英伟达的AI霸主地位会持久吗?
目前英伟达因其 GPU 芯片在 AI 革命中扮演着核心角色,使其成为AI时代最赚钱的公司。本文作者Pete Warden总结了铸就英伟达 AI 霸主地位的四点优势:几乎无人运行大规模机器学习应用;英伟达的替代品都很糟糕;研究人员掌握着硬件采购的风向舵;训练时延的影响。随着 AI 技术的发展,Pete
GPU架构与计算入门指南
大多数工程师对CPU和顺序编程都十分熟悉,这是因为自从他们开始编写CPU代码以来,就与之密切接触。然而,对于GPU的内部工作原理及其独特之处,他们的了解则相对较少。过去十年,由于GPU在深度学习中得到广泛应用而变得极为重要。因此,每位软件工程师都有必要了解其基本工作原理。本文旨在为读者提供这方面的背
Docker【部署 05】docker使用tensorflow-gpu安装及调用GPU踩坑记录
docker使用tensorflow-gpu安装及调用GPU踩坑记录
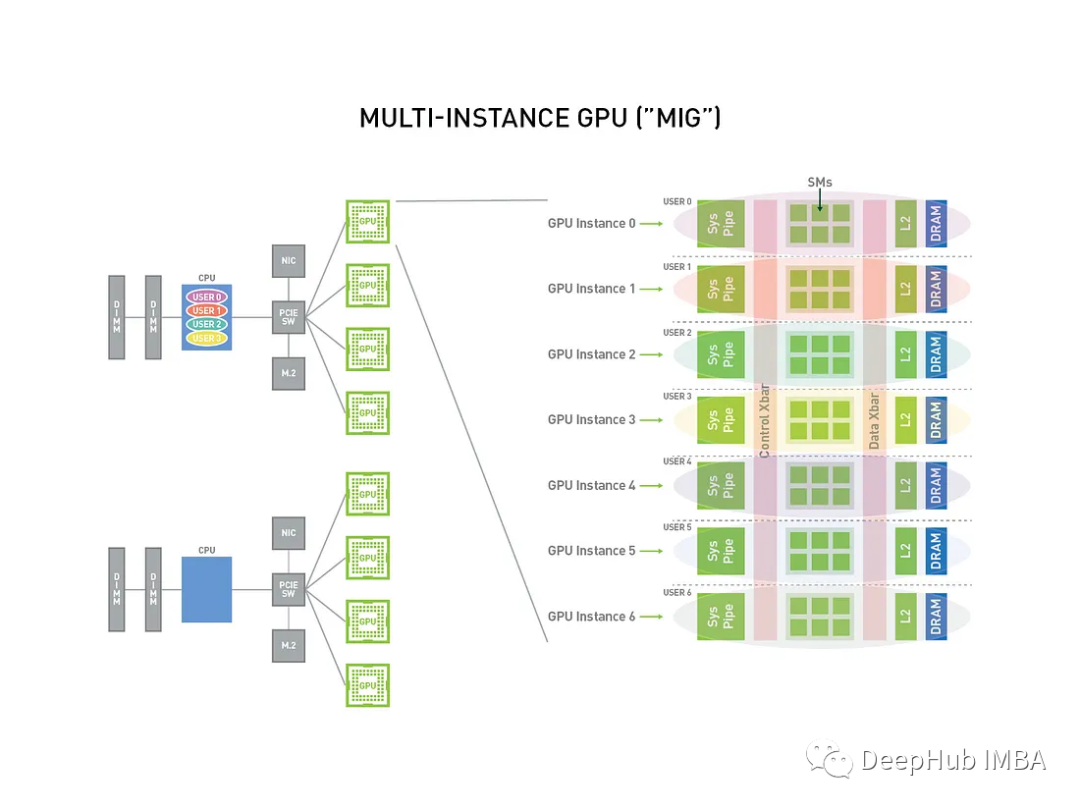
GPU 虚拟化技术MIG简介和安装使用教程
使用多实例GPU (MIG/Multi-Instance GPU)可以将强大的显卡分成更小的部分,每个部分都有自己的工作,这样单张显卡可以同时运行不同的任务。本文将对其进行简单介绍并且提供安装和使用的示例。
Ubuntu 20.04 实时查看GPU使用情况
使用两种方法,实时查看 GPU 使用情况1. nvidia-smi使用终端命令 nvidia-smi 查看显卡信息如果你想实时检测显卡使用情况,添加 watch -n 即可watch -n 4 nvidia-smi其中,4 是指 4 秒刷新一次终端,可以根据自己的需求设置2.gpustat安装过程很
ARM和X86、X86和X64、Intel和AMD、CPU和GPU介绍
ARM和X86、X86和X64、Intel和AMD、CPU和GPU
最新NVIDIA英伟达GPU显卡算力表
随着深度学习的火热, 显卡也变得越来越重要. 而我们在安装各种各样的适配显卡的软件工具时, 都会提到一个显卡算力的概念.

计算GMAC和GFLOPS
GMAC 代表“Giga Multiply-Add Operations per Second”(每秒千兆乘法累加运算),是用于衡量深度学习模型计算效率的指标。它表示每秒在模型中执行的乘法累加运算的数量,以每秒十亿 (giga) 表示。
Ubuntu20.04下安装显卡驱动
ubuntu20.04+Geforce 960M 显卡驱动安装
【Windows安装cuda与Gpu版本的pytorch】
Windows下安装cuda、Gpu版的Pytorch
Python使用更相减损术计算两个整数的最大公约数
更相减损术是《九章算术》中给出的一种用于约分的方法,也可以用来计算最大公约数,其步骤为:1)如果两个整数都是偶数,就使用2约简,直到两个整数不再都是偶数,然后执行第2步。如果两个整数不都是...
A5000 VS 3090,谁更强?
3090的单精度性能高于A5000,但在半精度和混合精度训练中,A5000的性价比又不输3090,甚至更为突出。
编程的终结;展望2023年AI系统方向;AI的下一个阶段
1.OpenAI掌门人Sam Altman:AI的下一个发展阶段各种AI工具已显现出巨大的日常应用潜力,可以实现人类的各种想法,改善人类的工作方式,比如由Stability.ai发布的开源Stable Diffusion模型,Microsoft和OpenAI联合打造的AI编程工具Copilot,Op

为深度学习选择最好的GPU
加快训练速度,更快的迭代模型
从头开始进行CUDA编程:原子指令和互斥锁
本文是本系列的最后一部分,我们将讨论原子指令,它将允许我们从多个线程中安全地操作同一内存。我们还将学习如何利用这些操作来创建互斥锁
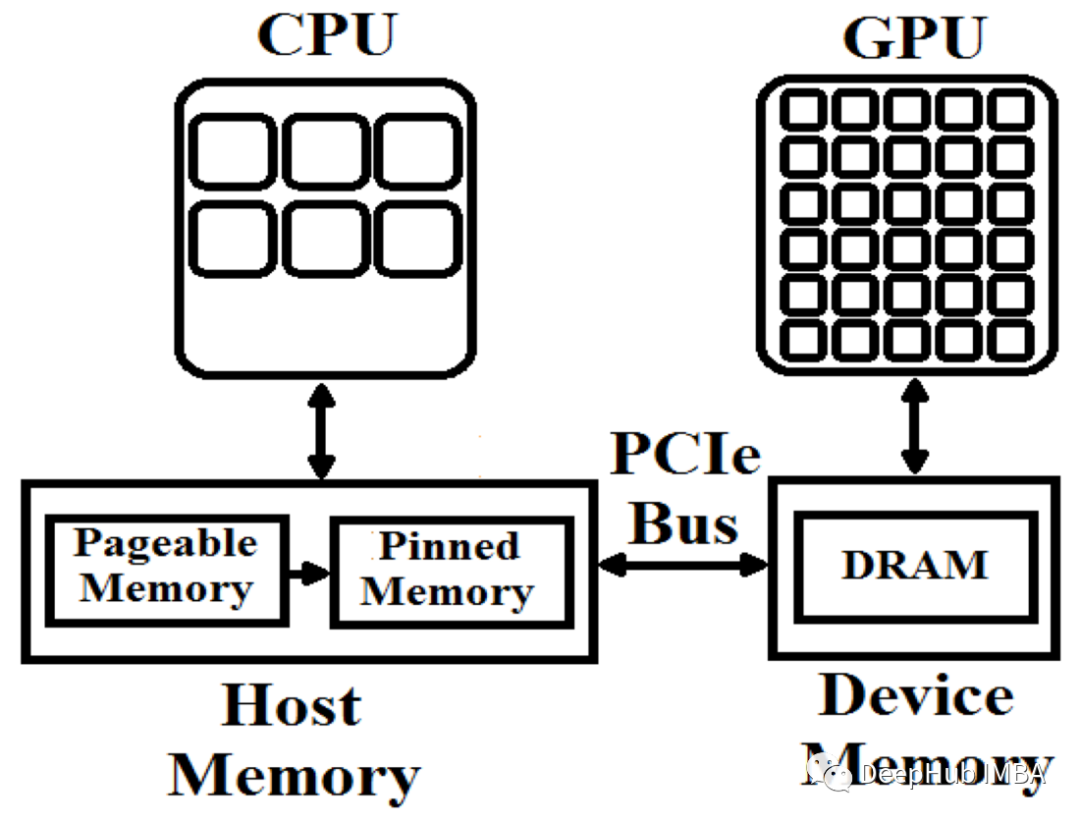
从头开始进行CUDA编程:流和事件
为了提高我们的并行处理能力,本文介绍CUDA事件和如何使用它们
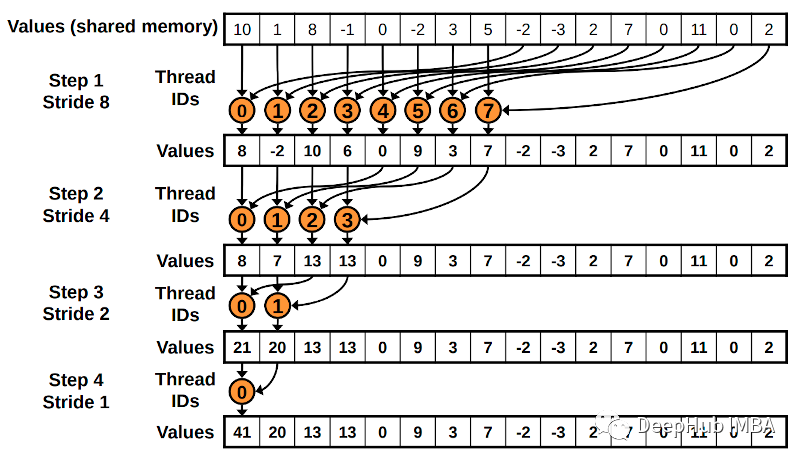
从头开始进行CUDA编程:线程间协作的常见技术
在本篇文章我们将介绍一些允许线程在计算中协作的常见技术。
NVIDIA VPI架构解析
VPI 是一个软件库,提供了一系列计算机视觉和图像处理算法,可以在各种硬件加速器中无缝执行。这些加速器称为后端。VPI 的目标是为计算后端提供统一的接口,同时保持高性能。它通过暴露底层硬件及其操作的数据的薄而有效的软件抽象来实现这一点。此图说明了 VPI 的体系结构:API 遵循在初始化阶段进行对象
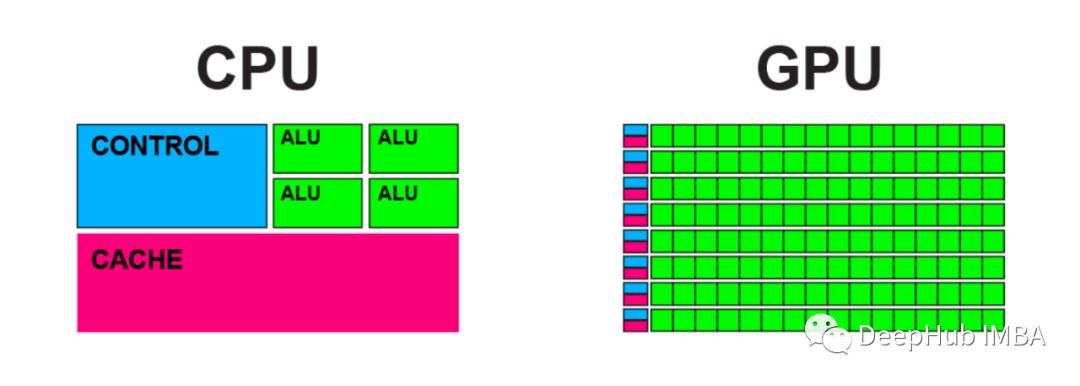
比较CPU和GPU中的矩阵计算
GPU 计算与 CPU 相比能够快多少?在本文中,我将使用 Python 和 PyTorch 线性变换函数对其进行测试。
【31】GPU(下):为什么深度学习需要使用GPU?
GPU发展历史:1.加速卡(顶点处理仍在CPU完成,图像渲染受制于CPU的性能);2.带有顶点处理功能的显卡:NVidia推出GeForce 256 显卡;3.可编程管线(Programable Function Pipeline)的引入:2001年的Direct3D 8.0【微软第一次引入】;4.
- 1
- 2



