
如果你在 ChatGPT、Claude 或 Gemini 里输入过一个问题但是发现:"这不是我的意思"——那你已经碰到了 prompt engineering 的核心问题。
模型没理解你的想法不是因为它笨,而是因为语言本身就充满歧义,AI 模型不像人,它读不了你的心思,没有共享的对话历史可以依赖,也不会在回答之前先追问你(至少不总是如此)。你输入里的每一个模糊点,都会变成模型帮你做的决定。
Prompt engineering 就是用来填这个坑的,它是一种和 AI 系统沟通的方法——表达得足够清晰、足够精确,让模型的第一反应就了解你的真实意图。
Prompt Engineering 到底是什么
Prompt engineering 是设计 AI 语言模型的输入,让输出可靠地符合预期。它一半是手艺,一半是科学——核心是理解模型怎么解读语言,然后做到精确表达。
核心公式:
清晰度+上下文+约束=一致的高质量输出
传统软件里输入和输出之间是确定性的映射关系,但大型语言模型(LLM)是概率性的。同一个问题换个说法,结果可能天差地别,Prompt engineering 就是你用来倾斜概率分布的手段。
换个角度理解:prompt 里每一个不够明确的词,都是模型从训练数据里帮你填空。这个填空在抽象层面可能完全合理,但放到你的具体场景里可能就跑偏了。
Prompt 的四大支柱
每个 prompt,不管简单还是复杂,都绕不开四个维度。
意图(Intent)
你希望模型做什么。意图越清晰,模型需要猜的部分就越少。猜得越多,错得越多。"写写气候变化"是一个意图;"为 2050 年海平面上升对沿海城市的经济影响写一份 200 字的执行摘要,面向非技术读者"——这才是精确的意图。
上下文(Context)
模型需要的背景信息,没有它模型就从最通用的训练数据里捞答案,技术上说可能没错,但对你没用。客服邮件和筹款邮件都是"邮件",各自需要的上下文天差地别。
格式(Format)
你希望输出长什么样?不指定的话,模型可能在你只需要一个列表时写出一大段文字,或者在你只需要一句话时给你整篇文章。提前说好格式,省得自己再整理。
约束(Constraints)
长度限制、语气要求、主题范围和受众限定——这些边界塑造了回答的质量。约束被低估的次数太多了,但它们和指令本身一样重要。
适用于每个 Prompt 的 6 条核心原则
1、具体
模糊的 prompt 只能得到模糊的回答。这是 AI 输出让人失望的头号原因。
对比一下:
- 模糊: "写点关于远程工作的内容。"
- 具体: "为工程经理写一篇 600 字的博客,主题是如何在全远程团队中维护团队文化。语气:实用、直接。包含 3 个具体策略,每个附简要理由。以一个 hook 开头,跳过空泛的开场白。"
第二个 prompt 限定了受众、长度、语气、结构和开头方式。模型没有需要猜测的部分,输出自然更贴合你的需求。
2、分配角色
告诉模型它"是谁",能从根本上改变回答的风格、深度和框架。这不只是表面工夫——它会激活特定领域知识和推理模式。
"解释这段法律条款"——得到的是一段泛泛的解释。"你是一名公司法律顾问,正在为创业公司创始人提供咨询。解释这段条款,标出我需要注意的风险"——得到的是带专业判断和实践导向的回答。
角色还可以叠加视角:"一个正在审查早期项目推介的 skeptical 风险投资人"——一个指令就同时拿到了专业知识和批判姿态。
3、给例子
例子是传达风格、语调和结构最快的方式。抽象描述很难,直接展示很容易。
这是 few-shot prompting 的核心:在正式任务之前,先给一到三个输入/输出的例子。给一两个正确格式的例子(再附一个错误格式的),比写几段说明文字有用得多。
4、要求逐步推理
碰到涉及逻辑、数学、多步骤分析或细微判断的复杂任务,明确要求模型先思考再回答。
"一步一步思考"或"在给出最终答案之前展示你的推理过程"——这迫使模型把逻辑过程亮出来,错误在半路就被逮住,而不是藏进最终答案。在推理密集的任务上,这一个指令就能大幅提高准确率。
5、 迭代
没有哪个 prompt 第一版就完美。Prompt engineering 是改稿子,不是施魔法。
先写个草稿,跑一次,看缺了什么、哪里不对。一次只改一个地方。用边界情况试。最好的 prompt 几乎总是第三版或第四版,不是第一版。像改文章一样:每过一遍,就更紧实一点。
6、使用正面指令
告诉模型该做什么,胜过只告诉它别做什么。负面指令让模型只能瞎猜替代方案。
- 负面: "不要用行话。"
- 正面: "用简单易懂的英语解释,让 14 岁的孩子也能听懂。"
正面指令给了模型一个明确的目标去瞄准,更清晰、更可执行,结果也更稳定。
完美 Prompt 的结构
一个完整、精心设计的 prompt 包含最多六个部分。当然不是每个 prompt 都需要全部——问个简单问题不需要太多框架。但知道完整的结构,意味着你清楚在出问题时往哪个方向加东西。
组件 1:角色(Role)
AI 应该"是谁"——设定人设、专业水平和语气。
示例: "你是一名经验丰富的 UX 研究员,在企业软件产品领域有 10 年工作经验。"
组件 2:任务(Task)
你希望完成什么。用清晰的动词陈述——分析、总结、重写、生成、比较、提取、翻译。
示例: "分析以下用户访谈记录,找出排名前三的痛点。"
组件 3:上下文(Context)
AI 需要知道的背景信息。包括受众、目的、相关约束以及已经完成的前期工作。
示例: "这是面向非技术高管的董事会演示。我们已经验证了产品市场匹配。"
组件 4:示例(Examples)
展示比告诉更有效。
示例: "这是我想要的语气:[example]。这是我不想要的:[counter-example]。"
组件 5:格式(Format)
输出的组织方式——标题、长度、章节、bullet point、JSON 或纯文本。
示例: "以编号列表回复,不超过 5 项,每项不超 20 字。"
组件 6:约束(Constraints)
需要避免或限制的内容——排除项、范围边界、禁止话题。
示例: "不要包含产品推荐。避免使用'杠杆'这个词。不要重复引言已经覆盖的内容。"
一个完整拼装好的 prompt 长这样:
ROLE:
You are a senior product manager with deep experience in SaaS B2B onboarding.
TASK:
Write an email sequence (3 emails) to onboard new enterprise customers.
CONTEXT:
Our product is a project management tool. Customers are ops teams at
companies with 200–1000 employees. They often struggle with team adoption
after purchase.
FORMAT:
Email 1 (Day 0): Welcome - warm, brief, 150 words max
Email 2 (Day 3): Actionable tips - 3 bullets, 200 words max
Email 3 (Day 7): Success story + CTA, 200 words max
CONSTRAINTS:
No corporate jargon. No "synergy" or "leverage."
Tone: friendly and competent, not salesy.
Subject lines must be under 50 characters.
好 Prompt vs. 坏 Prompt:真实对比
最快的内化方式是对比。下面是几种常见任务类型的 Before/After。
写作任务
弱: "写一篇关于远程工作的博客。"
问题: 没有受众、角度、长度、语气、目的。模型会给你一篇泛泛而谈的文章,大概率还偏长。
强: "为工程经理写一篇 600 字的博客,主题是如何在全远程团队中维护团队文化。语气:实用、直接,不说教。包含 3 个具体策略,每个附简要理由。不要空泛的引言,以一个 hook 开头——用统计数据或场景。"
为什么有效: 受众、长度、语气、结构、开头风格,全部指定。
分析任务
弱: "分析这些数据,告诉我有什么有趣的。"
问题: "有趣"太主观了。模型不知道你的业务背景,也不知道你在做什么决策。
强: "我是一名营销总监,正在决定下季度增加哪些渠道的预算。分析这份广告表现数据,找出 ROI 最高的 2 个渠道,标记异常,推荐 1 个该砍的渠道。格式:发现、异常、建议。"
为什么有效: 你的角色、决策内容、输出段落、格式要求,全部到位。
代码任务
弱: "修复我的代码。"
问题: 没有代码、没有报错、没有上下文。完全没法用。
强: "这是一个 Python 函数 [code]。输入 dict 缺键时会抛出 KeyError。只修 bug,不要重构或重命名变量。加一条注释说明你改了什么和为什么。Python 3.10。"
为什么有效: 代码、具体错误、范围约束、输出预期,都给了。
Prompt Engineering 的关键技术(Prompt 模式)
下面是核心方法论,每种方法对应一个不同的杠杆,根据任务复杂度和类型选择使用。
Zero-Shot Prompting
直接给指令,不给例子。适合简单、边界清晰的任务:摘要、翻译、格式转换。这是你的起手式。它的短板是在风格要求微妙或输出结构复杂时容易翻车。
示例: "用 5 个要点总结以下会议记录:[transcript]"
Few-Shot Prompting
在正式任务前给一到五个输入/输出示例,模型会自动学会这个模式。这是通用性最强的技术,分类、风格匹配、结构化提取都能用。
示例越多,输出越稳定,但过了五六个之后边际收益急剧下降。
Review: "The checkout was a nightmare" → Negative
Review: "Fast shipping, product as described" → Positive
Review: "Okay but expected more" → Neutral
Now classify: "Took forever but the quality is great"
Chain-of-Thought(CoT)Prompting
要求模型在给出最终答案之前逐步推理。推理、数学、多步骤逻辑任务的准确率可以因此大幅提升。把思考过程亮出来,错误在半路就被抓住,不会偷偷跑到最终答案里去。
示例: "一家商店苹果 1.20/个,橙子 0.90/个。一位顾客买了 7 个水果,花了 $7.50,每种各买了几个?在给出最终答案之前逐步思考。"
Role Prompting
给模型分配一个专家角色。这不只是表面功夫——它会激活特定领域的知识、词汇和推理模式。角色不仅塑造语气,还决定整个回答的取向。角色可以叠加:"一个正在审查早期项目推介的 skeptical VC"——一个指令同时带来专业判断和批判视角。
Prompt Chaining
把复杂任务拆成一串简单的 prompt,前一个的输出喂给下一个。与其用一个巨型 prompt 包办所有事,不如串联成:调研 → 提纲 → 草稿 → 修订。每一步都更可控、可调试、可优化。
Step 1: "列出关于[话题]的 5 个最强论点" → output_1
Step 2: "用这些论点:[output_1],
写一篇有说服力的文章引言" → output_2
Step 3: "检查这篇引言里的逻辑漏洞:[output_2]"
Self-Consistency
同一个 prompt 跑多次(temperature 大于 0),取多轮中最一致的答案。高风险任务特别有用——一次回答可能不可靠,多个推理路径的多数投票在统计上总是比单一路径更准确。
Output Scaffolding
替模型开个头。你提供输出的开头,从第一个 token 起就约束了方向和格式。对强制 JSON 结构、特定句式、或去掉不想要的前言尤其有效。
示例: 在 prompt 末尾加上:
ONLY 按以下 JSON 格式回复,不要其他内容:
{
"summary": "",
"sentiment": "",
"score": 0
}
ReAct(Reason + Act)
Agent 系统的核心模式。ReAct 在推理步骤和行动之间来回切换——搜索网页、跑代码、查数据库。模型先思考,然后行动,观察结果,继续推理。现代 AI agent 处理需要真实世界信息的多步骤任务,靠的就是这个机制。
适用于各种情况的 Prompt
不同任务需要不同方法。下面是对最常见场景优化过的 prompt 结构。
写作与内容创作
写作类 prompt 最常犯的错误是漏掉受众、长度和语气。三个都要写清楚。还得定义目的:你想告知、说服、娱乐,还是转化?
博客模板:
Write a [LENGTH]-word blog post for [AUDIENCE] about [TOPIC].
Goal: [inform / persuade / drive signups]
Tone: [conversational / authoritative / witty / empathetic]
Structure:
- Hook (1 paragraph — start with a bold claim or question)
- [N] main sections with subheadings
- Practical takeaway at the end
Avoid: [list of phrases/styles to exclude]
社交媒体文案:
Write 5 variations of a LinkedIn post announcing [NEWS].
Audience: senior product managers.
Each variation uses a different hook:
1. Bold claim 2. Question 3. Story opener 4. Stat 5. Contrarian take
Max 200 words each. Include 3 relevant hashtags.
技巧: 想控制风格,拿东西来比较比抽象描述管用得多。"以 Michael Lewis 的风格写——清晰、叙事驱动、生动的角色刻画"——永远强过"写得吸引人一点"。
代码生成与代码审查
代码生成:
Language: Python 3.11
Task: Write a function that [SPECIFIC TASK].
Requirements:
- Input: [describe inputs and types]
- Output: [expected return value]
- Handle edge cases: [list them]
- No external libraries beyond [allowed list]
- Include docstring and type hints
- Include 3 pytest unit tests
Bug 修复:
Here is the code: [CODE]
Error message: [ERROR]
Expected behavior: [WHAT SHOULD HAPPEN]
What I've already tried: [PREVIOUS ATTEMPTS]
Fix ONLY the bug. Do not refactor.
Explain what caused it in 2 sentences.
代码审查:
Review this [LANGUAGE] code as a senior engineer doing a PR review.
Flag issues in these categories: security, performance, readability, edge cases.
Format: [CATEGORY] Line N: [issue] → Suggested fix: [fix]
Severity: Critical / High / Low
数据分析与文档分析
I'm a [YOUR ROLE] making a decision about [DECISION].
Here is the data: [DATA]
Analyze it and provide:
1. Key findings (top 3, ranked by importance)
2. Anomalies or outliers worth investigating
3. One recommendation based on the data
4. What additional data would improve this analysis
Be direct. No hedging unless genuinely uncertain.
头脑风暴与创意生成
大多数头脑风暴 prompt 产出的都是显而易见的想法——模型默认走安全路线。用明确的约束来逼出新颖性:
Generate 10 ideas for [PROBLEM/OPPORTUNITY].
Rules:
- First 5: conventional, proven approaches
- Next 3: counterintuitive or contrarian ideas
- Last 2: ideas that would seem absurd or impossible today
For each: Name | 1-sentence description | Who it appeals to most
摘要
Summarize the following [document/transcript]: [TEXT]
Provide two versions:
1. TL;DR - 3 sentences max. For someone who will read nothing else.
2. Key Points - 5–7 bullets on the most important ideas, decisions,
and action items. Each bullet max 25 words.
Then list: Open questions or unresolved items (if any).
邮件与专业沟通
Write an email from [MY ROLE] to [RECIPIENT ROLE] at [COMPANY].
Goal: [what I want to happen after they read it]
Context: [relevant background]
Tone: [formal / collegial / urgent]
Key points: [list]
Avoid: [passive aggression / being pushy / corporate jargon]
Length: [brief / standard / detailed]
对于棘手内容——拒绝、坏消息、道歉——让模型给你两个版本(直接版和温和版),你根据场景选。
教育与培训
Create a lesson plan for teaching [TOPIC] to [AUDIENCE].
Duration: [TIME AVAILABLE]
Prior knowledge: [WHAT THEY ALREADY KNOW]
Objective: By the end, learners should be able to [DO/UNDERSTAND WHAT]
Include:
- Hook activity (5 min)
- Core content
- Practice activity
- 3 comprehension check questions
- Summary
高级策略
基础打牢之后,下面这些策略能推高可靠性的天花板。
System Prompts
在 API 场景下,把角色和固定规则分离到 system prompt 里,user prompt 只放任务相关的输入。System prompt 就是你的模型配置——每轮对话自动生效,不用重复写。在这里定义角色、公司上下文、语气规则、输出格式默认值。
Temperature 控制
Temperature 控制模型输出的"创意"(随机性)程度:
- 0.0 — 完全确定性。最适合提取、分类、代码修复和 JSON 输出。
- 0.3 — 集中但略有变化。适合摘要和结构化分析。
- 0.7 — 均衡。适合专业写作和博客。
- 1.0 — 有创意。适合头脑风暴和创意写作。
- 1.2+ — 狂野发散,慎用。
做事实性检索时绝对不要开高 temperature——幻觉风险会急剧上升。
Meta-Prompting
让模型帮你写或改 prompt。
示例: "这是我的草稿:[PROMPT]。找出歧义,重写得更具体、更可靠,以获取[期望输出]。"
模型批评和改进自己指令的能力相当惊人。当你能说清当前 prompt 哪里不对但不知道怎么改的时候,这招特别有用。
Validation Loops
生成之后加一个自查步骤。Prompt:"检查你的回答,有没有遵循所有指令?你会改什么?"
这能逮住第一轮漏掉的错误——特别是格式和约束违规。代价只是多花一点 token。
RAG Prompting(Retrieval-Augmented Generation)
知识密集型任务,先检索相关文档,再注入 prompt 上下文。然后明确指示:"只基于提供的文档回答。答案不在文档里就说不知道。"
这样能防止模型在特定领域话题上胡说八道,让它基于经过验证的信息作答,而不是凭通用训练数据瞎猜。
校准的不确定性(Calibrated Uncertainty)
让模型标明自己的置信度:"对一个事实没把握时,前面加上[UNCERTAIN]。不知道就直接说,不要猜。"
对事实性任务来说这点至关重要——法律、医疗、金融、技术领域,幻觉的代价太高了。
对抗性测试(Adversarial Testing)
主动用边界情况、异常输入、模糊请求来尝试搞崩你自己的 prompt。一个 90% 情况下有效的 prompt,放大规模后会在 10% 的情况下翻车。而规模化的场景下,这就很重要了。健壮性来自预先想好失败模式,在它们上线之前就打好补丁。
快速参考速查表
Prompt 必备要素
- 说明模型该"是谁"
- 说明你要"做什么"(一个动作动词)
- 提供上下文和受众
- 指定格式和长度
- 列出要避免的内容
- 风格重要的话,给个例子
好用的强力短语
- "在回答之前逐步思考"
- "只按这个格式回复:…"
- "扮演一个[专家角色]"
- "不确定就说不知道——别猜"
- "给我 3 个不同方案的版本"
- "检查一遍你的回答再定稿。"
按任务分类的技术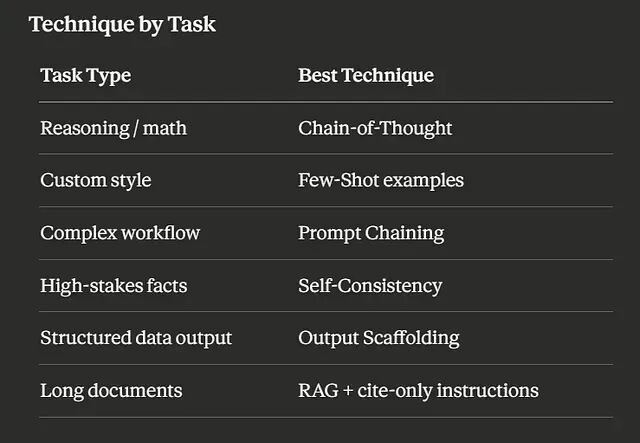
常见问题修复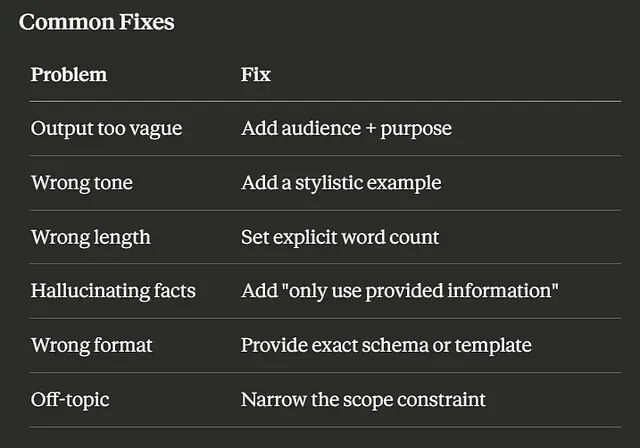
总结
稳定输出的 prompt 工程师和随便玩玩的人之间,区别在于这套流程:
- 写一个草稿 — 别想太多,先写下来
- 跑一遍,看结果 — 模型实际产出了什么?
- 找出问题 — 太长?语气不对?漏了关键约束?
- 一次只改一个变量 — 隔离变量,你才能知道哪个改动起了作用
- 用边界情况测 — 异常输入会怎样?
- 把能用的版本存起来 — 建一个 prompt 库
道理很简单:把每个 prompt 都当作文档的初稿。输出结果会告诉你 prompt 缺了什么。改就是了。
by Fraidoon Omarzai