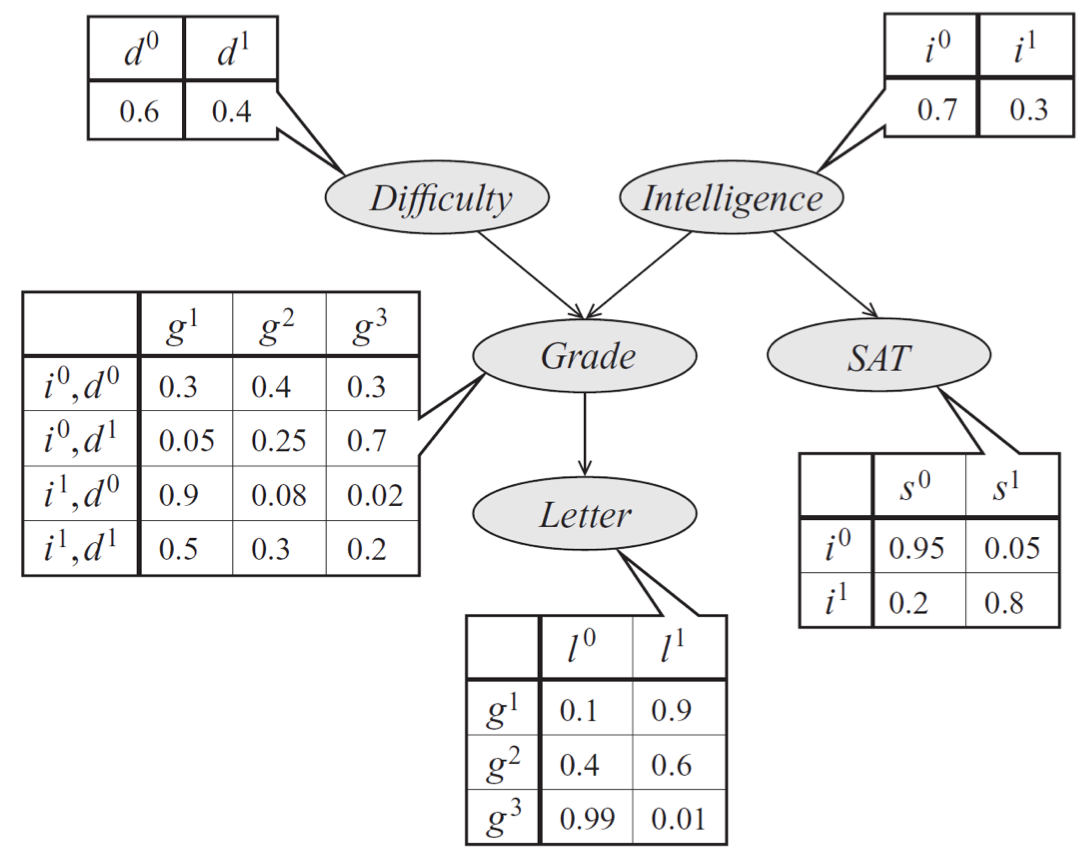
贝叶斯网络的D-separation详解和Python代码实现
D分离(D-Separation)又被称作有向分离,是一种用来判断变量是否条件独立的图形化方法。相比于非图形化方法,D-Separation更加直观且计算简单。
Sober算子边缘检测与Harris角点检测1
此篇文章主要介绍了Sobel算子的底层运算规律,和cv Harris的相关介绍Harris opencv 的对应代码cv2.cornerHarris(src, blockSize, ksize, k[, dst[, borderType]])参数类型src - 输入灰度图像,float32类型blo
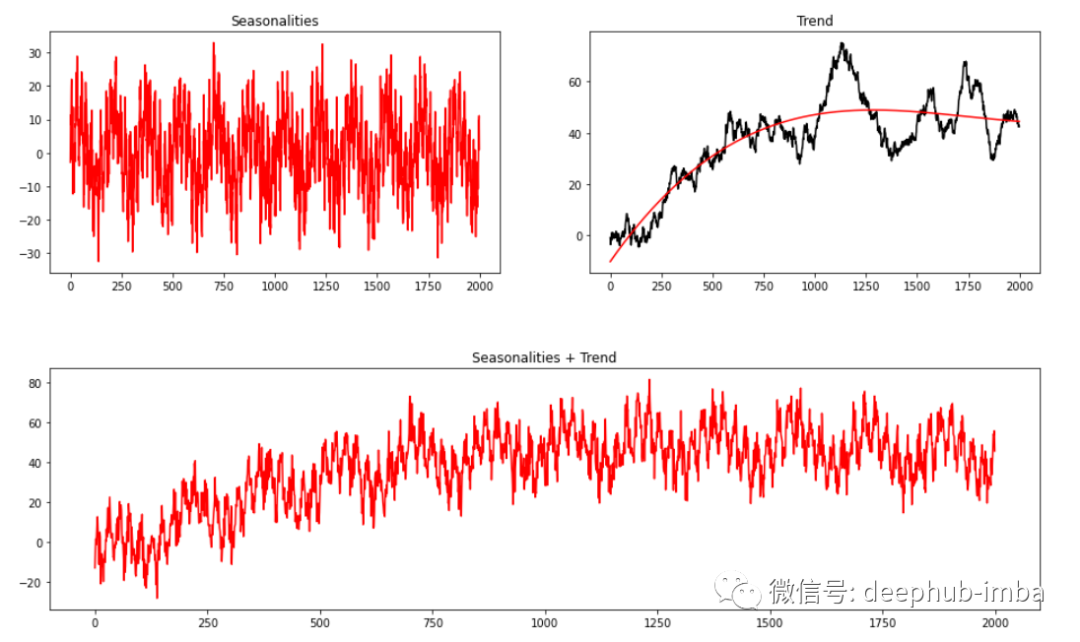
3种时间序列混合建模方法的效果对比和代码实现
本文中将讨论如何建立一个有效的混合预测器,并对常见混合方式进行对比和分析
R语言生成仿真vector向量数据、包括数值向量、字符串向量
R语言生成仿真vector向量数据、包括数值向量、字符串向量

深度特征合成与遗传特征生成,两种自动特征生成策略的比较
特征工程是从现有特征创建新特征的过程,本文中将通过一个示例比较两种自动特征生成的方法:DFS和GFG
聚类分析简述
聚类分析简述聚类分析概述层次聚类K-Means算法DBSCAN算法聚类分析概述聚类分析是一种无监督学习(无监督学习:机器学习中的一种学习方式,没有明确目的的训练方式,无法提前知道结果是什么;数据不需要标签标记),用于对未知类别的样本进行划分将它们按照一定的规则划分成若干个类簇,把相似(相关的)的样本
神经网络中的激活函数与损失函数&深入理解推导softmax交叉熵
介绍神经网络中常用的激活函数和损失函数,主要是介绍softmax交叉熵损失函数,并使用计算图手动推导softmax交叉熵反向传播过程。
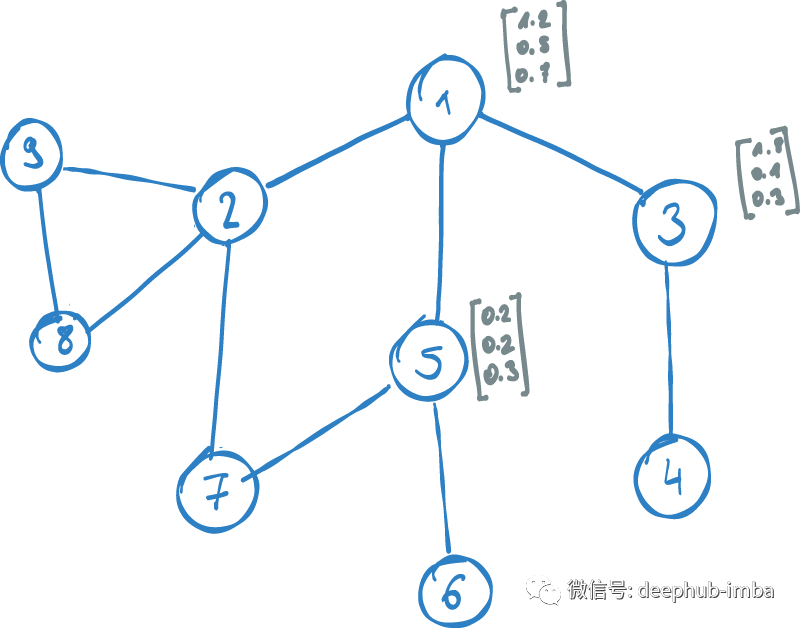
图嵌入中节点如何映射到向量
所有的机器学习算法都需要输入数值型的向量数据,图嵌入通过学习从图的结构化数据到矢量表示的映射来获得节点的嵌入向量。它的最基本优化方法是将具有相似上下文的映射节点靠近嵌入空间。
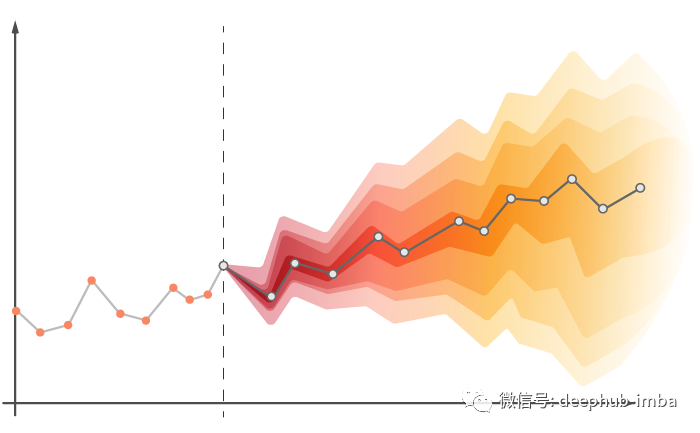
4大类11种常见的时间序列预测方法总结和代码示例
本篇文章将总结时间序列预测方法,并将所有方法分类介绍并提供相应的python代码示例
机器学习(十一) 迁移学习
目录前言1 原理前言 迁移学习在计算机视觉任务和自然语言处理任务中经常使用,这些模型往往需要大数据、复杂的网络结构。如果使用迁移学习,可将预训练的模型作为新模型的起点,这些预训练的模型在开发神经网络的时候已经在大数据集上训练好、模型设计也比较好,这样的模型通用性也比较好。如果要解决的问题与这些模型
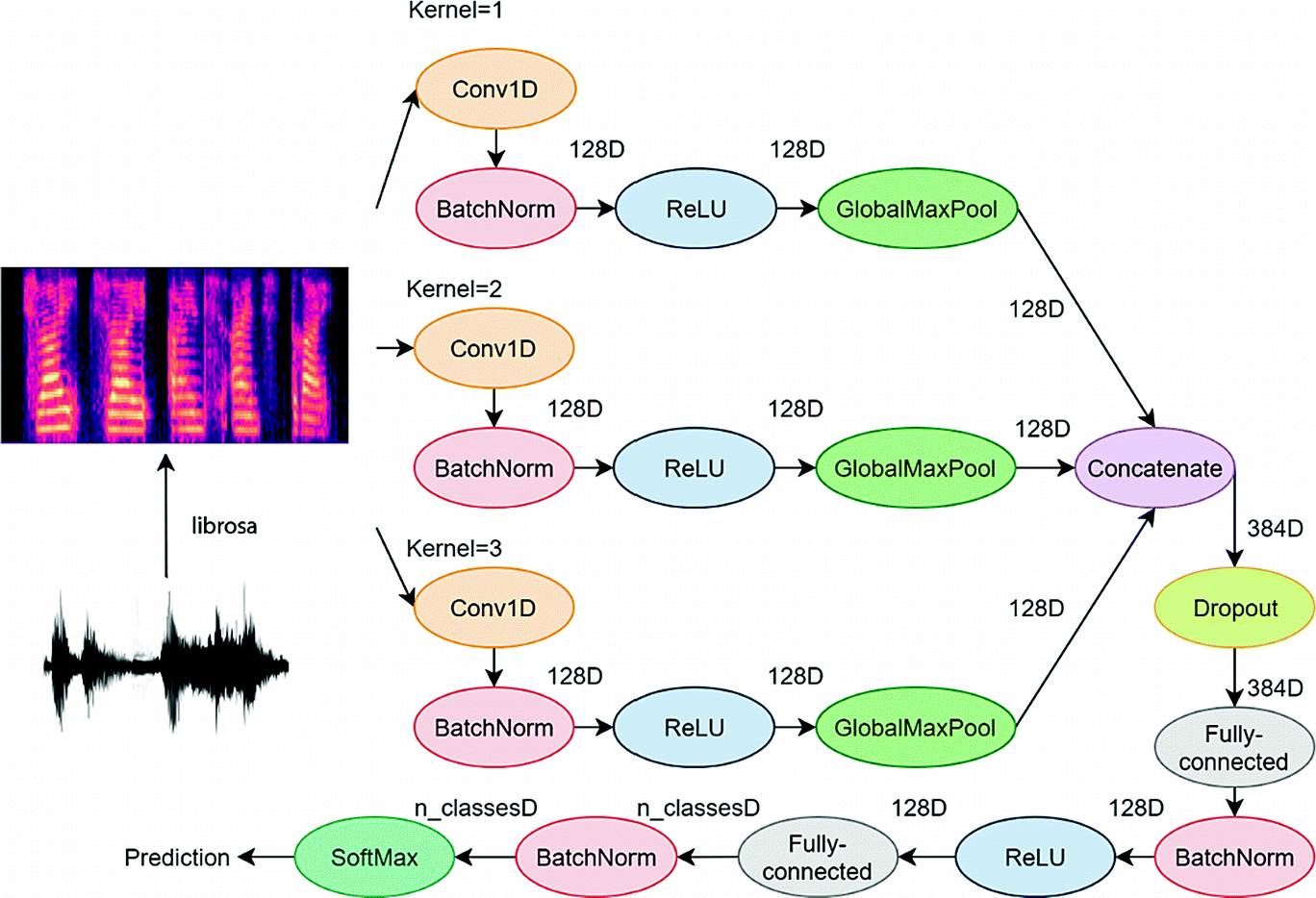
音频数据建模全流程代码示例:通过讲话人的声音进行年龄预测
从EDA、音频预处理到特征工程和数据建模的完整源代码演示
如何保存sklearn训练得到的模型?看这一篇就够了
目录前言一、安装joblib参考前言一、安装joblib可以使用pip命令进行安装:pip install joblib对于conda用户,可以考虑使用conda命令:conda install joblib参考[1] 官方文档
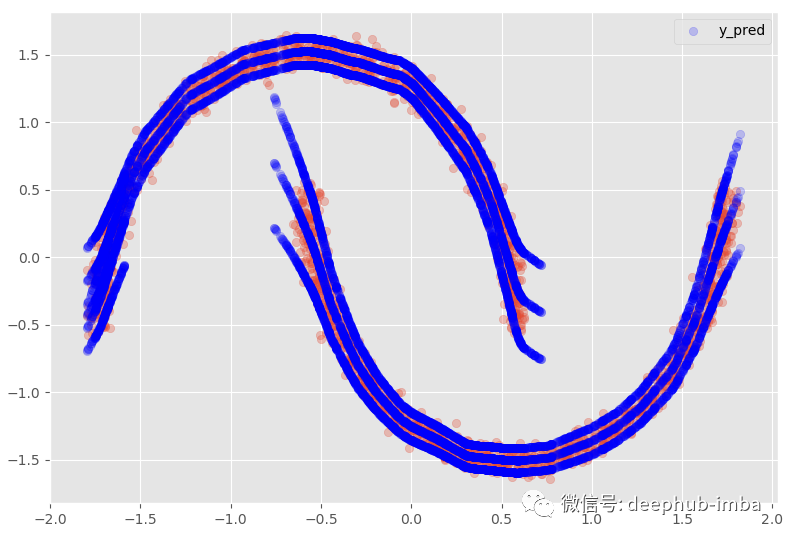
混合密度网络(MDN)进行多元回归详解和代码示例
在本文中,首先简要解释一下 混合密度网络 MDN (Mixture Density Network)是什么,然后将使用Python 代码构建 MDN 模型,最后使用构建好的模型进行多元回归并测试效果。
R语言sd函数计算数值标准差实战(Standard Deviation)
R语言sd函数计算数值标准差实战(Standard Deviation)目录R语言sd函数计算数值标准差实战(Standard Deviation)#基本语法#sd计算标准差#sd计算标准差数值包含NA的情况#sd函数应用于dataframe实战#基本语法sd(x)#sd计算标准差x <- c
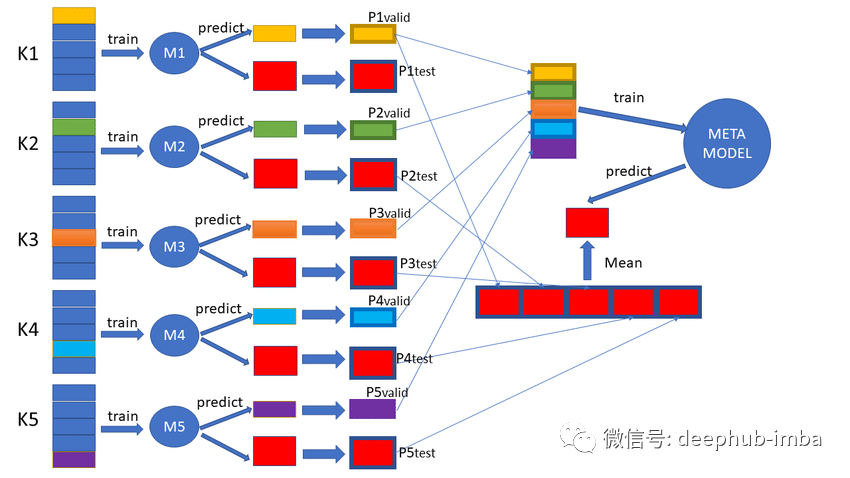
使用折外预测(oof)评估模型的泛化性能和构建集成模型
折外预测在机器学习中发挥着重要作用,可以提高模型的泛化性能。
Deep Interest Evolution Network(DIEN)专题3:代码解析之模型训练和模型结构
import numpyfrom data_iterator import DataIteratorimport tensorflow as tffrom model import *import timeimport randomimport sysfrom utils import *EMBED
基于BP神经网络使用开盘价、最高价、最低价预测收盘价
以下是本文所用数据~~~一、直接上手撸代码import pandas as pdimport numpy as npimport mathdata = pd.read_excel('上证指数.xls')data = np.array(data.iloc[3:-1,1:])e = 1ita = 0.0
机器学习分类算法之LightGBM(梯度提升框架)
目录走进LightGBM什么是LightGBM?XGBoost的缺点LightGBM的优化LightGBM的基本原理Histogram 算法直方图加速 LightGBM并行优化代码实践参数详解 代码实操最优模型及参数(数据集1000)模型调参每文一语走进LightGBM什么是LightGBM?在上

集成学习中的软投票和硬投票机制详解和代码实现
集成方法是将两个或多个单独的机器学习算法的结果结合在一起,并试图产生比任何单个算法都准确的结果
python机器学习之流水线
流水线把数据挖掘过程的每个步骤保存在工作流中。在数据挖掘过程中使用流水线,可以大大降低代码及操作的复杂度,优化流程结构,可以有效减少常见问题的发生。流水线通过 Pipeline() 来实例化,需要传入的属性是一连串数据挖掘的步骤,其中前几个是转换器,最后一个必须是估计器。以经典的鸢尾数据为例,通过以



