
1.基本概念
1.1 简介
BP神经网络(Back Propagation Neural Network)是一种基于误差反向传播算法(Back Propagation Algorithm)的人工神经网络,也是应用最广泛的神经网络之一。它可以用来解决分类、回归、模式识别、数据挖掘等多种问题。
BP神经网络由输入层、隐层和输出层组成,其中隐层可以包含多个神经元,用于处理输入数据的非线性映射关系。BP神经网络的训练过程包括前向传播和反向传播两个步骤。
BP神经网络的优点是可以处理非线性问题,并且具有较高的精度和可扩展性。缺点是容易出现过拟合问题,需要采取一些正则化方法进行控制。此外,BP神经网络的训练过程需要大量的计算和存储资源,训练时间较长。
BP神经网络已经被广泛应用于各种领域,如图像处理、语音识别、自然语言处理、金融风险评估等。
1.2 前向传播
前向传播:将输入数据通过网络的输入层传递到隐层和输出层,计算输出结果。
前向传播是神经网络中的一种计算方式,用于将输入的数据传递到网络中的每个神经元,并计算出网络的输出结果。在前向传播过程中,输入数据会经过一系列的加权和非线性变换,同时经过每个神经元的激活函数,传递到下一层,最终得到网络的输出结果。
具体来说,前向传播可以分为以下几个步骤:
将输入数据传递到网络的第一层(输入层),每个输入变量对应一个输入神经元;
将输入数据经过输入层的加权和非线性变换,传递到网络的下一层(隐层或输出层);
重复第二步,直到数据传递到网络的最后一层(输出层),计算出网络的输出结果;
将输出结果与实际标签进行比较,计算误差。
在前向传播过程中,每个神经元的输出值都是由上一层的输出值和该神经元的权重以及偏置值共同决定的。通常,神经元的输出值会经过一个激活函数,如sigmoid函数或ReLU函数,将其映射到一定的范围内,以保证输出值的非线性特性。
前向传播是神经网络中的一个基本计算过程,它为后续的反向传播提供了基础。在神经网络的训练过程中,前向传播和反向传播交替进行,以调整网络中各个神经元的权重和偏置,提高网络的精度和性能。
1.3 反向传播
反向传播:根据输出结果和实际标签之间的误差,通过误差反向传播算法,调整网络中每个神经元的权重和偏置,以降低误差值,并提高网络的精度。
反向传播(Back Propagation)是神经网络中的一种训练方法,通过反向传播算法来调整网络中每个神经元的权重和偏置,以降低误差值,并提高网络的精度。
反向传播算法的基本思想是利用链式法则(Chain Rule)对网络中每个神经元的权重和偏置进行调整,从而最小化网络输出与实际标签之间的误差。
具体来说,反向传播可以分为以下几个步骤:
前向传播:将输入数据通过网络的输入层传递到隐层和输出层,计算输出结果;
计算误差:将输出结果与实际标签之间的误差传递回网络,计算误差值;
反向传播:根据误差值和链式法则,从输出层向输入层逐层计算每个神经元的梯度,即权重和偏置对误差的偏导数;
更新权重和偏置:根据计算得到的梯度信息,调整每个神经元的权重和偏置,以降低误差值,并提高网络的精度。
反向传播算法的优点是可以高效地调整神经元的权重和偏置,以提高网络的精度和性能。缺点是容易出现过拟合问题,需要采取一些正则化方法进行控制。此外,反向传播算法的训练过程需要大量的计算和存储资源,训练时间较长。
反向传播算法是神经网络中的核心算法之一,对于神经网络的训练和应用具有重要的意义。
2.BP算法详解
2.1 构成示意图
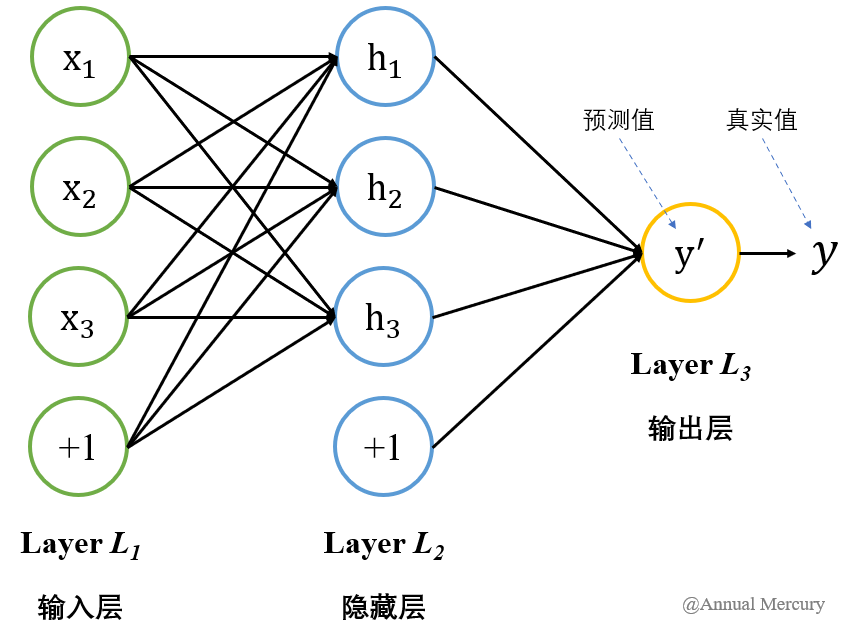
图2-1 BP神经网络的基本构成
如图2-1所示,这是典型的三层神经网络的基本构成,Layer  是输入层(input layer),Layer
是输入层(input layer),Layer  是隐含层(hidden layer),Layer
是隐含层(hidden layer),Layer  是隐含层(output layer)。其中输入层,输出层一般只有1层,而隐藏层取决于具体实例的学习进程,可以设置多层次。
是隐含层(output layer)。其中输入层,输出层一般只有1层,而隐藏层取决于具体实例的学习进程,可以设置多层次。
一组数据 ,经过输入层的加权和非线性变换进入隐藏层,再经过同样的操作最终进入输出层。输出的结果是我们的预测值。此时需要比较预测值与真实值的区别,通过偏导数计算调节权重与偏置,不断迭代得到与真实值近似的预测值。
,经过输入层的加权和非线性变换进入隐藏层,再经过同样的操作最终进入输出层。输出的结果是我们的预测值。此时需要比较预测值与真实值的区别,通过偏导数计算调节权重与偏置,不断迭代得到与真实值近似的预测值。
2.2 举例说明
在本节,将举一个例子带入数值演示反向传播法的过程。该部分的演示过程和数据参考了BP算法详解。
假设存在图2-2这样一个网络结构:
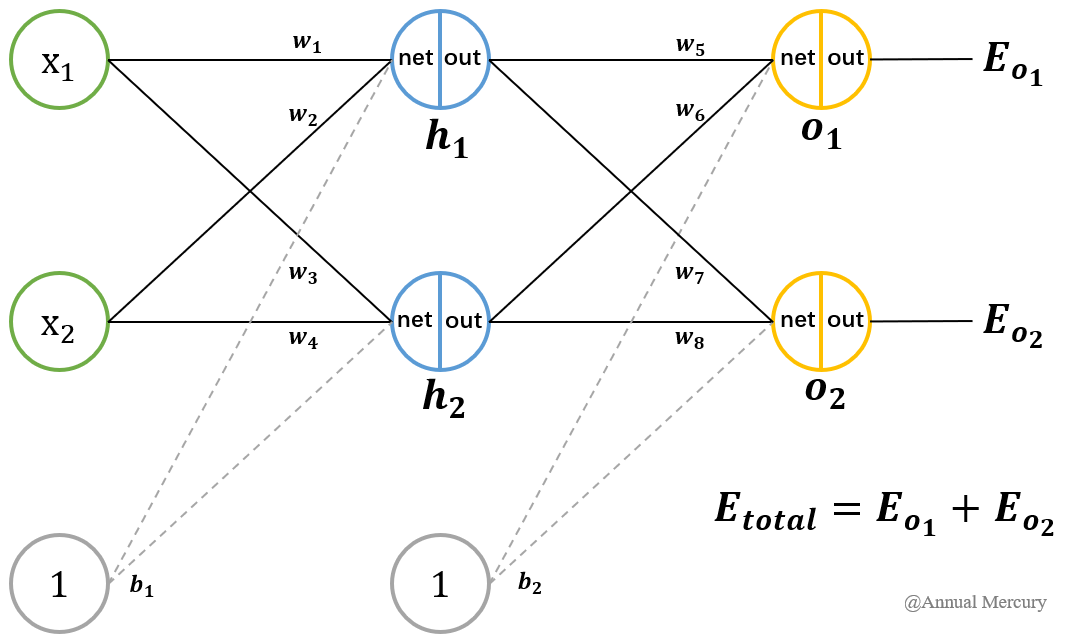
图2-2 BP神经网络示例流程图
表2-1 初始设置和最终目标
输入数据
x1=0.05
x2=0.10
输出数据
o1=0.01
o2=0.99
初始权重
w1=0.15
w2=0.20
w3=0.25
w4=0.30
初始权重
w5=0.40
w6=0.45
w7=0.50
w8=0.55
目标
给出输入数据x1,x2(0.05和0.10),使输出尽可能与原始输出o1,o2(0.01和0.99)接近。
Step 1 前向传播
- 输入层
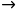 隐藏层
隐藏层
计算神经元h1的输入加权和:
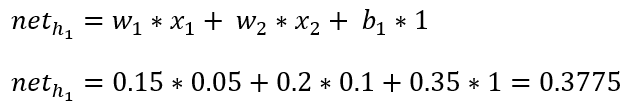
神经元h1的输出o1:(此处用到激活函数为sigmoid函数):

同理,可计算出神经元h2的输出o2:
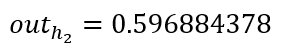
- 隐藏层 输出层
计算输出层神经元o1和o2的值:
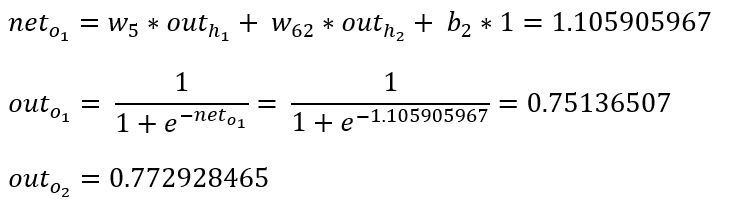
前向传播的过程结束,得到输出值为[0.75136079 , 0.772928465],与实际值[0.01 , 0.99]相差还很远。
现在我们对误差进行反向传播,更新权值,重新计算输出。
Step 2 反向传播
- 计算总误差
总误差(Square Error)公式:

所以,两个输出的误差可以分别被计算出来,并得到误差之和:

- 隐藏层 输出层的权值更新
以权重参数w5为例,如果我们想知道w5对整体误差产生了多少影响,可以用整体误差对w5求偏导求出(链式法则),图2-3也可以直观的看出误差是如何反向传播的:


图2-3 反向传播: 隐藏层 → 输出层
可以计算求出整体误差 E(total) 对 w5 的偏导值:
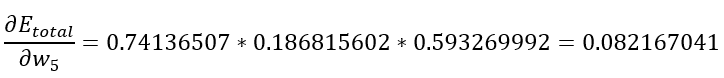
最后更新w5的值:

其中, 是学习率,这里取0.5。
是学习率,这里取0.5。
同理可以更新w6,w7,w8的值。
- 输入层 隐藏层的权值更新
在上文计算总误差对w5的偏导时,是从out(o1)—->net(o1)—->w5,但是在输入层和隐藏层之间的权值更新时,是out(h1)—->net(h1)—->w1,而out(h1)会接受E(o1)和E(o2)两个地方传来的误差,所以这个地方两个都要计算。计算流程见图2-4。
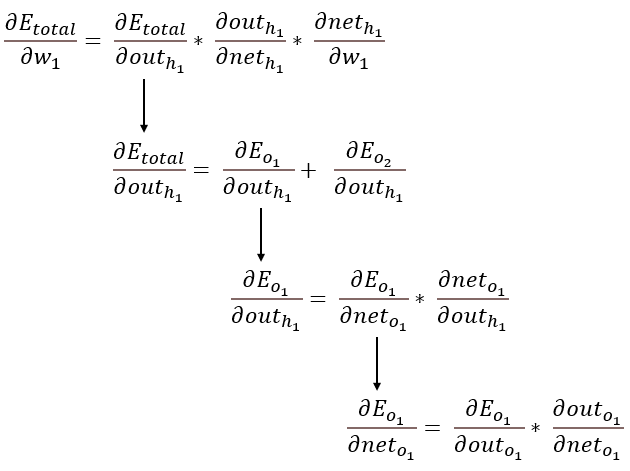
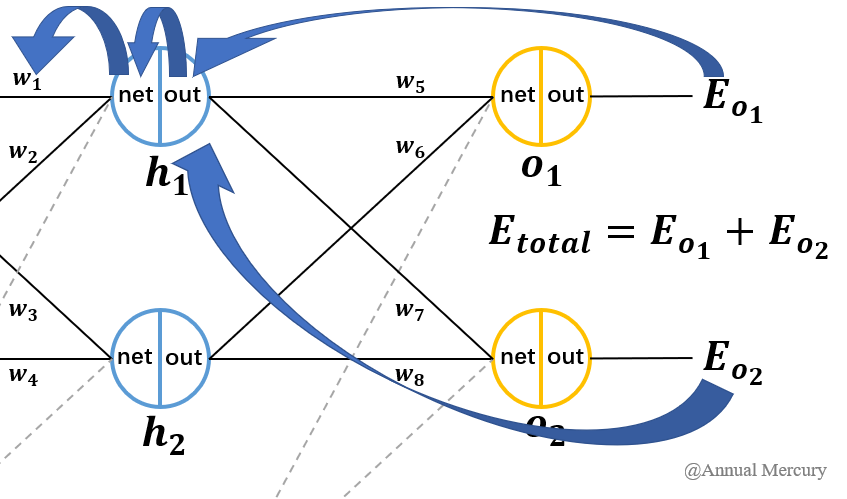
图2-4 反向传播: 输入层 → 隐藏层
可以计算求出整体误差 E(total) 对 w1 的偏导值:

最后,更新w1的权值:

同理,也可更新w2,w3,w4的权值。
这样误差反向传播法就完成了,最后我们再把更新的权值重新计算,不停地迭代,在这个例子中第一次迭代之后,总误差E(total)由0.298371109下降至0.291027924。迭代10000次后,总误差为0.000035085,输出为0.015912196,0.984065734,证明效果还是不错的。
3.代码演示
import torch
# 定义输入数据和标签
X = torch.Tensor([[0, 0], [0, 1], [1, 0], [1, 1]])
y = torch.Tensor([[0], [1], [1], [0]])
# 定义神经网络结构
net = torch.nn.Sequential(
torch.nn.Linear(2, 4),
torch.nn.Sigmoid(),
torch.nn.Linear(4, 1),
torch.nn.Sigmoid()
)
# 定义损失函数和优化器
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.1)
# 训练神经网络
for epoch in range(10000):
# 前向传播
y_pred = net(X)
# 计算损失函数
loss = criterion(y_pred, y)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每隔1000次迭代输出一次损失函数的值
if epoch % 1000 == 0:
print('Epoch:', epoch, 'Loss:', loss.item())
# 测试神经网络
with torch.no_grad():
y_pred = net(X)
print('Predict:', y_pred)
在该代码中,我们首先定义了输入数据和标签。然后定义了神经网络结构,包括两个全连接层和一个激活函数(Sigmoid)。接着定义了损失函数和优化器(采用随机梯度下降算法)。最后使用 for 循环训练神经网络,每隔1000次迭代输出一次损失函数的值。在训练完成后,使用 with torch.no_grad() 禁用梯度计算,再次输入训练数据,得到预测结果。
需要注意的是,PyTorch 的神经网络模型需要继承自 torch.nn.Module 类,并实现 forward() 方法。在本例中,我们使用了 Sequential 类来定义神经网络结构,它可以将多个层组合在一起形成一个完整的神经网络。在反向传播时,需要调用 optimizer.zero_grad() 来清空梯度信息,然后调用 loss.backward() 计算梯度,最后调用 optimizer.step() 更新参数。
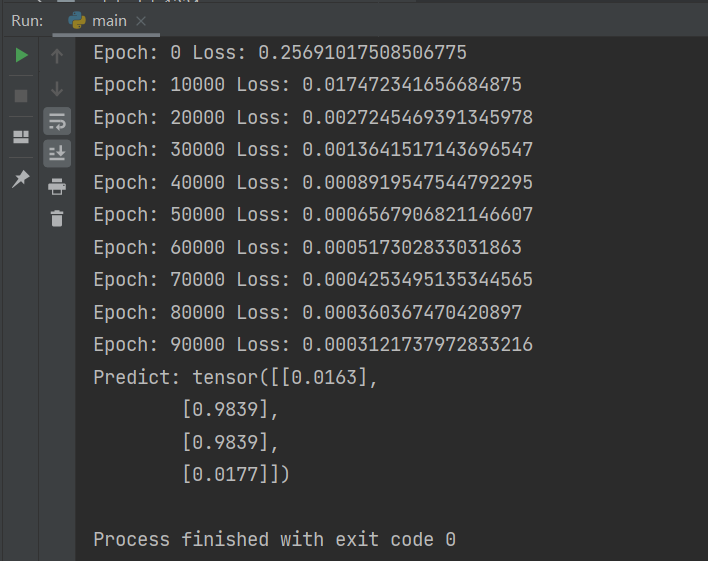
图2-5 BP算法示例代码运行结果
图2-5展示的是迭代100000次后的运行结果,每10000次迭代输出一次损失函数的值。
最终输出为 [[0.0163], [0.9839], [0.9839], [0.0177]], 与原始输出 [[0], [1], [1], [0]] 相比绝对误差不超过2%,且每万次迭代后Loss都有明显下降。
版权归原作者 Annual Mercury 所有, 如有侵权,请联系我们删除。