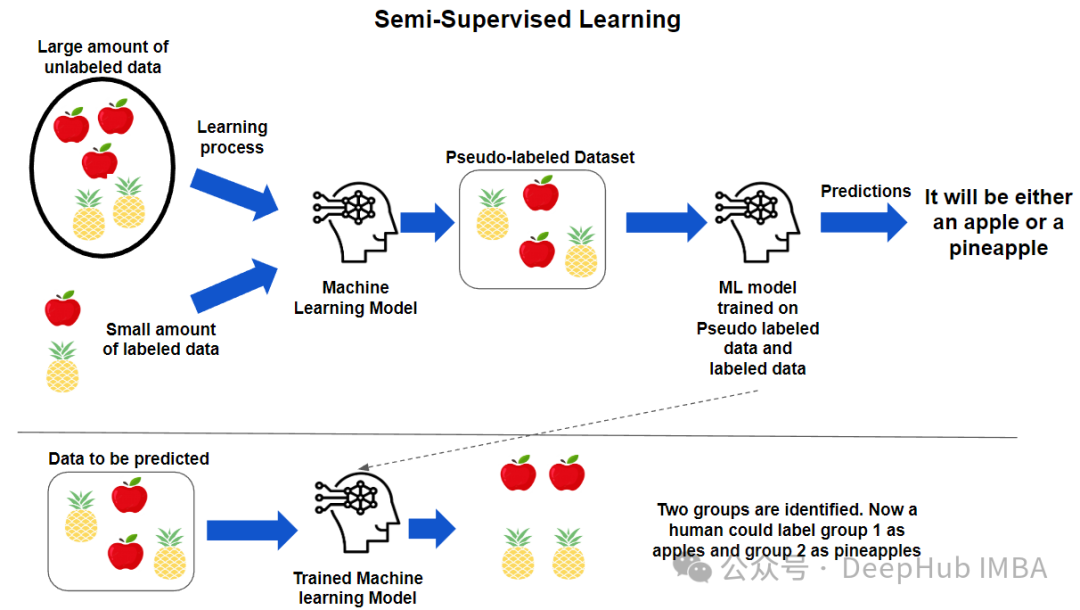
利用未标记数据的半监督学习在模型训练中的效果评估
本文将介绍三种适用于不同类型数据和任务的半监督学习方法。我们还将在一个实际数据集上评估这些方法的性能,并与仅使用标记数据的基准进行比较。
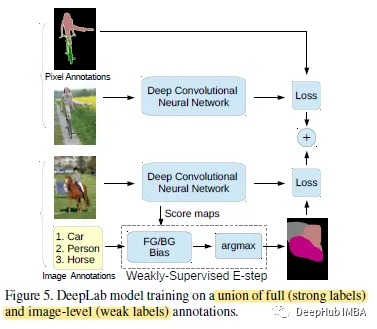
用于语义图像分割的弱监督和半监督学习:弱监督期望最大化方法
这篇论文只有图像级标签或边界框标签作为弱/半监督学习的输入。使用期望最大化(EM)方法,用于弱/半监督下的语义分割模型训练。

sklearn 中的两个半监督标签传播算法 LabelPropagation和LabelSpreading
标签传播算法是一种半监督机器学习算法,它将标签分配给以前未标记的数据点。要在机器学习中使用这种算法,只有一小部分示例具有标签或分类。在算法的建模、拟合和预测过程中,这些标签被传播到未标记的数据点。
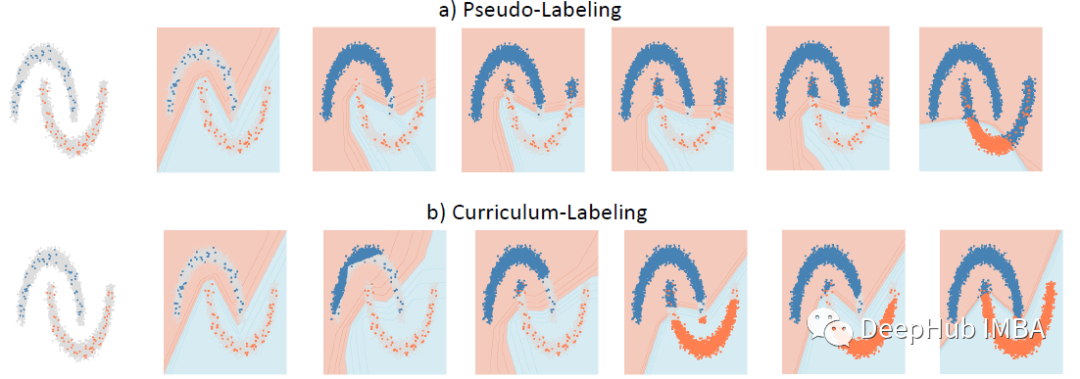
Curriculum Labeling:重新审视半监督学习的伪标签
Curriculum Labeling (CL),在每个自训练周期之前重新启动模型参数,优于伪标签 (PL)
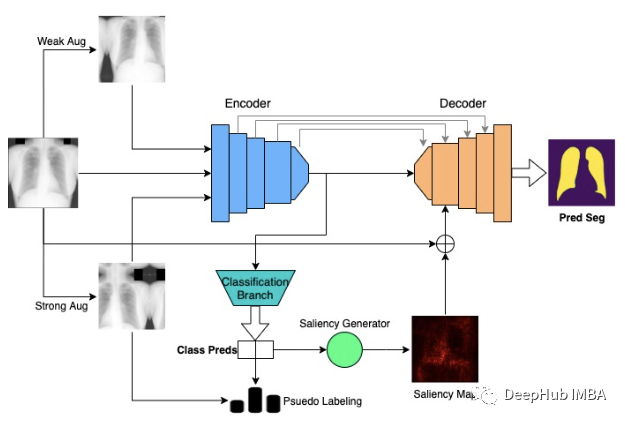
Multimix:从医学图像中进行的少量监督,可解释的多任务学习
在这篇文章中,我们解释了一个可用于联合学习分类和分割任务的新的稀疏监督多任务学习模型MultiMix。该论文使用四种不同的胸部x射线数据集进行了广泛的实验,证明了MultiMix在域内和跨域评估中的有效性。
【持续更新】关于SafeU的安装说明
目录一、写在前面二、SafeU的安装三、魔改源码3.1 `Experiments.py` 的修改3.2 `datasets\base.py` 的修改3.3 `classification\LPA.py` 的修改四、写在最后一、写在前面安全半监督学习(S3L)是目前较为新的一个领域,Python 中有
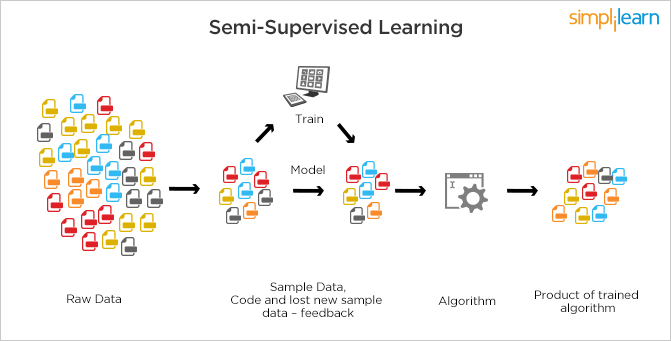
计算机视觉的半监督模型:Noisy student, π-Model和Temporal Ensembling
今天我将讨论一些在过去十年中出现的主要的半监督学习模型。
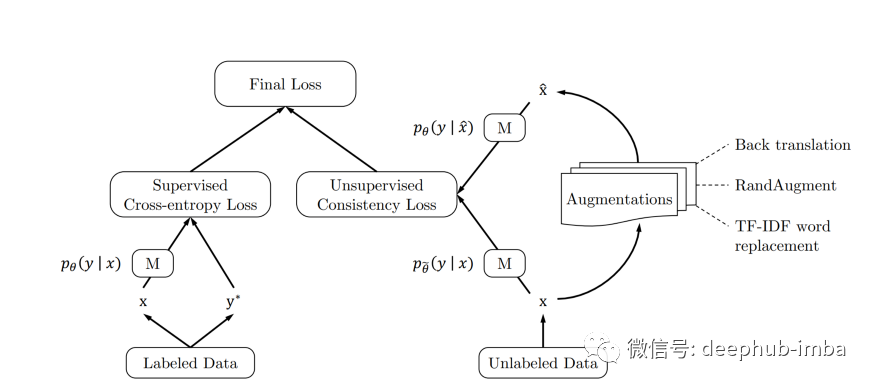
Self-Training:用半监督的方式对任何有监督分类算法进行训练
本文将对Self-Training的流程做一个详细的介绍并使用Python 和Sklearn 实现一个完整的Self-Training示例。



