 0 和 1的标签编码方式不同。
Hinge Loss 提供了一种在确保分类精度的同时最大化分类间隔的方法,特别适用于那些需要高鲁棒性分类器的应用场景。
总结
本文介绍了几种常用的机器学习损失函数,包括均方误差(MSE)、平均绝对误差(MAE)、交叉熵损失、二元交叉熵损失、带对数的二元交叉熵损失、Kullback-Leibler散度、负对数似然损失和铰链损失。这些损失函数在回归、分类和概率模型评估中有着广泛的应用,各有其优势和特定的应用场景。