
GPU 编程看起来总像黑魔法,满眼是 warps、shared memory、tensor cores,还有 kernel 里古怪的索引运算。但是这篇文章从一个具体例子入手帮你理解 Triton:从头实现一个 softmax kernel。
以官方 Triton 教程为基础,深入代码背后的原理并配上手绘图解。如果你觉得 GPU 编程教程总是太晦涩,这篇文章正好可以用来入门。
我们的目标不止是写一个 kernel而是理解现代 AI 工作负载在 GPU 上到底怎么跑。
最后会把 kernel 放到 RTX 5090 上跟 PyTorch 的原生 softmax 跑个 benchmark。结果不是简单的"Triton 赢了"——这里有个性能悬崖,教会你 GPU 编程里很重要的一件事。
Softmax:简单的数学,隐藏的内存问题
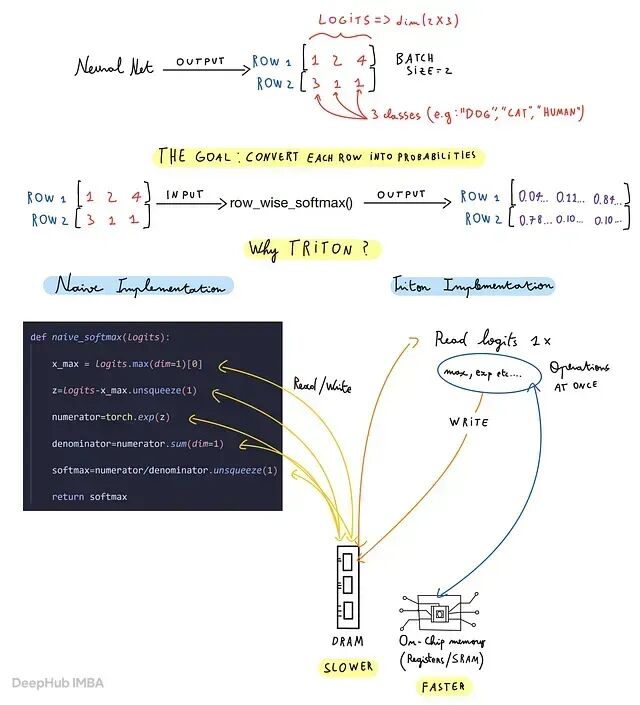
逐行 softmax 从数学上很简单:每行是一个独立 logit 向量,softmax 把它转成概率。
比如一个
2×3
矩阵,不是对六个值算一个大 softmax,而是算两个独立的 softmax——行 0 一个、行 1 一个。
难点不在数学而是在 GPU 上的执行方式:数据搬几次、中间值存在哪、GPU 是花时间算还是在等内存。
简单的 PyTorch 实现把 softmax 拆成几个独立的张量操作:max、减法、指数、求和、除法。每一步都可能从全局内存读数据再把中间值写回去。
而融合的 Triton kernel 改变了这个模式:一次加载一行,所有 softmax 步骤在数据留在片上时完成,最后一次性写回结果。
这里的片外指 GPU 全局内存/DRAM:大但慢。片上指 GPU 计算单元内部的内存(寄存器或共享内存/SRAM):快得多但小得多。
从概念上说一个 Triton 程序处理一行,但实际运行时是大量 Triton 程序并行跑。
一个简单的 Triton模型
在看 softmax kernel 之前,先搭个简单的模型。
一个
3072
长度的向量
X
,要给每个元素减 1。
CPU 思路是顺序循环:
foriinrange(3072):
X[i] =X[i] -1
在 GPU 上就不是这样了,GPU 要把向量切成块,并行处理。
Triton 里,一个 kernel 描述一个程序实例的行为。启动 kernel 时,启动一个网格,里面很多程序实例并行跑。
BLOCK_SIZE=1024
每个程序实例处理
1024
个元素。
3072 / 1024 = 3 → 需要 3 个程序实例。
program 0 → elements 0-1023
program 1 → elements 1024-2047
program 2 → elements 2048-3071
每个程序实例拿到自己的
program_id
,用它定位数据切片,执行相同操作。
Softmax kernel 里也一样,只是每个程序实例处理矩阵的一行,不是向量的一块。
逐行拆解 Triton Softmax Kernel
一个 Triton 程序实例一次处理一行。启动的程序数少于行数时,每个程序以固定步长在矩阵中跳跃,处理多行。
@triton.jit
def softmax_kernel(
output_ptr, input_ptr,
input_row_stride, output_row_stride,
n_rows, n_cols,
BLOCK_SIZE: tl.constexpr,
num_stages: tl.constexpr,
):
row_start = tl.program_id(0) # 当前程序实例 ID
row_step = tl.num_programs(0) # 轴 0 上的实例总数
for row_idx in tl.range(row_start, n_rows, row_step, num_stages=num_stages):
tl.program_id(0)拿到当前实例的 id。
如果启了 4 个程序,program 0 从 row 0 开始,program 1 从 row 1 开始以此类推,每个程序按
row_step
跳跃处理后续行。
row_stride
告诉程序在内存里走多远才到下一行的开头。一个常见错误是认为下一行总在
n_cols
个元素之后开始——对紧凑连续张量是对的但不是所有布局都这样。
# 指向当前行在内存中的起始位置
row_start_ptr = input_ptr + row_idx * input_row_stride
col_offsets = tl.arange(0, BLOCK_SIZE)
input_ptrs = row_start_ptr + col_offsets
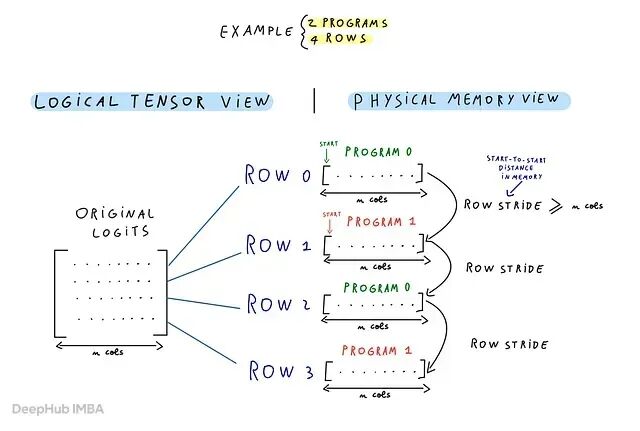
区分两个概念:
n_cols
是逻辑列数,
input_row_stride
是两行之间的物理内存距离。
mask = col_offsets < n_cols
row = tl.load(input_ptrs, mask=mask, other=-float("inf"))
mask 告诉 Triton 只加载实际列,假列用
-inf
填充,因为
exp(-inf) = 0
不影响 softmax 分母。
row_minus_max = row - tl.max(row, axis=0)
numerator = tl.exp(row_minus_max)
denominator = tl.sum(numerator, axis=0)
softmax_output = numerator / denominator
先减最大值保数值稳定,不改变 softmax 结果但防止指数溢出。这些操作都在同一个融合的 Triton 程序里——
row_minus_max
、
numerator
、
denominator
不会作为中间张量写回全局内存。
启动 Kernel:Python 包装器
Triton kernel 描述一个程序实例内部干什么,但实际问题需要 Python 代码来回答:块多大?多少 warp?启动几个程序?
def softmax(x):
n_rows, n_cols = x.shape
BLOCK_SIZE = triton.next_power_of_2(n_cols)
选择 2 的幂的 BLOCK_SIZE——适合 Triton 的块编程模型和归约操作。一行 3000 列?BLOCK_SIZE 用 4096,多余的用 mask 屏蔽。
num_warps = 8
Warp 是一组一起执行的 GPU 线程,
num_warps = 8
意味着每个 Triton 程序实例用 8 个 warp。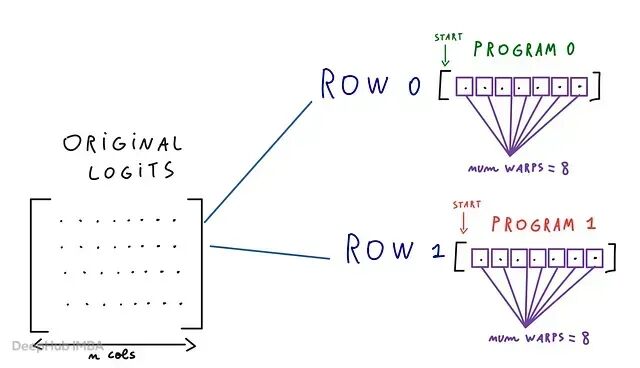
num_stages = 4 if SIZE_SMEM > 200000 else 2
num_stages和程序、warp 是不同的,它帮助同一程序内的循环迭代重叠——比如一轮加载、一轮计算、一轮写入同时进行。不过更多阶段用更多片上资源并不一定更好。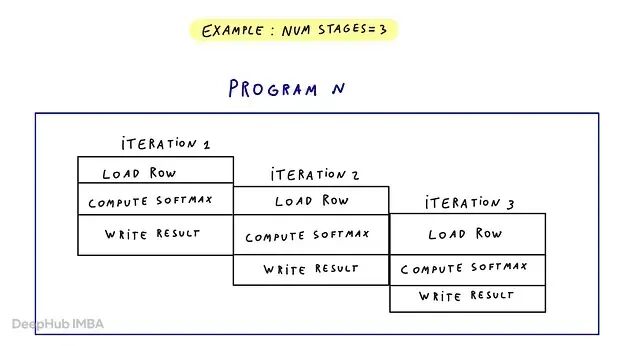
y = torch.empty_like(x)
为输出分配和输入同 shape、dtype、device 的张量。
kernel = softmax_kernel.warmup(
y, x, x.stride(0), y.stride(0),
n_rows, n_cols,
BLOCK_SIZE=BLOCK_SIZE, num_stages=num_stages, num_warps=num_warps,
grid=(1,),
)
kernel._init_handles()
n_regs = kernel.n_regs
size_smem = kernel.metadata.shared
先编译一次 kernel,看看一个程序实例消耗多少寄存器和共享内存。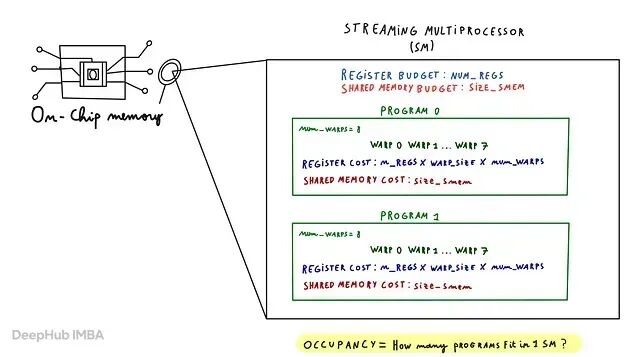
GPU 流多处理器资源有限。每个 SM 有固定的寄存器和共享内存预算。一个程序用太多,同一 SM 能同时跑的程序就少。
occupancy = NUM_REGS // (n_regs * WARP_SIZE * num_warps)
occupancy = min(occupancy, SIZE_SMEM // size_smem)
num_programs = NUM_SM * occupancy
num_programs = min(num_programs, n_rows)
占用率受限于最先耗尽的资源。这是持久化风格 kernel:不是每行启一个程序,而是启足够程序占满 GPU,每个程序循环处理多行。
基准测试
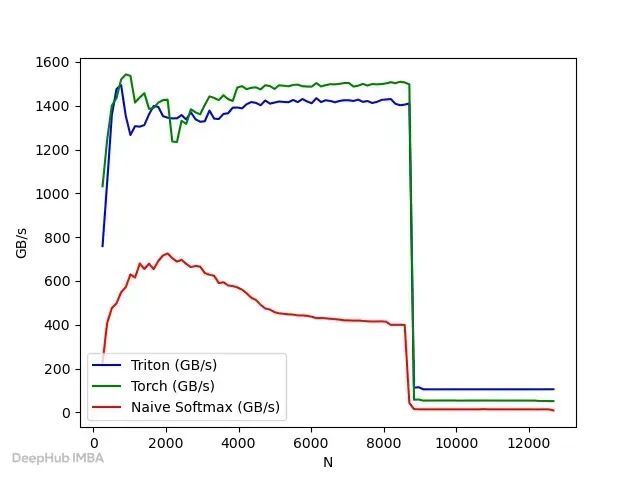
RTX 5090 上逐行 softmax benchmark,
_M = 4096_*,
_N_变化。*
中小行大小下 PyTorch 更快,意料之中。但
N ≈ 8700
附近两边都撞上性能悬崖。之后 Triton kernel 反超。
这不意味着 Triton 万能更快,因为GPU 性能高度依赖张量形状、块大小、资源使用。y 轴是有效带宽,从输入输出张量大小算出,不是每次内部内存事务。
Triton 实现中,
N
超过
8192
后
BLOCK_SIZE
跳到
16384
,每个程序实例内部操作更大的块,资源压力上升,性能出现突变。
总结
Triton 可以让你在接近 Python 的层面写 GPU kernel 的方式。这个例子也告诉我们不是 Triton 总比 PyTorch 快,因为PyTorch 已经高度优化了。
本文代码
by Lounis Hamroun