
基于向量的 RAG 优化的是语义相似度(semantic similarity):比如"不允许退货的政策"和"允许退货的政策"这两个查询会产生几乎相同的 embedding。模型理解的不是逻辑而是向量空间中的邻近关系。
更麻烦的是分块(chunking):把文档机械切成片段,会把逻辑连贯性一并打碎。一个定义落在一个 chunk 里,约束它的条件却落在另一个 chunk 里。LLM 拿到的是不完整的上下文所以也只能靠猜。
比如说在受监管的系统里(法律、金融、医疗),这就变成了法律责任。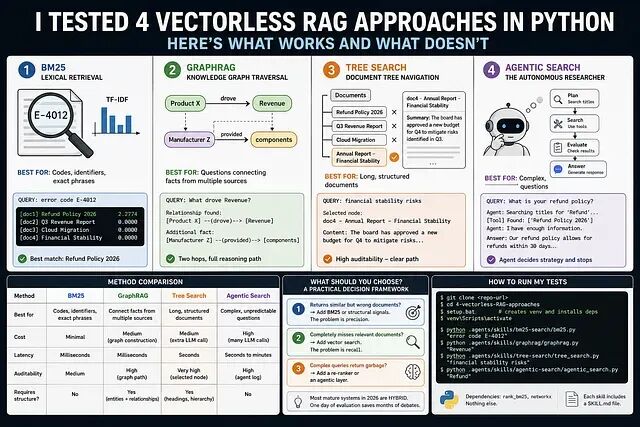
我没有使用合成基准测试,而是准备了一个小语料库:四份企业文档,JSON 格式,预先抽取好实体与关系。
[
{
"id": "doc1",
"title": "Refund Policy 2026",
"content": "Our refund policy allows for refunds within 30 days of purchase. Digital goods are non-refundable. Error code E-4012 indicates a failed refund transaction due to expired card.",
"entities": ["Refund", "30 days", "Digital goods", "E-4012"],
"relationships": [["Refund", "has condition", "30 days"], ["E-4012", "means", "expired card"]]
},
{
"id": "doc2",
"title": "Q3 Revenue Report",
"content": "In Q3 2025, our revenue grew by 15% due to the successful launch of Product X. Manufacturer Z provided critical components. However, supply chain issues with Supplier Y caused minor delays.",
"entities": ["Q3 2025", "Revenue", "Product X", "Manufacturer Z", "Supplier Y"],
"relationships": [["Product X", "drove", "Revenue"], ["Manufacturer Z", "provided", "components"], ["Supplier Y", "caused", "delays"]]
}
]
四种方法都查这一份数据集,但每种方法分别使用刻意挑选、能发挥其长处的查询。得到的结果是:没有任何一种方法是通用的。
方法一:BM25词法检索(Lexical retrieval)
查找具体标识符的场景:错误码、条款编号、产品名称。BM25 不理解含义,它只统计某个词在一篇文档中出现多少次,以及该词在整个语料库中有多稀有(TF-IDF)。这和 Google 搜索最底层做的事情是同一件。
代码(Python,约 30 行)
from rank_bm25 import BM25Okapi
tokenized_corpus = [doc['content'].lower().split() for doc in data]
bm25 = BM25Okapi(tokenized_corpus)
query = "error code E-4012"
tokenized_query = query.lower().split()
doc_scores = bm25.get_scores(tokenized_query)
测试结果
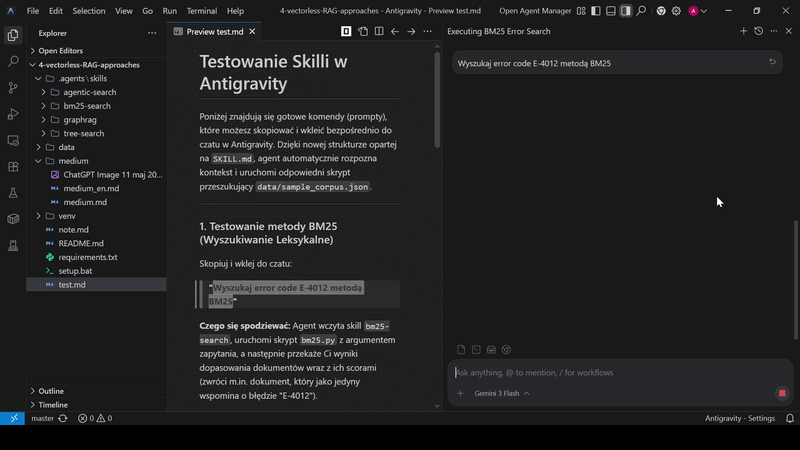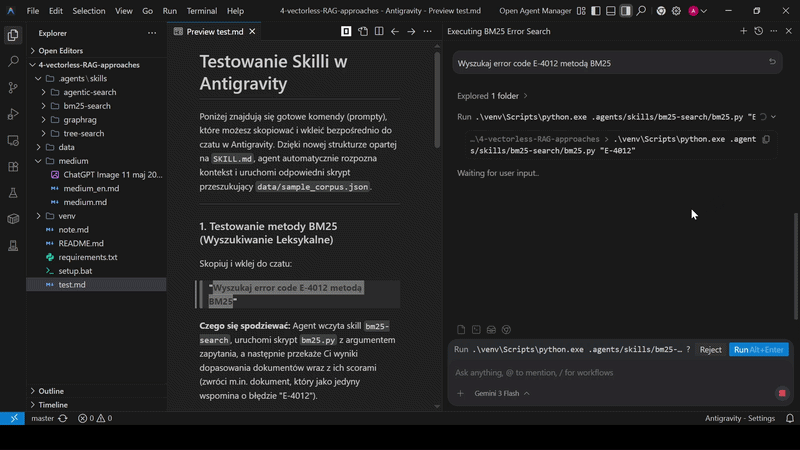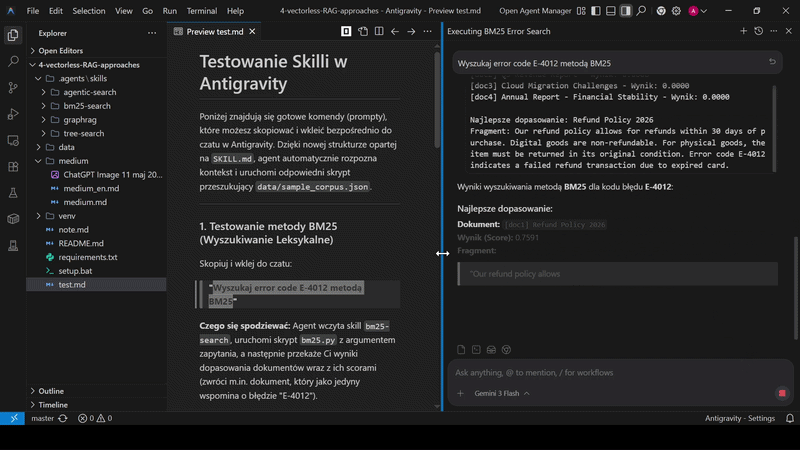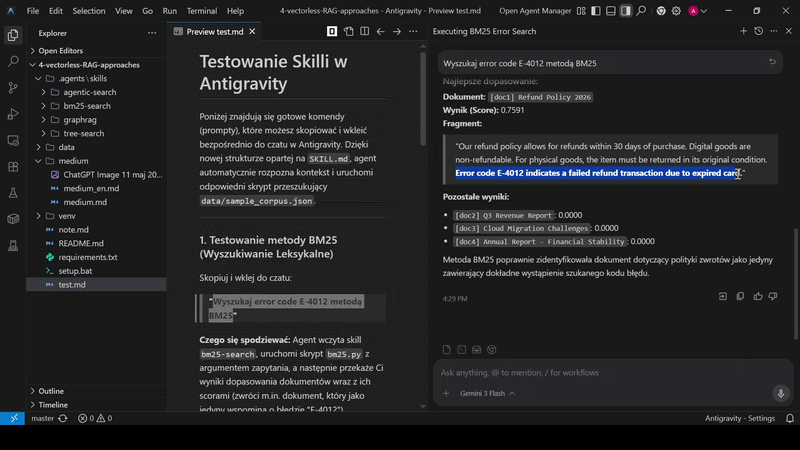
Query: 'error code E-4012'
[doc1] Refund Policy 2026 - Score: 2.2774
[doc2] Q3 Revenue Report - Score: 0.0000
[doc3] Cloud Migration - Score: 0.0000
[doc4] Financial Stability - Score: 0.0000
Best match: Refund Policy 2026
精准命中,零噪声。基于向量的 RAG 在这种情况下可能会从另一个上下文里返回一份讲"transaction errors"的文档,因为"error"的 embedding 很相似。BM25 字面地搜索
E-4012
,要么找到,要么找不到。
但是,查询"OOM error"匹配不到讲"out of memory crash"的文档。BM25 不懂同义词。
方法二:GraphRAG 知识图谱遍历
需要把多个来源的事实连起来的时候。经典的多跳(multi-hop)问题:是谁为推动了营收增长的那个产品提供了组件?回答它需要遍历多个图节点。
代码(Python,NetworkX)
import networkx as nx
G = nx.DiGraph()
for doc in data:
for entity in doc["entities"]:
G.add_node(entity, source_doc=doc['id'])
for subj, pred, obj in doc["relationships"]:
G.add_edge(subj, obj, relation=pred)
测试结果
Query: What drove Revenue?
Relationship found: [Product X] --(drove)--> [Revenue]
Additional fact: [Manufacturer Z] --(provided)--> [components]
两跳、两个事实,外加一条完整的推理路径。换成基于向量的 RAG,拿到的只会是关于营收的 chunk,却没有任何信息能说明营收为什么会增长,因为图谱给出的是因果上下文。
而且构建图谱需要干净、结构化的数据。如果文档是没有格式的 PDF 或零散笔记,实体抽取会很糟糕,图谱也就没用了。
方法三:Tree Search(PageIndex)文档树导航
面对一份结构良好、篇幅很长的文档时——年度报告、法律合同、技术规范——希望系统像分析师那样先扫一眼目录,而不是从头读到尾。
工作方式
- 把文档解析为树:标题 → 章节 → 子章节,并附短摘要。
- AI 模型在顶层只读标题和摘要。
- 选出最可能的节点,"进入"它,读取子章节,重复这一过程,直到抵达相关片段。
- 此时才取出全文,并生成答案。
测试结果
Query: 'financial stability risks'
Scanning node: Documents
-> Analyzing: Refund Policy 2026 - skipped
-> Analyzing: Q3 Revenue Report - skipped
-> Analyzing: Cloud Migration - skipped
-> Analyzing: Annual Report - Financial Stability - HIT
Selected node: doc4 - Annual Report - Financial Stability
Content: The board has approved a new budget for Q4 to mitigate risks identified in Q3.
模型扫过标题,拒掉不相关的章节,最后定位到正确的文档,全程没有做任何 embedding。在真实系统里树会有多层嵌套,每个节点都包含由 LLM 生成的摘要。
好的地方是,可以清楚看到系统选择了哪个章节、为什么这样选。在受监管的系统里,这不是"锦上添花",而是硬性要求。
但是,如果遇到没有标题的文档(聊天记录、零散笔记)则无法生成树,导航过程中额外的 LLM 调用也意味着时间和金钱成本。
方法四:Agentic Search 自主研究员
问题复杂、多步骤并且事先不知道该去哪里找答案时。Agent 会自己规划策略,调用工具,评估结果,再决定要不要继续搜索。
代码(agent 循环模拟)
def agent_loop(data, query):
print("Agent: First, I'll search titles for 'Refund'.")
results = tool_search_title(data, "Refund")
if not results:
print("Agent: Nothing. Searching deeper in content.")
results = tool_search_content(data, "Refund")
print(f"Agent: Got a result: {results[0]['title']}. Generating answer.")
return results[0]['content']
测试结果
Agent: Received query: What is your refund policy?
Agent (Thinking): Searching for refund policy documents by title.
[Tool] Searching titles for: 'Refund'
Agent: Result: ['Refund Policy 2026']. I have enough information.
Answer: Our refund policy allows for refunds within 30 days...
Agent 自行决定如何搜索,并在拿到足够结果时停下。在真实系统中(搭配 o3 或 Gemini 2.5 Pro 这类推理模型),Agent 可以把复杂问题拆解成子查询,交叉验证结果,并回溯到先前的步骤。
这是最贵的方案。每一步思考都是一次独立的 LLM 调用,查询量一大,成本会迅速膨胀;能力较弱的模型还可能陷入无限循环。
方法对比以及如何选择
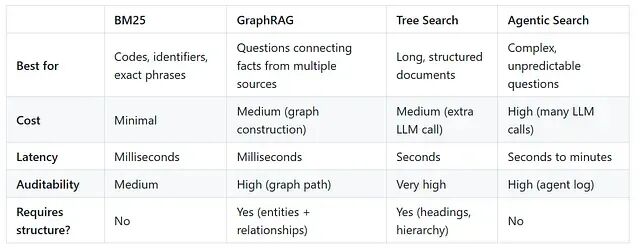
不要根据哪种方法听起来更前沿来挑选,要看当前系统在哪里出问题:
- 返回的文档相似但错误?→ 加 BM25 或结构化信号——问题出在精确度。
- 完全找不到相关文档?→ 加向量检索——问题出在召回率(recall)。
- 复杂查询返回的是垃圾?→ 加 re-ranker 或 Agent 层。
2026 年大多数成熟的系统都是混合式的:向量负责语义召回,BM25 负责精确匹配,re-ranker 负责质量,基于推理的检索负责最难的那部分查询。
原文最好的一条建议是:从自己的系统里挑出 20–30 个真实问题,把两种方案都跑一遍对比结果。一天的评估能省下几个月的架构争论。
本文代码
完整代码已整理成一个开箱即用的仓库,附带共享测试语料库。每种方法都是一个独立的 agentic skill一段轻量级的 Python 脚本,配一个
SKILL.md
描述文件,AI Agent 可以自动发现并执行:
# Clone and set up
git clone https://gitlab.com/public-ako74programmer/ai-projects/4-vectorless-rag-approaches.git
cd 4-vectorless-RAG-approaches
setup.bat # creates venv and installs dependencies
# Activate the environment
venv\Scripts\activate
# Test individual methods
python .agents/skills/bm25-search/bm25.py "error code E-4012"
python .agents/skills/graphrag/graphrag.py "Revenue"
python .agents/skills/tree-search/tree_search.py "financial stability risks"
python .agents/skills/agentic-search/agentic_search.py "Refund"
依赖只有
rank_bm25
和
networkx
,没有别的。每个测试都是几十行 Python 代码,可读、可改,可以拿来扩展到自己的数据上。
总结
基于向量的 RAG 不差,只是有局限,这些局限只在生产里才会暴露,不会出现在 demo 里。无向量方案也不是银弹,每种都有自己的弱点。但把它们以合适的方式组合起来,能搭出一套不只是找到信息,而是能找到正确信息的系统。
先从一种方法开始。测出它的失效点。再加上下一种。
by Andrzej K.