大模型训练的硬件基础:GPU内存层级、分块与并行策略
这篇文章从 GPU 架构讲到并行策略,涉及的是把模型从玩具规模拉到生产规模所必须面对的工程问题。

Scikit-Learn 1.8引入 Array API,支持 PyTorch 与 CuPy 张量的原生 GPU 加速
Scikit-Learn 1.8.0 更新引入了实验性的 Array API 支持。这意味着 CuPy 数组或 PyTorch 张量现在可以直接在 Scikit-Learn 的部分组件中直接使用了
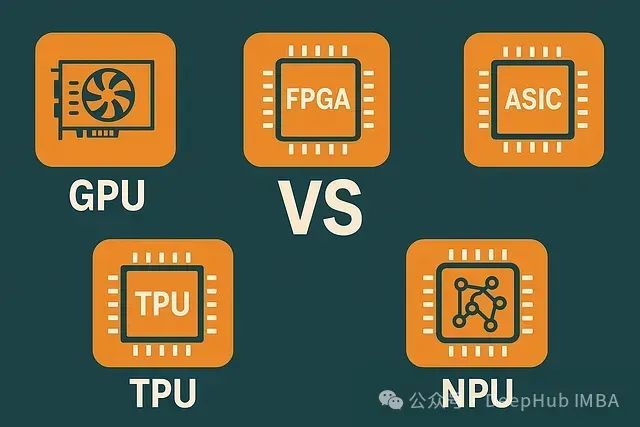
计算加速技术比较分析:GPU、FPGA、ASIC、TPU与NPU的技术特性、应用场景及产业生态
本文将深入剖析五类主要计算加速器——GPU、FPGA、ASIC、TPU和NPU,从技术架构、性能特点、应用领域到产业生态进行系统化比较,并分析在不同应用场景下各类加速器的适用性。
AI智算-正式上架GPU资源监控概览 Grafana Dashboard
AI智算-GPU资源监控概览-20241127适用于AI智算场景中监控NVIDIA GPU资源概览,依赖组件: dcgm-exporter:3.3.0-3.2.0-ubuntu22.04、prometheus:v2.39.1、grafana:10.3.3
哪家云服务器好跑AI?瞄准AutoDL(附NVIDIA GPU 算力排名表)
AutoDL #GPU #租显卡最近本地GPU显存告急,需要搬迁到云服务器,既然选就得选个稳定且性价比高的,毕竟这个活是真烧钱呐。
手把手教你用摩尔线程 GPU 运行 AI
学习本课程后,您将熟悉linux及docker使用操作,掌握torch_musa适配方法,在摩尔线程GPU上跑通Github代码,掌握如何利用摩尔线程 GPU 运行各类 AI 任务。学习本课程后,学习者将熟悉linux及docker使用操作,掌握torch_musa适配方法,在摩尔线程GPU上跑通G
NVidia 的 gpu 开源 Linux Kernel Module Driver 编译 安装 使用
按照nv官方步骤,先执行step1的安装。
GPU 英伟达GPU架构回顾
1999 年,英伟达发明了 GPU(graphics processing unit),本节将介绍英伟达 GPU 从 Fermi 到 Blackwell 共 9 代架构,时间跨度从 2010 年至 2024 年,具体包括费米(Feimi)、开普勒(Kepler)、麦克斯韦(Maxwell)、帕斯卡(
最全面NVIDIA 全系GPU规格及特性对比(含应用场景)
本文主要整理了NVIDIA全系GPU&显卡规格参数及特性对比,应用场景等
通用图形处理器设计GPGPU基础与架构(一)
GPGPU(GeneralPurpose GraphicsProcessingUnit,通用图形处理器)脱胎于GPU(Graphics ProcessingUnit,图形处理器)。GPGPU由于其强大的运算能力和高度灵活的可编程性,已经成为深度学习训练和推理任务最重要的计算平台。这主要得益于GPGP
计算思维:串行、并行、分布式云计算、GPU
计算效率是计算机科学中的重要主题,不同的计算模式和架构设计适用于不同的场景。串行计算适用于小规模任务,而并行计算适用于大规模任务。分布式云计算适用于海量数据处理,GPU 批处理适用于深度学习和计算密集型任务。掌控每一种计算架构与思维方式是提高计算效率和性能的关键,也是计算机工程师的必备技能。在实际应
NVIDIA 全面转向开源 GPU 内核模块
为简化起见,我们以表格形式压缩了软件包管理器建议。驱动程序版本 560 和 CUDA Toolkit 12.6 之后的所有版本都将使用这些打包约定。
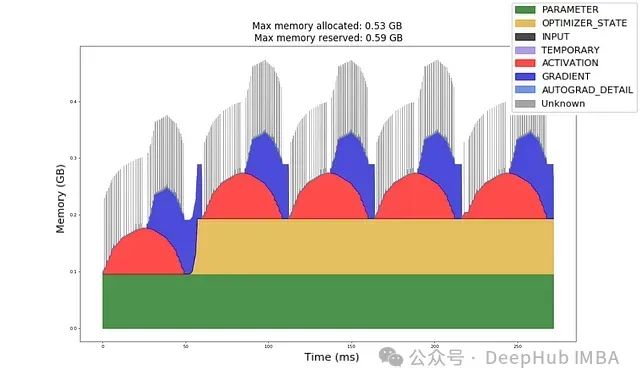
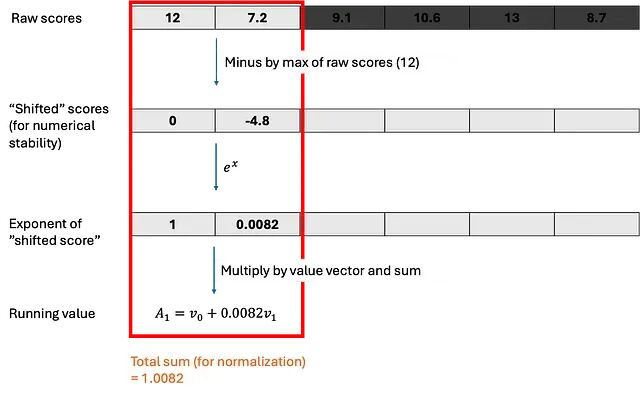
深入理解GPU内存分配:机器学习工程师的实用指南与实验
给定一个模型架构、数据类型、输入形状和优化器,你能否计算出前向传播和反向传播所需的GPU内存量?
智算中心基石-AI算力池化
综述,AI算力池化技术作为智算中心的基石,具有重要意义。智算中心是基于最新人工智能理论,采用领先的人工智能计算架构,提供人工智能应用所需算力服务、数据服务和算法服务的公共算力新型基础设施,其通过算力的生产、聚合、调度和释放,高效支撑数据开放共享、智能生态建设、产业创新聚集,能够有力促进AI产业化、产
高校建设AI算力平台方案探索
但随着硬件采购受限,且一般的IaaS平台对算力管理调度、尤其是异构算力的管理和使用能力有限,多以直通方式为主,现有的资源提供模式的弊端就会突显出来:AI算力不能在各个任务之间灵活切换,使资源使用率不理想,也增加了运维人员的工作量。通过OrionX的跨机聚合能力,可以快速方便的提供多卡的运行环境,提升
ubuntu下如何查看显卡及显卡驱动
该版本号并不是你已经安装了该版本的 CUDA 的意思,而是说此显卡最大支持的CUDA版本号。nvidia-driver-535 - distro non-free recommended 这个即推荐的。首先我们需要看看显卡硬件有没正确安装到计算机,我们可以通过命令。当然,如果没安装显卡驱动,则需要安
Linux篇之在Centos环境下搭建Nvidia显卡驱动
搭建Nvidia显卡驱动
解决ubuntu 22.04新内核6.5.0-15无法编译NVIDIA显卡驱动
这里的新内核应该包括6.5.*系列的。
生成式 AI 系统是否需要 GPU?
人们对用于生成式人工智能部署的 GPU 非常感兴趣,并且有一些充分的理由。然而,在某些情况下,它们过于杀伤力而且太昂贵。
AI算力资源池化:确保AI应用的业务连续性
即使资源池内的节点或AI算力设备出现故障,也能快速为AI任务分配新的资源,以便快速恢复业务,保障AI业务运行的连续性。通过监控AI业务的外部访问压力,动态扩展AI业务容器数量,OrionX AI算力资源池也能为每个AI业务实例匹配更多数量的虚拟算力资源,以便应对外部对AI业务的访问压力,从而提高业务
- 1
- 2



